概述
本文主要讲解一下 Tensorflow 编译 GPU 的流程。
编译Tensorflow
要注意一切编译的前提条件,要编译的 tensorflow 的版本。
- gcc版本
- bazel版本
- openjdk版本
常见问题如下:
- gcc版本太低
- bazel版本太低
这是一个动态链接库的问题 libstd++,通过重新配置新的软链指向合适的动态链接库即可。
`GLIBCXX_3.4.20’ not found
master 与 worker 是管理会话与数据流图的实体
master 组件负责管理分布式会话的生命周期及数据流图执行任务的分配
worker 组件负责管理数据流图的局部图在特定进程、特定设备上的执行
client/master/worker 运行在同一个进程
client 请求图运行
master 驱动图运行
worker 实施图运行
RDMA 通信模块
商用集群: 1Gb/s ~ 10Gb/s 以太网
高性能集群: 40Gb/s ~ 300 Gb/s InfiniBand 等高带宽、低延迟的高端网络
InfiniBand 兼容 TCP/IP,但一般使用 RDMA。
RDMA
- 减少通信过程的内存拷贝
- 降低 CPU 参与通信的指令、缓存和上下文切换
- 提高吞吐和缩短延迟
Tensorflow 要支持 GPU,首先是需要安装 Nvida 的驱动程序,还有一些 CUDA, CUCUDA 等等的软件。过程的复杂,编译过的同学应该都懂,一会是 Tensorflow 的版本问题,一会是 CUDA 的问题,一会又是 GPU 型号的问题。
1
2
3
|
# 查看 GPU 设配
[root@TENCENT64 ~]# lspci | grep -i vga
12:00.0 VGA compatible controller: ASPEED Technology, Inc. ASPEED Graphics Family (rev 30)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
|
# 查看显卡
# nvidia-smi
Sat Aug 31 18:35:57 2019
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 396.26 Driver Version: 396.26 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla P40 Off | 00000000:04:00.0 Off | Off |
| N/A 31C P0 51W / 250W | 22744MiB / 24451MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 1 Tesla P40 Off | 00000000:06:00.0 Off | Off |
| N/A 37C P0 61W / 250W | 2920MiB / 24451MiB | 62% Default |
+-------------------------------+----------------------+----------------------+
| 2 Tesla P40 Off | 00000000:07:00.0 Off | Off |
| N/A 40C P0 178W / 250W | 2918MiB / 24451MiB | 31% Default |
+-------------------------------+----------------------+----------------------+
| 3 Tesla P40 Off | 00000000:08:00.0 Off | Off |
| N/A 24C P8 10W / 250W | 229MiB / 24451MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 4 Tesla P40 Off | 00000000:0C:00.0 Off | Off |
| N/A 23C P8 9W / 250W | 229MiB / 24451MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 5 Tesla P40 Off | 00000000:0D:00.0 Off | Off |
| N/A 48C P0 121W / 250W | 3220MiB / 24451MiB | 89% Default |
+-------------------------------+----------------------+----------------------+
| 6 Tesla P40 Off | 00000000:0E:00.0 Off | Off |
| N/A 27C P8 9W / 250W | 229MiB / 24451MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 7 Tesla P40 Off | 00000000:0F:00.0 Off | Off |
| N/A 27C P8 9W / 250W | 229MiB / 24451MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 0 29447 C nvidia-cuda-mps-server 22732MiB |
| 1 7130 C /usr/local/python 365/bin/python3 2691MiB |
| 1 29447 C nvidia-cuda-mps-server 219MiB |
| 2 29106 C /usr/local/python365/bin/python3 2689MiB |
| 2 29447 C nvidia-cuda-mps-server 219MiB |
| 3 29447 C nvidia-cuda-mps-server 219MiB |
| 4 29447 C nvidia-cuda-mps-server 219MiB |
| 5 20877 C caffe 2991MiB |
| 5 29447 C nvidia-cuda-mps-server 219MiB |
| 6 29447 C nvidia-cuda-mps-server 219MiB |
| 7 29447 C nvidia-cuda-mps-server 219MiB |
+-----------------------------------------------------------------------------+
|
1
2
3
4
5
6
7
8
9
10
11
12
|
# 查看 nvidia 显卡
# lspci | grep -i nvidia
04:00.0 3D controller: NVIDIA Corporation Device 1b38 (rev a1)
06:00.0 3D controller: NVIDIA Corporation Device 1b38 (rev a1)
07:00.0 3D controller: NVIDIA Corporation Device 1b38 (rev a1)
08:00.0 3D controller: NVIDIA Corporation Device 1b38 (rev a1)
0c:00.0 3D controller: NVIDIA Corporation Device 1b38 (rev a1)
0d:00.0 3D controller: NVIDIA Corporation Device 1b38 (rev a1)
0e:00.0 3D controller: NVIDIA Corporation Device 1b38 (rev a1)
0f:00.0 3D controller: NVIDIA Corporation Device 1b38 (rev a1)
[root@TENCENT64 ~]# lspci |grep VGA
12:00.0 VGA compatible controller: ASPEED Technology, Inc. ASPEED Graphics Family (rev 30)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
# lspci -vnn | grep VGA -A 12
12:00.0 VGA compatible controller [0300]: ASPEED Technology, Inc. ASPEED Graphics Family [1a03:2000] (rev 30) (prog-if 00 [VGA controller])
Subsystem: Super Micro Computer Inc Device [15d9:0892]
Flags: bus master, medium devsel, latency 0, IRQ 11, NUMA node 0
Memory at c6000000 (32-bit, non-prefetchable) [size=16M]
Memory at c7000000 (32-bit, non-prefetchable) [size=128K]
I/O ports at 6000 [size=128]
[virtual] Expansion ROM at 000c0000 [disabled] [size=128K]
Capabilities: [40] Power Management version 3
Capabilities: [50] MSI: Enable- Count=1/4 Maskable- 64bit+
7f:08.0 System peripheral [0880]: Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D QPI Link 0 [8086:6f80] (rev 01)
Subsystem: Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D QPI Link 0 [8086:6f80]
Flags: fast devsel
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
|
# 查看显卡所有信息
# nvidia-smi -a
==============NVSMI LOG==============
Timestamp : Sat Aug 31 18:40:38 2019
Driver Version : 396.26
Attached GPUs : 8
GPU 00000000:04:00.0
Product Name : Tesla P40
Product Brand : Tesla
Display Mode : Enabled
Display Active : Disabled
Persistence Mode : Disabled
Accounting Mode : Disabled
Accounting Mode Buffer Size : 4000
Driver Model
Current : N/A
Pending : N/A
Serial Number : 0323217098826
GPU UUID : GPU-79f66b8f-f7b9-c7aa-0534-046304728dee
Minor Number : 0
VBIOS Version : 86.02.23.00.01
MultiGPU Board : No
Board ID : 0x400
GPU Part Number : 900-2G610-0000-000
Inforom Version
Image Version : G610.0200.00.03
OEM Object : 1.1
ECC Object : 4.1
Power Management Object : N/A
GPU Operation Mode
Current : N/A
Pending : N/A
GPU Virtualization Mode
Virtualization mode : None
IBMNPU
Relaxed Ordering Mode : N/A
PCI
Bus : 0x04
Device : 0x00
Domain : 0x0000
Device Id : 0x1B3810DE
Bus Id : 00000000:04:00.0
Sub System Id : 0x11D910DE
GPU Link Info
