概述
近期要对 AlertManager 的接口进行一点改造,完整部署整套 Prometheus + AlertManager 成本有点大,可以考虑用 Helm Chart 部署一套 Kubernetes 的版本,但为了方便调试,还是在本地通过 Docker 来部署一个可用版,方便 Debug。
镜像准备
1
2
|
docker pull prom/prometheus:v2.32.1
docker pull prom/alertmanager:v0.23.0
|
网络准备
因为需要在本地运行两个容器,且两个容器需要互相能否访问,所以这里创建一个 network,这一步是必须的,否则后面可能部署完之后会出现 Prometheus 无法访问到 AlertManager。
1
|
docker network create prom
|
效果如图,记住这个 Subnet。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
# docker network ls
NETWORK ID NAME DRIVER SCOPE
4b3ea669c4a9 bridge bridge local
1559eb7abc2a host host local
bac2ee0f09c0 none null local
47c7aa42e844 prom bridge local
# docker inspect 47c7aa42e844
[
{
"Name": "prom",
"Id": "47c7aa42e844e76e6e06d35d0f0316b2795bb51ec2555ea5784b1ae0e84f9823",
"Created": "2022-01-05T04:43:01.53897626Z",
"Scope": "local",
"Driver": "bridge",
"EnableIPv6": false,
"IPAM": {
"Driver": "default",
"Options": {},
"Config": [
{
"Subnet": "172.18.0.0/16",
"Gateway": "172.18.0.1"
}
]
},
"Internal": false,
"Attachable": false,
"Ingress": false,
"ConfigFrom": {
"Network": ""
},
...
...
|
Prometheus部署
部署首先需要配置文件 prometheus.yml。通过下面命令,进入镜像查看默认的配置文件。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
# docker run --rm -it --entrypoint=sh prom/prometheus:v2.32.1
/prometheus $ cat /etc/prometheus/prometheus.yml
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
- /tmp/rules.yml
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["localhost:9090"]
|
