Elasticsearch作为召回组件
概述
推荐场景下,召回起到快速筛选内容的作用,因此筛选内容的时间非常重要,尽可能在短时间将用户感兴趣的内容召回回来,一般情况下不要求有序,因为后面还会有精排的流程。可以实现两种召回方式,分别为实时召回和离线召回。本文主要介绍采用 Elasticsearch 作为内容的存储的召回层的设计。
实时召回
以给 user 推荐 item 的场景为例。假设存在一个记录了所有 item 特征标签的倒排索引,也就是 ES 的索引。
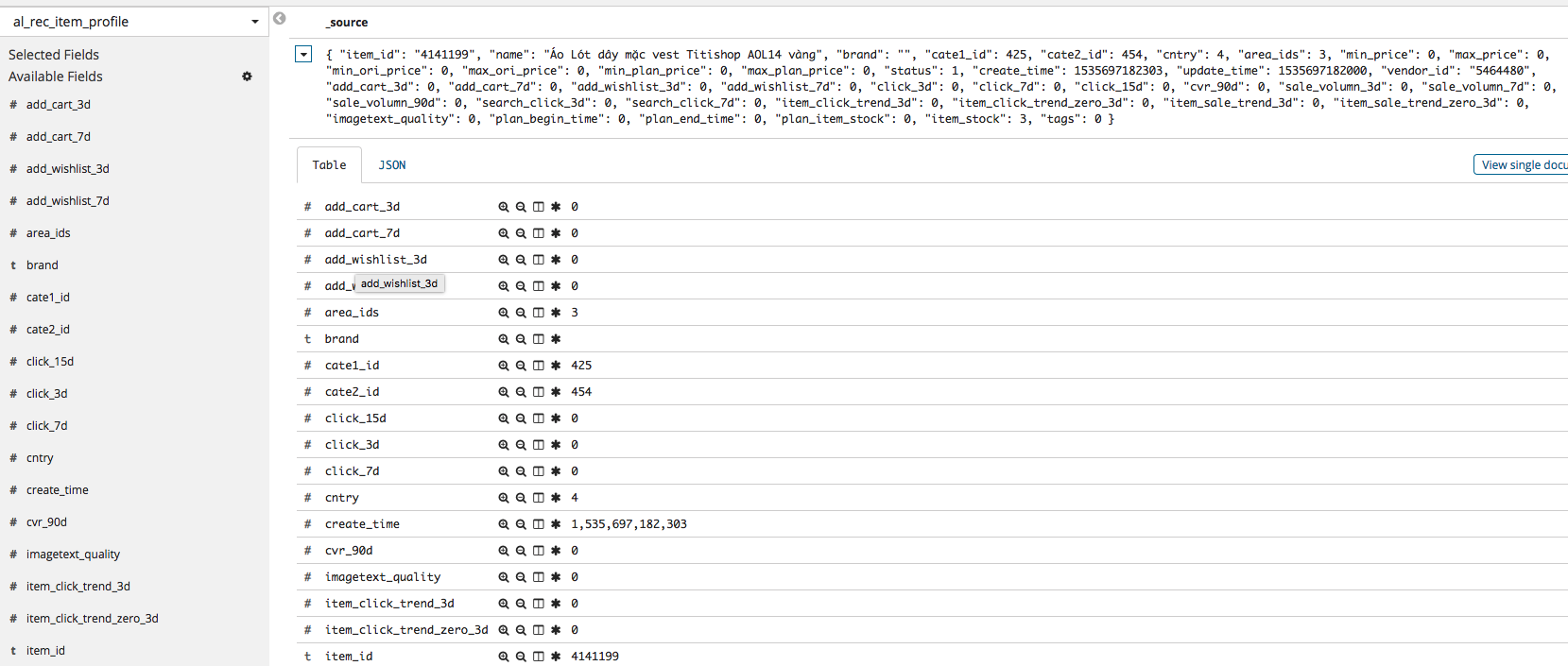
如何理解这个 item id 为4141199的文档呢?ES 中存储的是一个 JSON 文档,可以理解成除了 item_id 字段外,其他都是表示 item 特征的字段,比如说 cntry 为4,cvr_90d 为0等等。
那么基于用户特征/标签去召回 item 的时候,用户的特征标签是如何组织成一条 query 的呢?
|
|
假如通过查询用户的画像,发现用户喜欢 cntry=4 以及 cvr_90d=0 的 item,那么查询的时候 query 可能会组织成以上例子的样子。
为什么叫实时的召回呢?