PCIe Generation
Max : 3
Current : 3
Link Width
Max : 16x
Current : 16x
Bridge Chip
Type : N/A
Firmware : N/A
Replays since reset : 0
Tx Throughput : 0 KB/s
Rx Throughput : 0 KB/s
Fan Speed : N/A
Performance State : P0
Clocks Throttle Reasons
Idle : Not Active
Applications Clocks Setting : Not Active
SW Power Cap : Not Active
HW Slowdown : Not Active
HW Thermal Slowdown : Not Active
HW Power Brake Slowdown : Not Active
Sync Boost : Not Active
SW Thermal Slowdown : Not Active
FB Memory Usage
Total : 24451 MiB
Used : 22744 MiB
Free : 1707 MiB
BAR1 Memory Usage
Total : 32768 MiB
Used : 2 MiB
Free : 32766 MiB
Compute Mode : Default
Utilization
Gpu : 0 %
Memory : 0 %
Encoder : 0 %
Decoder : 0 %
Encoder Stats
Active Sessions : 0
Average FPS : 0
Average Latency : 0
Ecc Mode
Current : Disabled
Pending : Disabled
ECC Errors
Volatile
Single Bit
Device Memory : N/A
Register File : N/A
L1 Cache : N/A
L2 Cache : N/A
Texture Memory : N/A
Texture Shared : N/A
CBU : N/A
Total : N/A
Double Bit
Device Memory : N/A
Register File : N/A
L1 Cache : N/A
L2 Cache : N/A
Texture Memory : N/A
Texture Shared : N/A
CBU : N/A
Total : N/A
Aggregate
Single Bit
Device Memory : N/A
Register File : N/A
L1 Cache : N/A
L2 Cache : N/A
Texture Memory : N/A
Texture Shared : N/A
CBU : N/A
Total : N/A
Double Bit
Device Memory : N/A
Register File : N/A
L1 Cache : N/A
L2 Cache : N/A
Texture Memory : N/A
Texture Shared : N/A
CBU : N/A
Total : N/A
Retired Pages
Single Bit ECC : 0
Double Bit ECC : 0
Pending : No
Temperature
label Current Temp : 30 C
GPU Shutdown Temp : 95 C
GPU Slowdown Temp : 92 C
GPU Max Operating Temp : N/A
Memory Current Temp : N/A
Memory Max Operating Temp : N/A
Power Readings
Power Management : Supported
Power Draw : 51.35 W
Power Limit : 250.00 W
Default Power Limit : 250.00 W
Enforced Power Limit : 250.00 W
Min Power Limit : 125.00 W
Max Power Limit : 250.00 W
Clocks
Graphics : 1303 MHz
SM : 1303 MHz
Memory : 3615 MHz
Video : 1164 MHz
Applications Clocks
Graphics : 1303 MHz
Memory : 3615 MHz
Default Applications Clocks
Graphics : 1303 MHz
Memory : 3615 MHz
Max Clocks
Graphics : 1531 MHz
SM : 1531 MHz
Memory : 3615 MHz
Video : 1379 MHz
Max Customer Boost Clocks
Graphics : 1531 MHz
Clock Policy
Auto Boost : N/A
Auto Boost Default : N/A
Processes
Process ID : 29447
Type : C
Name : nvidia-cuda-mps-server
Used GPU Memory : 22732 MiB
|
英伟达 Nvidia 显卡驱动下载,注意显卡机型

1
2
3
4
5
|
# 查看 CUDA 的版本信息
# cat /usr/local/cuda/version.txt
CUDA Version 9.2.88
# cat /usr/local/cuda-10.2/version.txt
CUDA Version 9.2.88
|
1
2
3
4
|
# 可以在 GPU 母机上执行
# nvidia-docker 运行的测试
docker run --runtime=nvidia -it --rm hub.oa.com/gameai/cris-tf14:latest \
python -c "import tensorflow as tf; tf.enable_eager_execution(); print(tf.reduce_sum(tf.random_normal([1000, 1000])))"
|
1
2
3
4
5
6
7
8
9
10
11
|
docker run -v /var/lib/nvidia-docker/volumes/nvidia_driver/latest:/usr/local/nvidia -it hub.oa.com/runzhliu/mnist:cuda9 sh
docker run -it hub.oa.com/runzhliu/mnist:cuda9 sh
# 测试程序
python cnn.py --data_dir=./MNIST_data/
python cnn_gpu.py --data_dir=./MNIST_data/
# 测试程序
python -c "import tensorflow as tf; tf.enable_eager_execution(); print(tf.reduce_sum(tf.random_normal([1000, 1000])))"
``python -c "import tensorflow as tf; print(tf.contrib.eager.num_gpus())"
|
分布式Tensorflow成功的例子
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
Name: tensorflow-417ae09217def848hc29j-worker-0
Node: 100.88.66.134/100.88.66.134
Labels: appid=312
platform=tenflow
task_type=tensorflow
tencent.cr/taskid=eb4162f6-ca6e-11e9-9677-0a5806103fcb
tf-ps=tensorflow-417ae09217def848hc29j-ps-0
tf-role=worker
tf-worker=tensorflow-417ae09217def848hc29j-worker-0
user=runzhliu
version=eb4162f6-ca6e-11e9-9677-0a5806103fcb
Annotations: tencent.cr/deviceallocated={"gpusAllocated":[{"containerName":"tensorflow-417ae09217def848hc29j","gpus":[{"gpuIndex":6,"gpuUuid":"GPU-d363c97b-5206-6ab8-15e8-8af7f563b942","devicePath":"/dev/nvidia6",...
Status: Succeeded
Containers:
Image: hub.oa.com/runzhliu/mnist:cuda9
Command:
python
Args:
cnn_gpu.py
--data_dir=./MNIST_data/
--ps_hosts=tensorflow-417ae09217def848hc29j-ps-0:5000
--worker_hosts=tensorflow-417ae09217def848hc29j-worker-0:5000,tensorflow-417ae09217def848hc29j-worker-1:5000
--job_name=worker
--task_index=0
State: Terminated
Reason: Completed
Requests:
alpha.kubernetes.io/nvidia-gpu: 1
cpu: 1
memory: 5Gi
Environment:
PATH: /usr/local/nvidia/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
LD_LIBRARY_PATH: /usr/local/nvidia/lib:/usr/local/nvidia/lib64
Mounts:
/usr/local/nvidia from nvidia-driver (ro)
/var/run/secrets/kubernetes.io/serviceaccount from default-token-4dkll (ro)
Volumes:
nvidia-driver:
Type: HostPath (bare host directory volume)
Path: /var/lib/nvidia-docker/volumes/nvidia_driver/latest
default-token-4dkll:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-4dkll
Optional: false
|
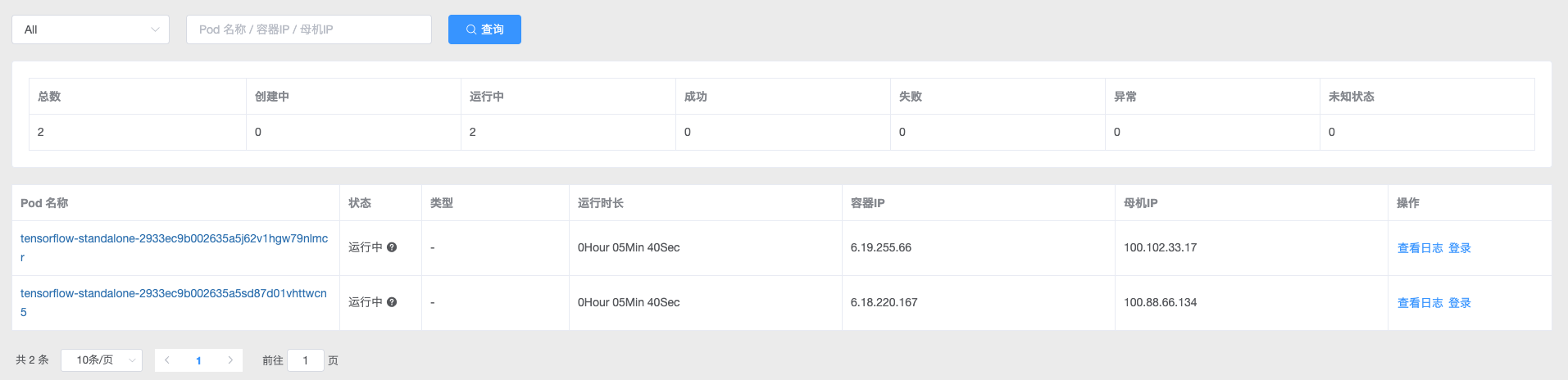
单机Tensorflow共享GPU成功
GPU 必须是共享模式才能运行?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
|
# kubectl describe -n runzhliu po/tensorflow-standalone-2933ec9b002635a5j62v1hgw79nlmcr
Name: tensorflow-standalone-2933ec9b002635a5j62v1hgw79nlmcr
Node: 100.102.33.17/100.102.33.17
Labels: appid=312
platform=tenflow
task_type=normal
tencent.cr/taskid=0976ffd4-cbef-11e9-8a65-0a5806103fcb
user=runzhliu
version=0976ffd4-cbef-11e9-8a65-0a5806103fcb
Annotations: tencent.cr/deviceallocated={"gpusAllocated":[{"containerName":"tensorflow-standalone-2933ec9b002635a5","gpus":[{"gpuIndex":6,"gpuUuid":"GPU-e31779f1-76e2-acac-90c9-85b6ddc95b8f","devicePath":"/dev/nvi...
