AB测试方案
概述
利用 uuid 将用户切分为多个 bucket,每个 bucket 分配不同的策略,非法 id 随机分配,并且添加配置白名单用于测试,可支持不同节点的配置和灰度上线和回滚。
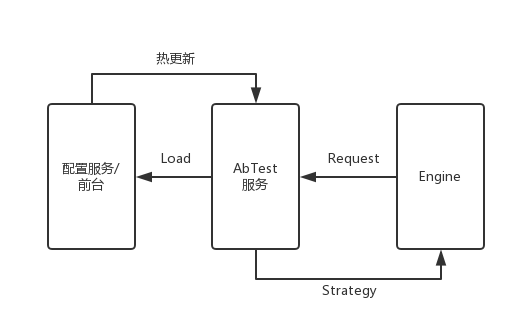
实验的写入和读取
提供前端页面负责给算法同学写入算法 id,节点和实验比例信息,后端基于 ZooKeeper 提供查询和写入的接口,Engine 启动读取 ZooKeeper 节点信息,并且监听相应 ZK 节点的实验信息的更改,可以实现热更新。
实现逻辑的介绍
一般实验
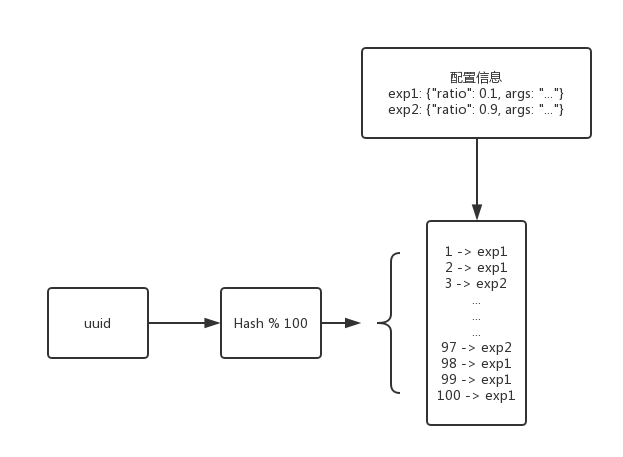
根据实验配置信息,将配置的实验数量,分配在100个 bucket 中,假设某用户的 id 为 runzhliu,计算其 id 值的哈希值,取模,再到这100个 bucket 中获得其实验配置信息(幂等),该用户会按照实验配置的百分比,选中相应的实验配置信息。
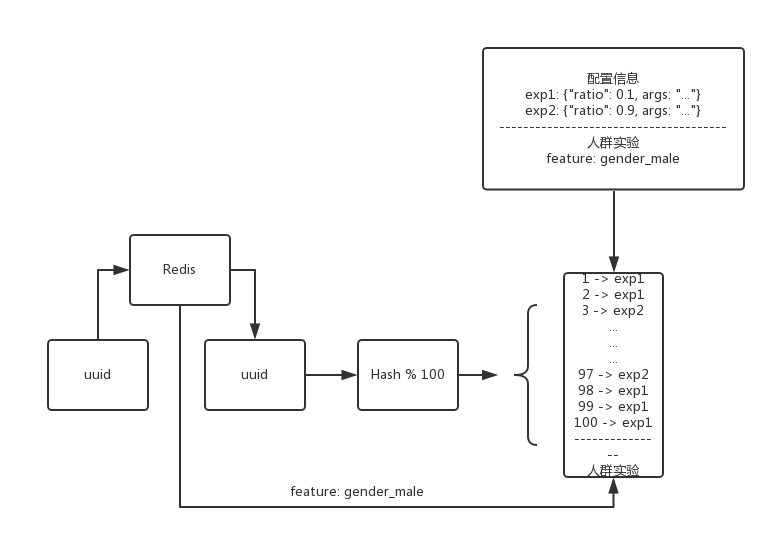
人群实验
当实验场景只针对特定人群特征做实验,比如该实验只是为了观察男性用户的曝光点击率/转化率。实验配置中写入人群实验的信息,Engine 请求的 uuid 中先判断是否人群实验需要的对象,是的话直接走入人群实验的策略,否则依然按照流量进行切分。
白名单
设置白名单只落入指定实验策略,方便算法/产品,线上/线下不同场景进行测试。其余用户均通过流量来切分。
其他
AbTest 服务初始化读取配置信息到内存中,配置前台修改实验信息可以热更新 AbTest 内存中的数据,Engine 请求按照 uuid 分配实验策略。AbTest 提供增加实验和回滚实验两种接口,用增加/回滚操作时间戳来控制实验版本。
如果打点数据正常,在前端收集数据之后,做成报表后,不同实验策略的用户应该是符合实验配置信息预设的比例的。如果出现异常,需要仔细排查是 AbTest 流量切分还是打点数据的问题。
总结
本文主要介绍了如何通过 uuid 来确定做 AB 实验的人群,并且提供了架构实现的技术方案。