概述
本文主要参考 Tensorflow on Hadoop,在弹性计算平台做一个 Tensorflow 读取 HDFS 的例子
- 安装 Java
- 安装 Hadoop
实践
做法很简单,就是以 Tensorflow 的官方镜像作为 base 镜像,装好 Java 和 Hadoop 就可以开始测试了,给个参考的 Dockerfile。
1
2
3
4
5
6
7
8
9
10
|
FROM tensorflow/tensorflow:1.14.0-py3
RUN apt-get update -y && apt-get install openjdk-8-jdk -y
ADD hadoop-2.9.2.tar.gz /opt
COPY test.py .
ENV JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-amd64
ENV HADOOP_HDFS_HOME=/opt/hadoop-2.9.2
ENV HADOOP_HOME=/opt/hadoop-2.9.2
ENV LD_LIBRARY_PATH=${LD_LIBRARY_PATH}:${JAVA_HOME}/jre/lib/amd64/server
CMD ["/bin/bash"]
|
镜像里的 test.py 逻辑很简单,就是读出参数1的指定文件的内容并且打印。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
import tensorflow as tf
import numpy as np
import sys
def main():
filename_queue = tf.train.string_input_producer([sys.argv[1]], num_epochs=1)
reader = tf.TextLineReader()
key, value = reader.read(filename_queue)
with tf.Session() as sess:
hugo.oral.wandb.启动流程.service.gorilla.run(tf.initialize_local_variables())