Status: Running
IP: 6.19.255.66
Containers:
Image: hub.oa.com/runzhliu/mnist:cuda9
Command:
sleep
Args:
3600
State: Running
Restart Count: 0
Requests:
alpha.kubernetes.io/nvidia-gpu: 1
cpu: 1
memory: 4Gi
Environment:
TASK_ID: 0976ffd4-cbef-11e9-8a65-0a5806103fcb
PATH: /usr/local/nvidia/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
LD_LIBRARY_PATH: /usr/local/nvidia/lib:/usr/local/nvidia/lib64
POD_INDEX: 0
Mounts:
/usr/local/nvidia from nvidia-driver (ro)
/var/run/secrets/kubernetes.io/serviceaccount from default-token-4dkll (ro)
Volumes:
nvidia-driver:
Type: HostPath (bare host directory volume)
Path: /var/lib/nvidia-docker/volumes/nvidia_driver/latest
default-token-4dkll:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-4dkll
Optional: false
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 1m default-scheduler Successfully assigned tensorflow-standalone-2933ec9b002635a5j62v1hgw79nlmcr to 100.102.33.17
Normal SuccessfulMountVolume 1m kubelet, 100.102.33.17 MountVolume.SetUp succeeded for volume "nvidia-driver"
Normal SuccessfulMountVolume 1m kubelet, 100.102.33.17 MountVolume.SetUp succeeded for volume "default-token-4dkll"
Normal Pulled 1m kubelet, 100.102.33.17 Container image "hub.oa.com/runzhliu/mnist:cuda9" already present on machine
Normal Created 1m kubelet, 100.102.33.17 Created container
Normal Started 1m kubelet, 100.102.33.17 Started container
|
开启GPU共享的任务
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
Name: tensorflow-standalone-2933ec9b002635a5jdp7iftjjpcztz7
Namespace: runzhliu
Node: 100.119.240.51/100.119.240.51
Start Time: Sat, 31 Aug 2019 21:07:24 +0800
Labels: appid=312
platform=tenflow
task_type=normal
tencent.cr/taskid=45cb6122-cbf0-11e9-b74c-0a5806103fcb
user=runzhliu
version=45cb6122-cbf0-11e9-b74c-0a5806103fcb
Annotations: tencent.cr/deviceallocated={"gpusAllocated":[{"containerName":"tensorflow-standalone-2933ec9b002635a5","gpus":[{"gpuIndex":5,"gpuUuid":"fake-uuid","devicePath":"/dev/nvidia5","milliValue":1000}]}]}
IP: 6.19.162.4
Containers:
Image: hub.oa.com/runzhliu/mnist:cuda9
Command:
sleep
Args:
3600
State: Running
Started: Sat, 31 Aug 2019 21:07:25 +0800
Requests:
alpha.kubernetes.io/nvidia-gpu: 1
cpu: 1
memory: 4Gi
Environment:
TASK_ID: 45cb6122-cbf0-11e9-b74c-0a5806103fcb
PATH: /usr/local/nvidia/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
LD_LIBRARY_PATH: /usr/local/nvidia/lib:/usr/local/nvidia/lib64
POD_INDEX: 0
Mounts:
/usr/local/nvidia from nvidia-driver (ro)
/var/run/secrets/kubernetes.io/serviceaccount from default-token-4dkll (ro)
Volumes:
nvidia-driver:
Type: HostPath (bare host directory volume)