因为用户的特征是一直在变化的,item 的特征也是一直变化的,假如这一分钟,用户是喜欢 cntry=4 以及 cvr_90d=0 的 item,下一分钟就变成 cntry=1 以及 cvr_90d=1 的 item。又或者 item 的这些特征/标签也在动态变化。那么就需要实时更新这个召回的 query 了。同时,新 item 流入到画像中,那么新的 item 也应该被召回出来。
这种召回的好处显而易见,就是相对比较实时,user 和 item 的画像变化可以实时的反应到召回结果中,坏处就是当查询 ES 的 query 太长了太复杂了,召回的性能也许得不到保证。
离线召回
还是以给 user 推荐 item 的场景为例。有一种常见的推荐算法叫做协同过滤,大意是可以给相似 user 推荐其他 user 喜欢的内容。
放在推荐系统中,同样可以用 Elasticsearch 来实现,也许需要给 user 的索引增加一个字段,表示通过某种算法,给用户计算出来的一些会被推荐的 item id 的列表。
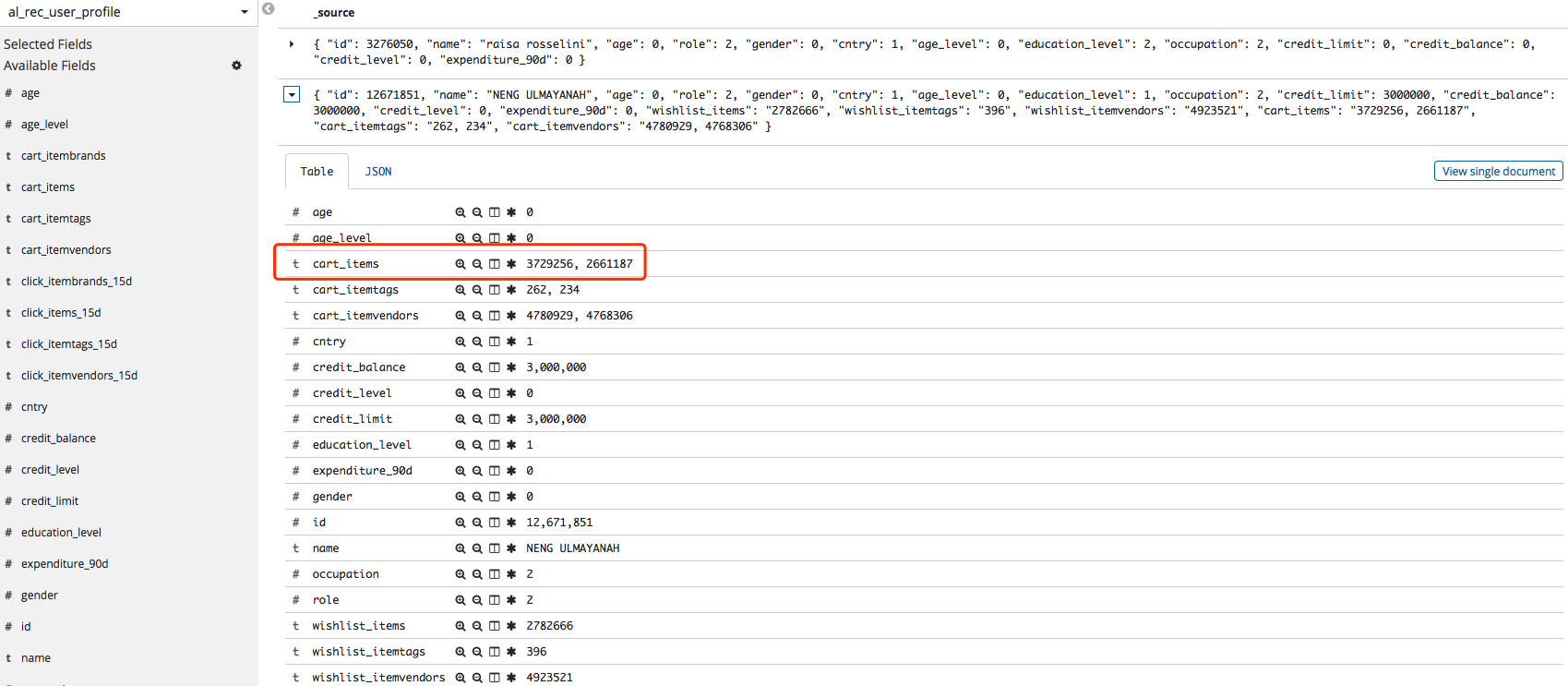
假如通过一种叫 cart_items 的算法(算法名字不重要,仅仅举个例子)给 user id 为12671851的用户,推荐两种 item,分别为3729256, 2661187。那么推荐系统该如何获取这个召回结果呢?
|
|
同样的需要一条 ES 的 query,表示我只要上述的这个文档,并且过滤其他字段,只剩下 cart_items 字段就好了。
为什么需要这种离线的召回呢?
可能有几种原因,可能是因为推荐算法的计算量非常大,计算时间非常久,很难做到流计算里面,因此提前计算好,那么召回的时间就减少了。离线召回的缺点非常明显,就是推荐结果不够实时,可能今天计算的召回集,用户已经不感兴趣了,优点就是获取数据非常迅速。
总结
推荐系统中的召回,需要实时和离线两种方式进行召回,并且组合成召回集用于后面的精排过程,两种方式各有优缺点,如何权衡,不是拍脑袋来确定的,需要通过大量的线下算法模型的训练和验证,以及线上AB测试的不断迭代测试,从而找到最利于转化率的召回方式。