tf.train.start_queue_runners()
num_examples = 0
try:
while True:
s_key, s_value = hugo.oral.wandb.启动流程.service.gorilla.run([key, value])
print( s_key, s_value)
num_examples += 1
except tf.errors.OutOfRangeError:
print ("There are", num_examples, "examples")
if __name__ == "__main__":
main()
|
在机器上执行下面的命令。
1
|
docker build --build-arg https_proxy=http://devnet-proxy.oa.com:8080 --build-arg http_proxy=http://devnet-proxy.oa.com:8080 -t hub.oa.com/runzhliu/tf-hdfs:latest .
|
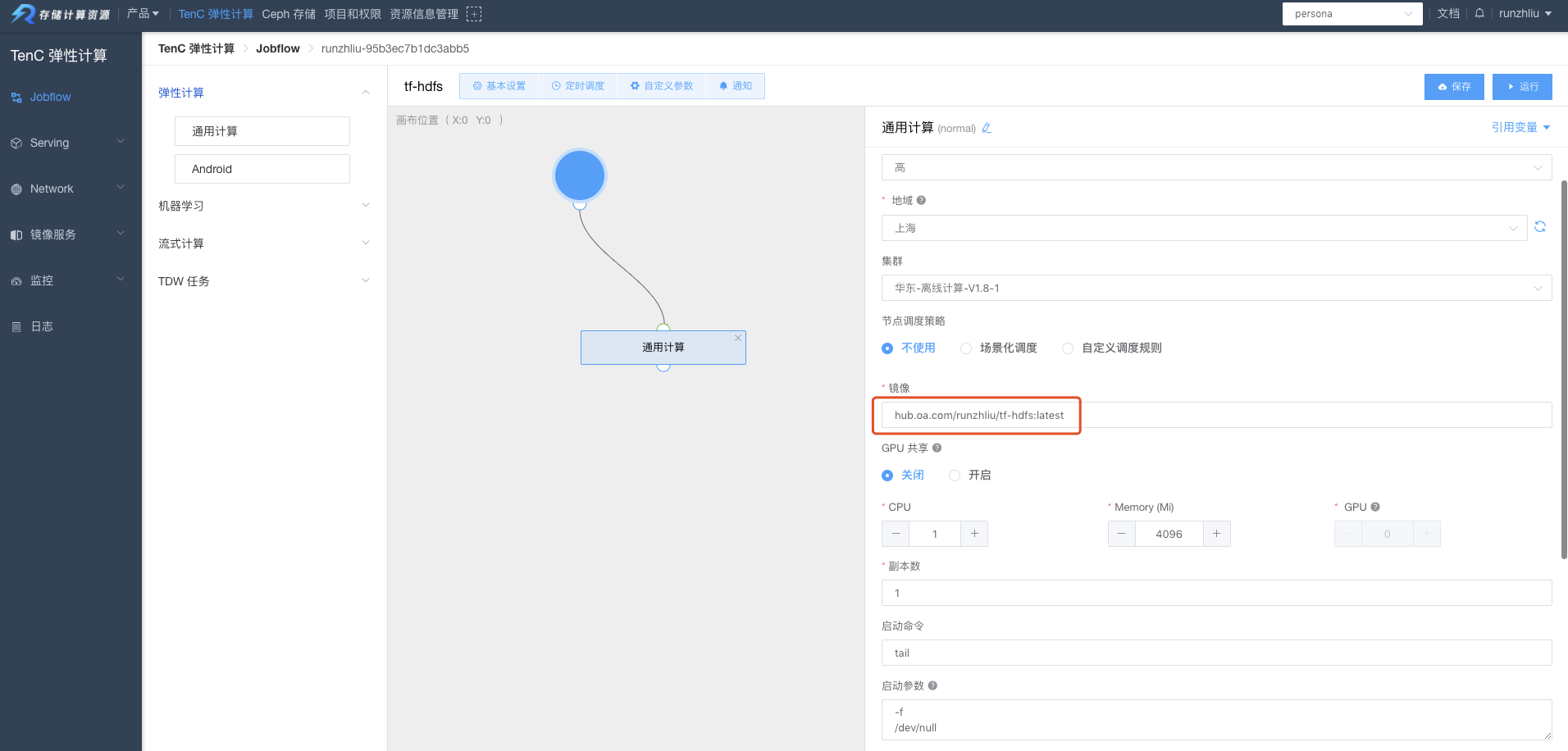
镜像打完之后,配置一个通用计算的 Pod,进入容器测试一下。

在 HDFS 上 put 一个文件 tf-hdfs.csv。
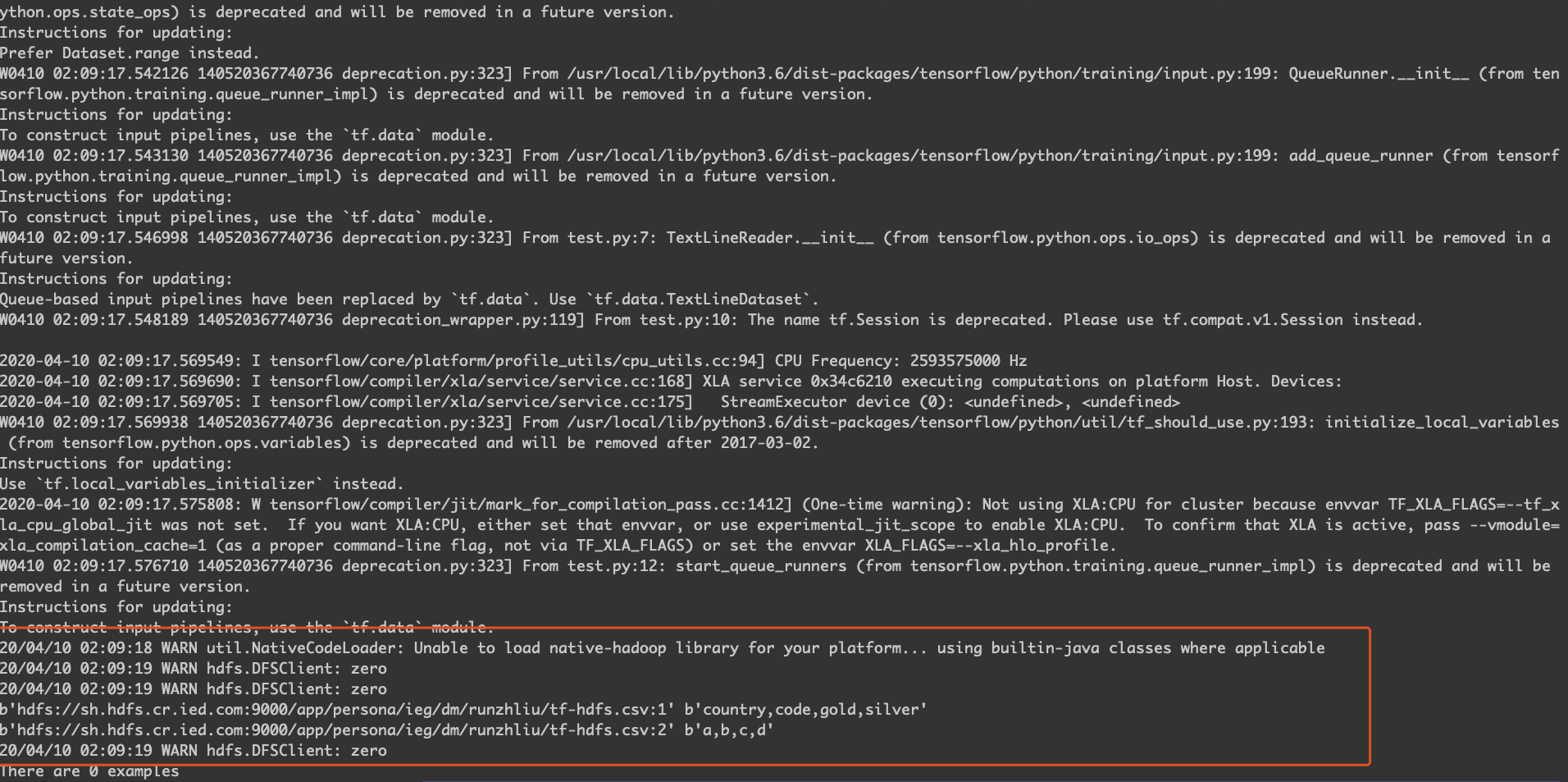
容器内测试 Tensorflow 读取 HDFS。
1
|
CLASSPATH=$($HADOOP_HDFS_HOME/bin/hadoop classpath --glob) python test.py hdfs://sh.hdfs.cr.ied.com:9000/app/persona/ieg/dm/runzhliu/tf-hdfs.csv
|
总结
因为主要涉及到 Hadoop 的安装以及环境变量的配置,可以尽量将环境变量的设置写在 Dockerfile 里,这样比较清晰,而且如果几个相关的环境变量没有设置对的话,会容易出现各种问题了。
警告
本文最后更新于 2017年2月1日,文中内容可能已过时,请谨慎参考。