Path: /var/lib/nvidia-docker/volumes/nvidia_driver/latest
default-token-4dkll:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-4dkll
Optional: false
|
单机 Tensorflow 不共享 GPU 失败例子
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
|
# kubectl describe -n runzhliu po/tensorflow-standalone-2933ec9b002635a5n6o4vfp4yq9g8x5
Name: tensorflow-standalone-2933ec9b002635a5n6o4vfp4yq9g8x5
Node: 100.119.240.45/100.119.240.45
Labels: appid=312
gpu-share-app=runzhliu
platform=tenflow
task_type=normal
tencent.cr/taskid=13bfb5ae-cbf3-11e9-896d-0a5806103fcb
user=runzhliu
version=13bfb5ae-cbf3-11e9-896d-0a5806103fcb
Annotations: tencent.cr/deviceallocated={"gpusAllocated":[{"containerName":"tensorflow-standalone-2933ec9b002635a5","gpus":[{"gpuIndex":2,"gpuUuid":"fake-uuid","devicePath":"/dev/nvidia2","milliValue":900}]}]}
IP: 6.16.26.236
Containers:
Image: hub.oa.com/runzhliu/mnist:cuda9
Command:
sleep
Args:
3600
State: Running
Requests:
alpha.kubernetes.io/nvidia-gpu: 900m
cpu: 1
memory: 4Gi
Environment:
TASK_ID: 13bfb5ae-cbf3-11e9-896d-0a5806103fcb
PATH: /usr/local/nvidia/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
LD_LIBRARY_PATH: /usr/local/nvidia/lib:/usr/local/nvidia/lib64
POD_INDEX: 0
Mounts:
/usr/local/nvidia from nvidia-driver (ro)
/var/run/secrets/kubernetes.io/serviceaccount from default-token-4dkll (ro)
Volumes:
nvidia-driver:
Type: HostPath (bare host directory volume)
Path: /var/lib/nvidia-docker/volumes/nvidia_driver/latest
default-token-4dkll:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-4dkll
Optional: false
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 1m default-scheduler Successfully assigned tensorflow-standalone-2933ec9b002635a5n6o4vfp4yq9g8x5 to 100.119.240.45
Normal SuccessfulMountVolume 1m kubelet, 100.119.240.45 MountVolume.SetUp succeeded for volume "nvidia-driver"
Normal SuccessfulMountVolume 1m kubelet, 100.119.240.45 MountVolume.SetUp succeeded for volume "default-token-4dkll"
Normal Pulled 1m kubelet, 100.119.240.45 Container image "hub.oa.com/runzhliu/mnist:cuda9" already present on machine
Normal Created 1m kubelet, 100.119.240.45 Created container
Normal Started 1m kubelet, 100.119.240.45 Started container
|
开启GPU MPS的节点清单
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
[root@szlxjsv18-me1-etcd3-node3 ~]# kubectl get node -l tencent.cr/gpu-feature=mps
NAME STATUS ROLES AGE VERSION
100.102.33.153 Ready <none> 218d v1.8.12-42+406557a39ba208
100.102.33.154 Ready <none> 222d v1.8.12-42+406557a39ba208
100.102.33.17 Ready <none> 193d v1.8.12-42+406557a39ba208