不修改默认的配置,通过下面命令运行 Prometheus 的容器,当然默认的配置文件如上可以看到,并没有配置 AlertManager 的地址,所以后面肯定要拿出来再改的,但先运行起来一个默认的看看效果。
1
|
docker run --name prometheus -p 9090:9090 prom/prometheus
|

AlertManager部署
通过下面的命令运行,效果如下两图。
1
|
docker run --name alertmanager --network prom -p 9093:9093 prom/alertmanager:v0.23.0
|
修改配置
当然按上面的部署方式,目前部署了的 Prometheus 是感知不到 AlertManager 的存在的,因为 Prometheus 里关于 AlertManager 的配置没有配置上去,所以单独修改一下配置文件,这里主要修改的 target 的 ip,因为采用的是自定义网络,还记得前面创建的 Docker 网络吗,172.18.0.1 是网关地址,172.18.0.2 是给 Prometheus 用的,因为他是现部署的,然后 172.18.0.3 就是部署的第二个容器 AlertManger 的 ip 啦,这个是按顺序的。
修改点只有这一处,然后保存到 /tmp 目录下,再执行下面的命令重新运行。
1
2
3
4
5
6
|
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
- 172.18.0.3:9093
|
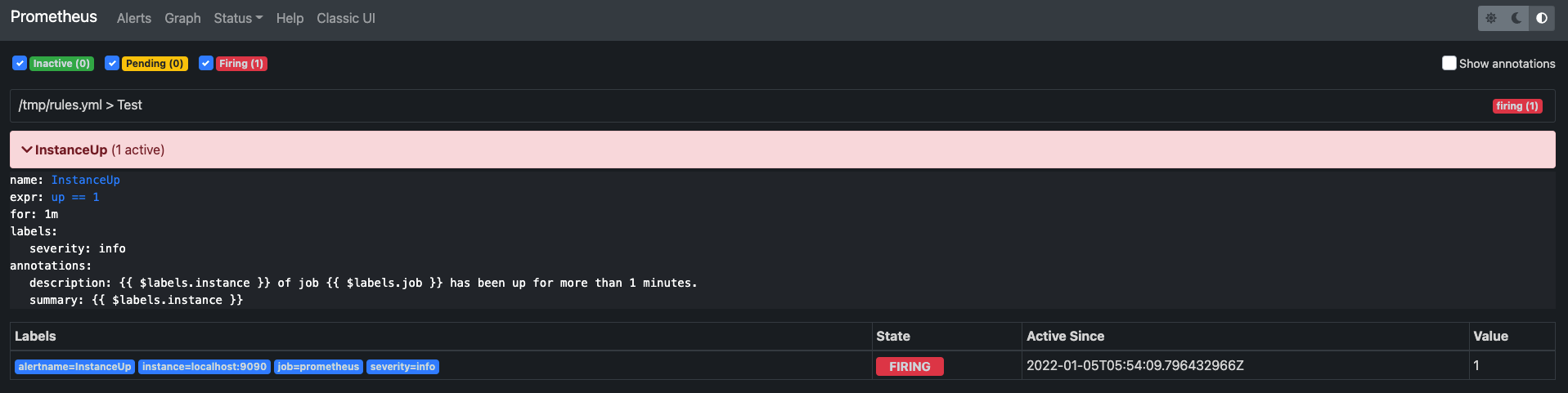
另外还需要提供一个简单的 rules.yml 来作为告警的验证,具体的文件如下。
1
2
3
4
5
6
7
8
9
10
11
|
groups:
- name: Test
rules:
- alert: InstanceUp
expr: up == 1
for: 1m
labels:
severity: info
annotations:
summary: "{{ $labels.instance }}"
description: "{{ $labels.instance }} of job {{ $labels.job }} has been up for more than 1 minutes."
|
1
2
3
4
5
6
7
8
9
10
|
# 运行Prometheus
docker run \
--network prom \
-p 9090:9090 \
-v /tmp/prometheus.yml:/etc/prometheus/prometheus.yml \
-v /tmp/rules.yml:/tmp/rules.yml \
prom/prometheus
# 运行Alertmanger,注意顺序
docker run --network prom -p 9093:9093 prom/alertmanager:v0.23.0
|
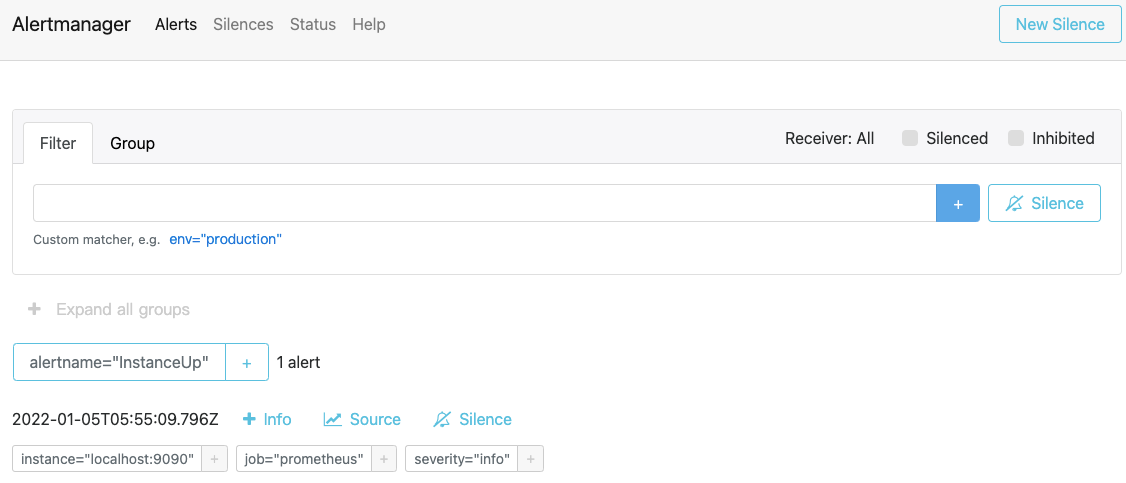
最后的效果
最后可以看到告警已经发到 AlertManager 那边了。
参考资料
- using-docker
- docker-images
警告
本文最后更新于 2018年12月11日,文中内容可能已过时,请谨慎参考。