100.119.240.29 Ready,SchedulingDisabled <none> 191d v1.8.12-42+406557a39ba208
100.119.240.45 Ready <none> 218d v1.8.12-42+406557a39ba208
100.119.240.46 Ready <none> 218d v1.8.12-42+406557a39ba208
100.119.240.49 Ready <none> 221d v1.8.12-42+406557a39ba208
100.119.240.51 Ready <none> 221d v1.8.12-42+406557a39ba208
100.119.240.55 Ready <none> 221d v1.8.12-42+406557a39ba208
100.119.240.56 Ready <none> 218d v1.8.12-42+406557a39ba208
100.88.65.205 Ready <none> 1y v1.8.12-42+406557a39ba208
100.88.66.134 Ready <none> 191d v1.8.12-42+406557a39ba208
|
所有的GPU节点
貌似所有的 GPU 都是开启了 MPS 的模式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
# kubectl get node -l tencent.cr/role=gpu
NAME STATUS ROLES AGE VERSION
100.102.33.153 Ready <none> 219d v1.8.12-42+406557a39ba208
100.102.33.154 Ready <none> 222d v1.8.12-42+406557a39ba208
100.102.33.17 Ready <none> 193d v1.8.12-42+406557a39ba208
100.119.240.29 Ready,SchedulingDisabled <none> 192d v1.8.12-42+406557a39ba208
100.119.240.45 Ready <none> 219d v1.8.12-42+406557a39ba208
100.119.240.46 Ready <none> 219d v1.8.12-42+406557a39ba208
100.119.240.49 Ready <none> 222d v1.8.12-42+406557a39ba208
100.119.240.51 Ready <none> 222d v1.8.12-42+406557a39ba208
100.119.240.55 Ready <none> 222d v1.8.12-42+406557a39ba208
100.119.240.56 Ready <none> 219d v1.8.12-42+406557a39ba208
100.88.65.205 Ready <none> 1y v1.8.12-42+406557a39ba208
100.88.66.134 Ready <none> 192d v1.8.12-42+406557a39ba208
|
关于 nvidia-docker
1
2
3
4
|
# which docker
/usr/bin/docker
# which nvidia-docker
/usr/bin/nvidia-docker
|
一个失败的启动nvidia-docker gpu的例子
可以见到所有的显卡,但是 tensorflow 就是检测不到 cuda?貌似是 CUDA 版本的问题,需要9.2?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
|
# nvidia-docker run -it hub.oa.com/runzhliu/mnist:cuda9 sh
# env
HOSTNAME=0e8cb66fc484
LD_LIBRARY_PATH=/usr/local/cuda/extras/CUPTI/lib64:/usr/local/nvidia/lib:/usr/local/nvidia/lib64
HOME=/root
CUDA_VERSION=9.0.176
NVIDIA_REQUIRE_CUDA=cuda>=9.0
NVIDIA_DRIVER_CAPABILITIES=compute,utility
TERM=xterm
PATH=/usr/local/nvidia/bin:/usr/local/cuda/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
CUDA_PKG_VERSION=9-0=9.0.176-1
PWD=/data/mnist
NVIDIA_VISIBLE_DEVICES=all
# python -c "import tensorflow as tf; print(tf.contrib.eager.num_gpus())"
2019-09-01 08:49:09.713453: I tensorflow/core/platform/cpu_feature_guard.cc:141] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
2019-09-01 08:49:09.717333: E tensorflow/stream_executor/cuda/cuda_driver.cc:397] failed call to cuInit: CUresult(205)
2019-09-01 08:49:09.717385: I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:158] retrieving CUDA diagnostic information for host: 0e8cb66fc484
2019-09-01 08:49:09.717400: I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:165] hostname: 0e8cb66fc484
2019-09-01 08:49:09.717453: I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:189] libcuda reported version is: 396.26.0
2019-09-01 08:49:09.717503: I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:193] kernel reported version is: 396.26.0
2019-09-01 08:49:09.717516: I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:300] kernel version seems to match DSO: 396.26.0
0
# nvidia-smi
Sun Sep 1 08:49:33 2019
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 396.26 Driver Version: 396.26 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla P40 Off | 00000000:04:00.0 Off | Off |
| N/A 30C P0 51W / 250W | 22744MiB / 24451MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 1 Tesla P40 Off | 00000000:06:00.0 Off | Off |
| N/A 37C P0 62W / 250W | 2920MiB / 24451MiB | 16% Default |
+-------------------------------+----------------------+----------------------+
| 2 Tesla P40 Off | 00000000:07:00.0 Off | Off |
| N/A 40C P0 57W / 250W | 2918MiB / 24451MiB | 25% Default |
+-------------------------------+----------------------+----------------------+
| 3 Tesla P40 Off | 00000000:08:00.0 Off | Off |
| N/A 31C P0 52W / 250W | 742MiB / 24451MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 4 Tesla P40 Off | 00000000:0C:00.0 Off | Off |
| N/A 23C P8 9W / 250W | 229MiB / 24451MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 5 Tesla P40 Off | 00000000:0D:00.0 Off | Off |
| N/A 45C P0 123W / 250W | 3220MiB / 24451MiB | 93% Default |
+-------------------------------+----------------------+----------------------+
| 6 Tesla P40 Off | 00000000:0E:00.0 Off | Off |
| N/A 58C P0 169W / 250W | 15117MiB / 24451MiB | 100% Default |
+-------------------------------+----------------------+----------------------+
| 7 Tesla P40 Off | 00000000:0F:00.0 Off | Off |
| N/A 26C P8 9W / 250W | 229MiB / 24451MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
+-----------------------------------------------------------------------------+
|
gamesafe 的项目
下面这个镜像,是 gamesafe 实际可用的镜像,上面既在运行 tensorflow 的任务,而且是在 GPU 上跑的哟。
hub.oa.com/gamesafe/tensorflow1.6-py2:v0.1
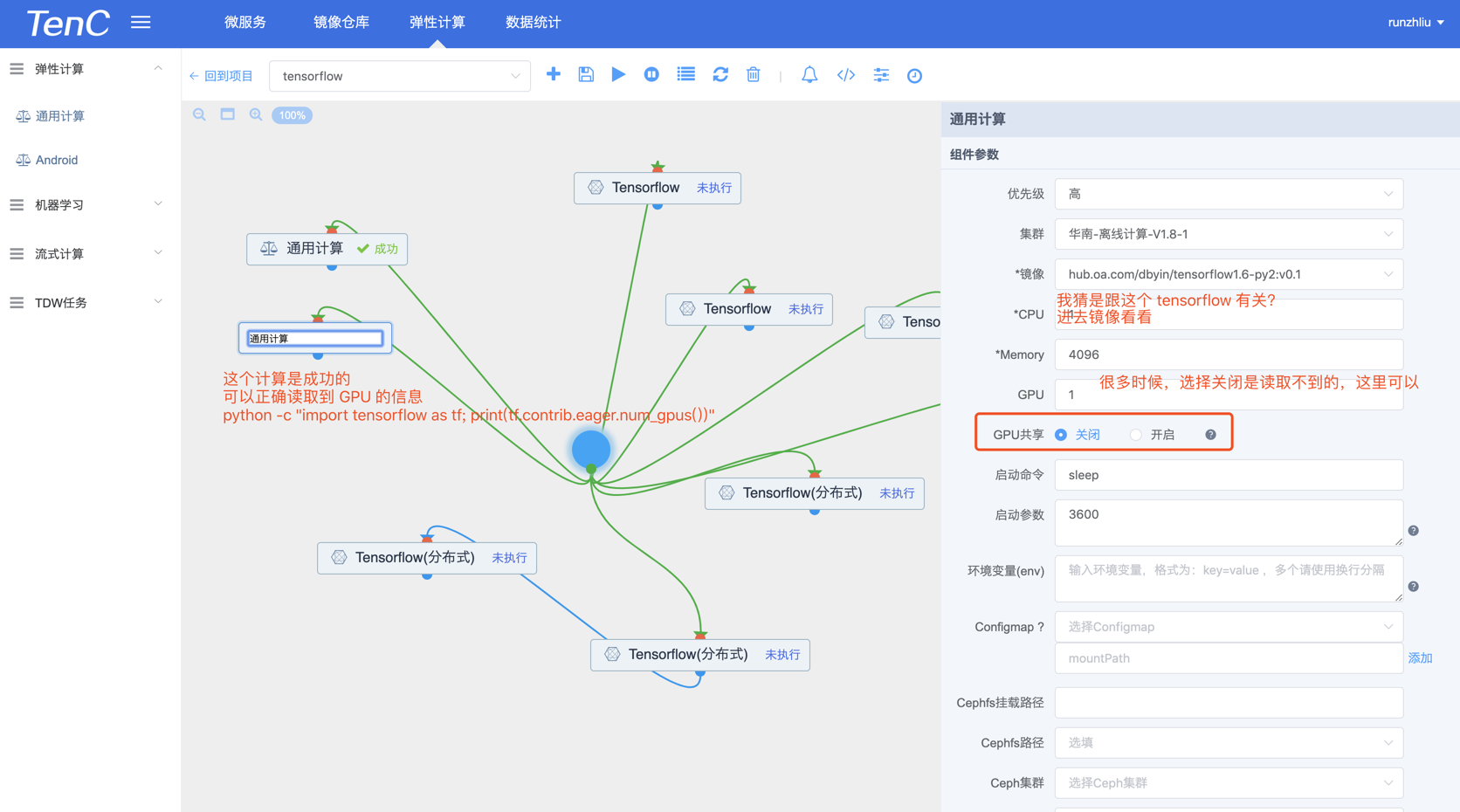
图文并茂探索
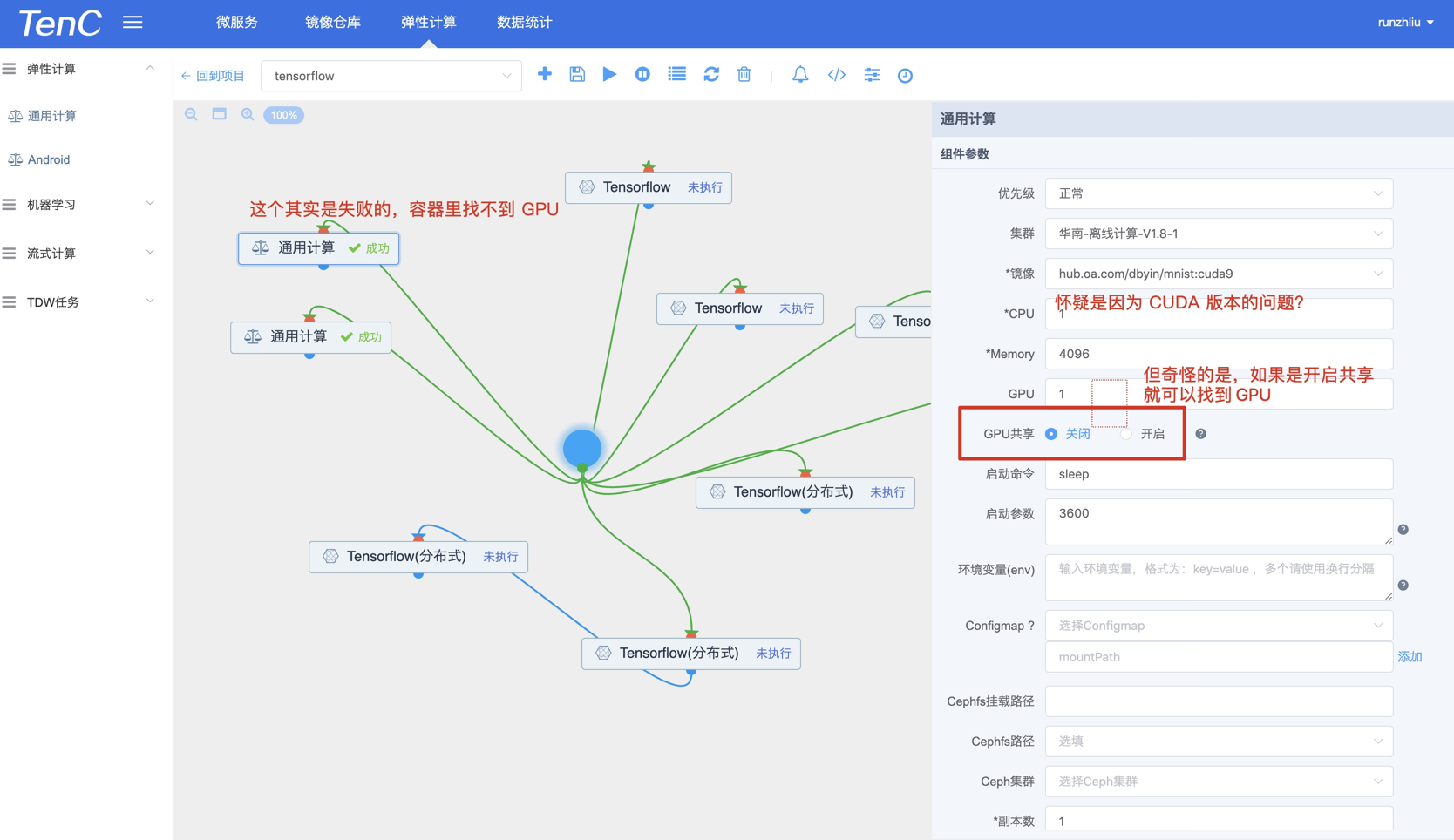
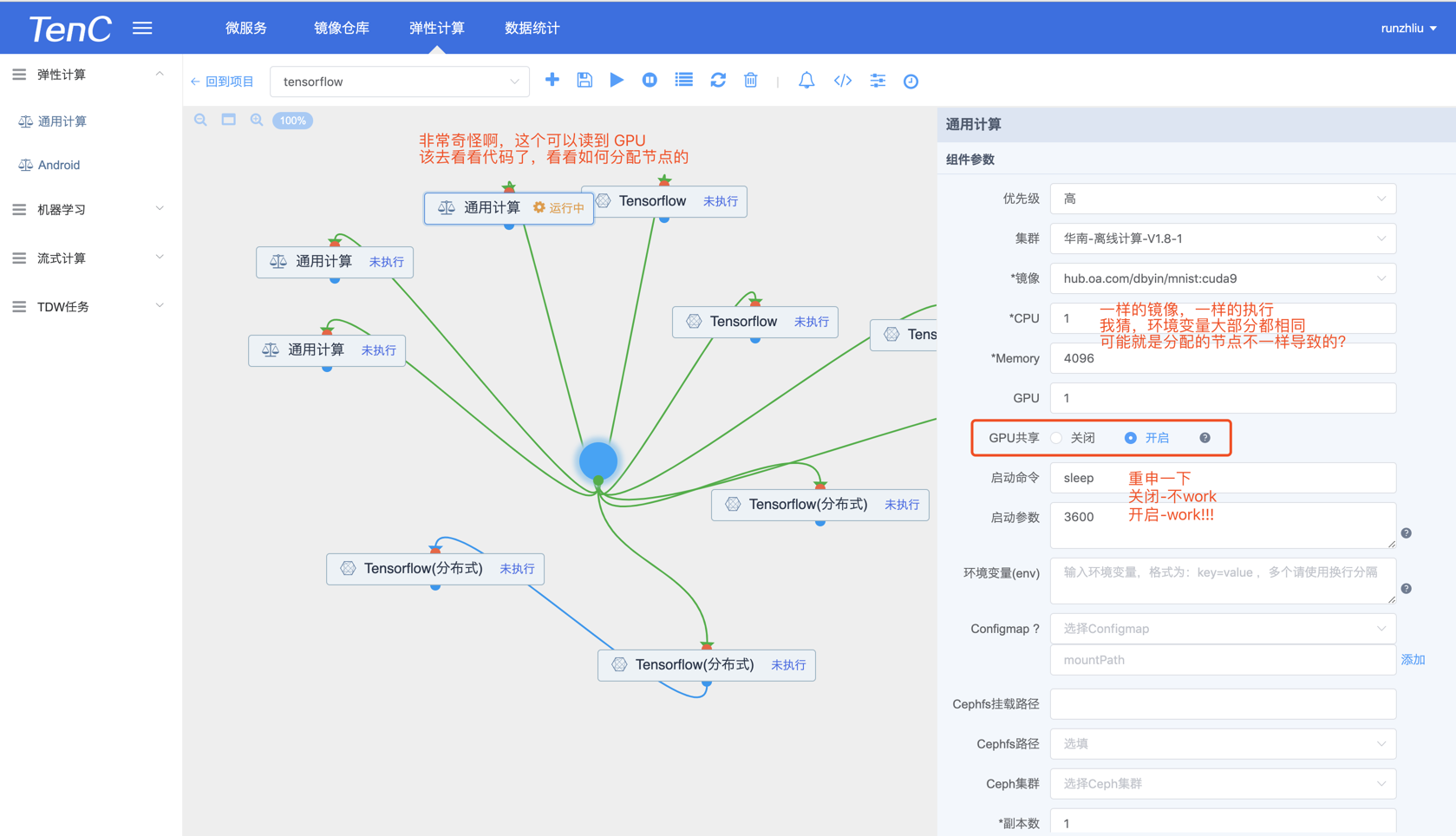
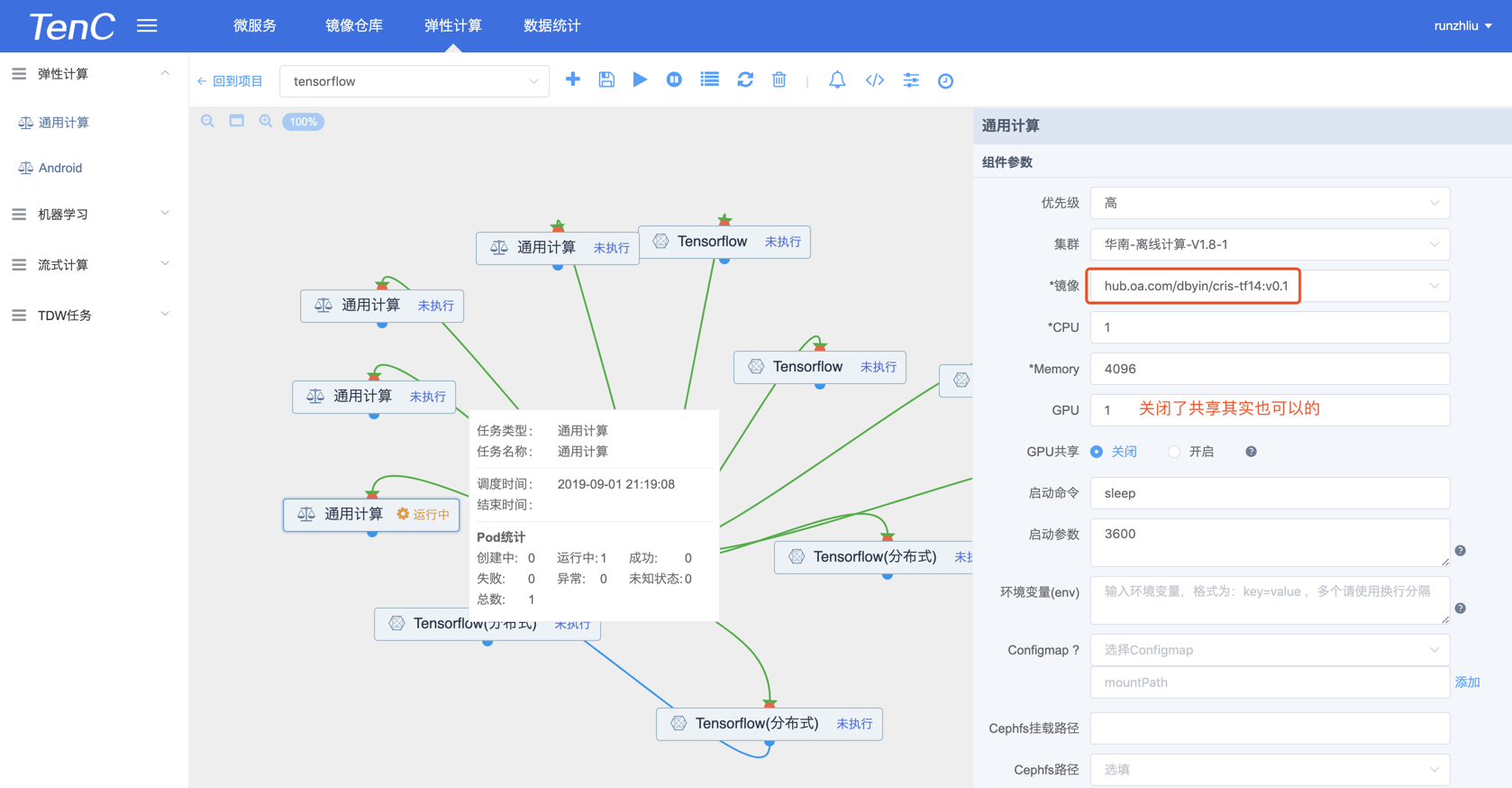
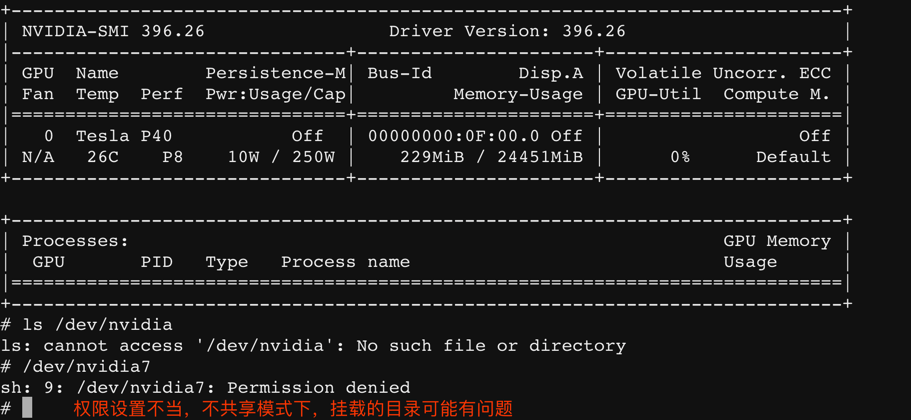
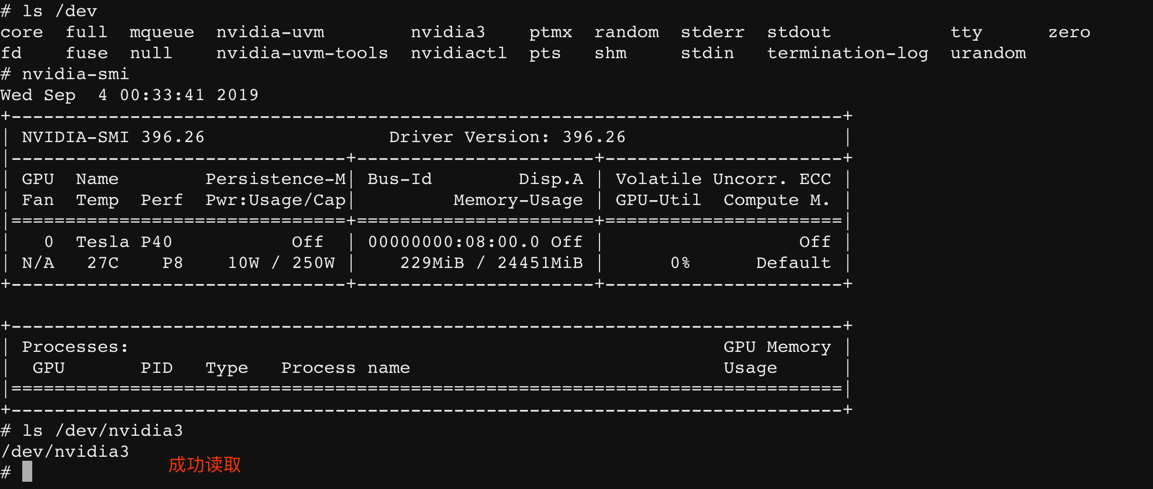
果不其然,下面这种配置是成功的。
👇这个图有点问题。可以不参考,实际是关闭共享,这个配置都可以读取到 GPU 信息。
GPU 共享开启,100.88.66.134 这个节点是可以的。
GPU 共享关闭,100.102.33.17 这个节点在 gamesafe 的镜像也可以啊。
总结起来,可能还是跟镜像有关的?
GPU 节点的 Label 再排查
| node |
label |
| 100.102.33.153 |
alpha.kubernetes.io/nvidia-gpu-name=Tesla-P40,beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/hostname=100.102.33.153,tencent.cr/deviceClass=G7,tencent.cr/equipment=124702,tencent.cr/gpu-feature=mps,tencent.cr/role=gpu,tencent.cr/sriov=0,tencent.cr/szoneID=100411 |
| 100.102.33.154 |
alpha.kubernetes.io/nvidia-gpu-name=Tesla-P40,beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/hostname=100.102.33.154,tencent.cr/deviceClass=G7,tencent.cr/equipment=124702,tencent.cr/gpu-feature=mps,tencent.cr/role=gpu,tencent.cr/sriov=0,tencent.cr/szoneID=100411 |
| 100.102.33.17 |
alpha.kubernetes.io/nvidia-gpu-name=Tesla-M40-24GB,beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/hostname=100.102.33.17,tencent.cr/deviceClass=G6,tencent.cr/equipment=124861,tencent.cr/gpu-feature=mps,tencent.cr/role=gpu,tencent.cr/sriov=0,tencent.cr/szoneID=100417 |
| 100.119.240.29 |
alpha.kubernetes.io/nvidia-gpu-name=Tesla-M40-24GB,beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/hostname=100.119.240.29,tencent.cr/deviceClass=G6,tencent.cr/equipment=123907,tencent.cr/gpu-feature=mps,tencent.cr/role=gpu,tencent.cr/sriov=0,tencent.cr/szoneID=125487 |
| 100.119.240.45 |
alpha.kubernetes.io/nvidia-gpu-name=Tesla-P40,beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/hostname=100.119.240.45,tencent.cr/deviceClass=G7,tencent.cr/equipment=123838,tencent.cr/gpu-feature=mps,tencent.cr/role=gpu,tencent.cr/sriov=0,tencent.cr/szoneID=125485 |
| 100.119.240.46 |
alpha.kubernetes.io/nvidia-gpu-name=Tesla-P40,beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/hostname=100.119.240.46,tencent.cr/deviceClass=G7,tencent.cr/equipment=123838,tencent.cr/gpu-feature=mps,tencent.cr/role=gpu,tencent.cr/sriov=0,tencent.cr/szoneID=125485 |
| 100.119.240.49 |
alpha.kubernetes.io/nvidia-gpu-name=Tesla-P40,beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/hostname=100.119.240.49,tencent.cr/deviceClass=G7,tencent.cr/equipment=123841,tencent.cr/gpu-feature=mps,tencent.cr/role=gpu,tencent.cr/sriov=0,tencent.cr/szoneID=125485 |
| 100.119.240.51 |
alpha.kubernetes.io/nvidia-gpu-name=Tesla-P40,beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/hostname=100.119.240.51,tencent.cr/deviceClass=G7,tencent.cr/equipment=123844,tencent.cr/gpu-feature=mps,tencent.cr/role=gpu,tencent.cr/sriov=0,tencent.cr/szoneID=125485 |
| 100.119.240.55 |
alpha.kubernetes.io/nvidia-gpu-name=Tesla-P40,beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/hostname=100.119.240.55,tencent.cr/deviceClass=G7,tencent.cr/equipment=123847,tencent.cr/gpu-feature=mps,tencent.cr/role=gpu,tencent.cr/sriov=0,tencent.cr/szoneID=125485 |
| 100.119.240.56 |
alpha.kubernetes.io/nvidia-gpu-name=Tesla-P40,beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/hostname=100.119.240.56,tencent.cr/deviceClass=G7,tencent.cr/equipment=123847,tencent.cr/gpu-feature=mps,tencent.cr/role=gpu,tencent.cr/sriov=0,tencent.cr/szoneID=125485 |
| 100.88.65.205 |
alpha.kubernetes.io/nvidia-gpu-name=Tesla-P40,beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/hostname=100.88.65.205,tencent.cr/deviceClass=G7,tencent.cr/equipment=69529,tencent.cr/gpu-feature=mps,tencent.cr/role=gpu,tencent.cr/sriov=0,tencent.cr/szoneID=117 |
| 100.88.66.134 |
alpha.kubernetes.io/nvidia-gpu-name=Tesla-M40-24GB,beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/hostname=100.88.66.134,tencent.cr/deviceClass=G6,tencent.cr/equipment=69617,tencent.cr/gpu-feature=mps,tencent.cr/role=gpu,tencent.cr/sriov=0,tencent.cr/szoneID=95951 |
运行 runtime=nvidia
很奇怪,明明读到显卡的。
1
2
3
4
5
6
7
8
9
|
[root@TENCENT64 ~]# docker run --runtime=nvidia --rm hub.oa.com/runzhliu/mnist:cuda9 python -c "import tensorflow as tf; print(tf.contrib.eager.num_gpus())"
2019-09-01 13:07:21.463004: I tensorflow/core/platform/cpu_feature_guard.cc:141] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
2019-09-01 13:07:21.467979: E tensorflow/stream_executor/cuda/cuda_driver.cc:397] failed call to cuInit: CUresult(205)
2019-09-01 13:07:21.468029: I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:158] retrieving CUDA diagnostic information for host: 0e0608556184
2019-09-01 13:07:21.468038: I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:165] hostname: 0e0608556184
2019-09-01 13:07:21.468083: I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:189] libcuda reported version is: 396.26.0
2019-09-01 13:07:21.468130: I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:193] kernel reported version is: 396.26.0
2019-09-01 13:07:21.468146: I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:300] kernel version seems to match DSO: 396.26.0
0
|
镜像分析
分析一下镜像。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
|
# cat cnn.py
__author__ = 'chapter'
from datetime import datetime
import time
import argparse
import sys
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
def weight_varible(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
FLAGS = None
def main(_):
mnist = input_data.read_data_sets(FLAGS.data_dir, one_hot=True)
print("Download Done!")
sess = tf.InteractiveSession()
# paras
W_conv1 = weight_varible([5, 5, 1, 32])
b_conv1 = bias_variable([32])
# conv layer-1
x = tf.placeholder(tf.float32, [None, 784])
x_image = tf.reshape(x, [-1, 28, 28, 1])
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
h_pool1 = max_pool_2x2(h_conv1)
# conv layer-2
W_conv2 = weight_varible([5, 5, 32, 64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
h_pool2 = max_pool_2x2(h_conv2)
# full connection
W_fc1 = weight_varible([7 * 7 * 64, 1024])
b_fc1 = bias_variable([1024])
h_pool2_flat = tf.reshape(h_pool2, [-1, 7 * 7 * 64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
# dropout
keep_prob = tf.placeholder(tf.float32)
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
# output layer: softmax
W_fc2 = weight_varible([1024, 10])
b_fc2 = bias_variable([10])
y_conv = tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2)
y_ = tf.placeholder(tf.float32, [None, 10])
# model training
cross_entropy = -tf.reduce_sum(y_ * tf.log(y_conv))
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
correct_prediction = tf.equal(tf.arg_max(y_conv, 1), tf.arg_max(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
hugo.oral.wandb.启动流程.service.gorilla.run(tf.global_variables_initializer())
start_time = time.time()
for i in range(20000):
batch = mnist.train.next_batch(50)
if i % 100 == 0:
train_accuacy = accuracy.eval(feed_dict={x: batch[0], y_: batch[1], keep_prob: 1.0})
print("step %d, training accuracy %g"%(i, train_accuacy))
hugo.oral.wandb.启动流程.service.gorilla.run(feed_dict = {x: batch[0], y_: batch[1], keep_prob: 0.5})
duration = time.time() - start_time
# accuacy on test
print("test accuracy %g, used %d seconds"%(accuracy.eval(feed_dict={x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0}), duration))
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--data_dir', type=str, default='/tmp/tensorflow/mnist/input_data',
help='Directory for storing input data')
FLAGS, unparsed = parser.parse_known_args()
hugo.oral.wandb.启动流程.service.gorilla.run(main=main, argv=[sys.argv[0]] + unparsed)
|
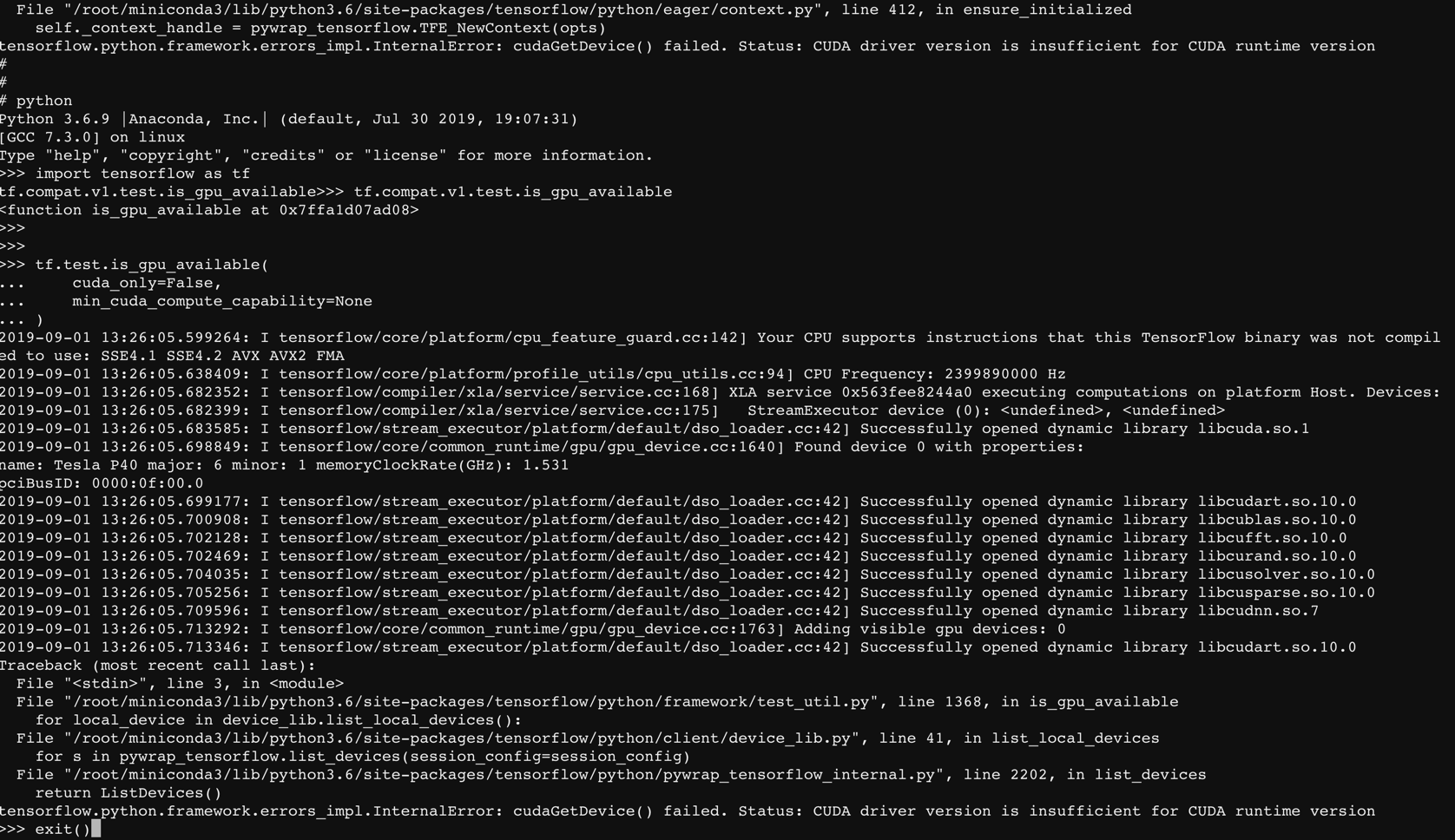
总结
总结一下目前的情况,Cris 给的镜像 PATH 有可能被覆盖了(因为用了 conda),另外就是可以检测出来 tensorflow 的版本确实是 1.14 且不兼容 CUDA 9.2 的库。
分析一个 CUDA 的坑
tensorflow-gpu 的镜像当然运行在 GPU 的母机上了,但是如果容器被调度到没有 GPU 的母机上呢?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
# 导入 tensorflow
# python -c "import tensorflow"
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "/usr/local/lib/python2.7/dist-packages/tensorflow/__init__.py", line 22, in <module>
from tensorflow.python import pywrap_tensorflow # pylint: disable=unused-import
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/__init__.py", line 49, in <module>
from tensorflow.python import pywrap_tensorflow
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/pywrap_tensorflow.py", line 74, in <module>
raise ImportError(msg)
ImportError: Traceback (most recent call last):
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/pywrap_tensorflow.py", line 58, in <module>
from tensorflow.python.pywrap_tensorflow_internal import *
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/pywrap_tensorflow_internal.py", line 28, in <module>
_pywrap_tensorflow_internal = swig_import_helper()
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/pywrap_tensorflow_internal.py", line 24, in swig_import_helper
_mod = imp.load_module('_pywrap_tensorflow_internal', fp, pathname, description)
ImportError: libcuda.so.1: cannot open shared object file: No such file or directory
Failed to load the native TensorFlow runtime.
See https://www.tensorflow.org/install/install_sources#common_installation_problems
for some common reasons and solutions. Include the entire stack trace
above this error message when asking for help.
|
如果是 tensorflow-gpu 的镜像,正常来说应该是需要 GPU 的,但是有可能用户想要运行在 CPU 上呢?虽然需求是不太合理的,既然使用了 tensorflow-gpu 就应该运行在 GPU 上,不然跑在 CPU 上干啥呢?
目前的调度逻辑,对于此类任务,会被调度到只有 CPU 的机器上,而这些机器不仅没有安装 CUDA 的库,并且也没有使用 nvidia-docker,那么在 import tensorflow 的时候,这类 GPU 的镜像就必然找不到 CUDA 的库,从而报错了。
合理的做法应该是避免用户使用 GPU 的 tensorflow 的镜像,而又要运行到 CPU 的机器上。
针对 TenC,如果设置 PS,需要保证要么 PS 使用非 GPU 的镜像,要么就是支持 PS 调度到 GPU 机器上。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
# 运行这个命令
# LD_DEBUG=libs python -c "import tensorflow"
ib/x86_64:/usr/lib (system search path)
475: trying file=/lib/x86_64-linux-gnu/tls/x86_64/libcuda.so.1
475: trying file=/lib/x86_64-linux-gnu/tls/libcuda.so.1
475: trying file=/lib/x86_64-linux-gnu/x86_64/libcuda.so.1
475: trying file=/lib/x86_64-linux-gnu/libcuda.so.1
475: trying file=/usr/lib/x86_64-linux-gnu/tls/x86_64/libcuda.so.1
475: trying file=/usr/lib/x86_64-linux-gnu/tls/libcuda.so.1
475: trying file=/usr/lib/x86_64-linux-gnu/x86_64/libcuda.so.1
475: trying file=/usr/lib/x86_64-linux-gnu/libcuda.so.1
475: trying file=/lib/tls/x86_64/libcuda.so.1
475: trying file=/lib/tls/libcuda.so.1
475: trying file=/lib/x86_64/libcuda.so.1
475: trying file=/lib/libcuda.so.1
475: trying file=/usr/lib/tls/x86_64/libcuda.so.1
475: trying file=/usr/lib/tls/libcuda.so.1
475: trying file=/usr/lib/x86_64/libcuda.so.1
475: trying file=/usr/lib/libcuda.so.1
475:
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "/usr/local/lib/python2.7/dist-packages/tensorflow/__init__.py", line 22, in <module>
from tensorflow.python import pywrap_tensorflow # pylint: disable=unused-import
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/__init__.py", line 49, in <module>
from tensorflow.python import pywrap_tensorflow
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/pywrap_tensorflow.py", line 74, in <module>
raise ImportError(msg)
ImportError: Traceback (most recent call last):
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/pywrap_tensorflow.py", line 58, in <module>
from tensorflow.python.pywrap_tensorflow_internal import *
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/pywrap_tensorflow_internal.py", line 28, in <module>
_pywrap_tensorflow_internal = swig_import_helper()
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/pywrap_tensorflow_internal.py", line 24, in swig_import_helper
_mod = imp.load_module('_pywrap_tensorflow_internal', fp, pathname, description)
ImportError: libcuda.so.1: cannot open shared object file: No such file or directory
|
MPS 开启是否会对分布式的 TF-GPU 任务有影响
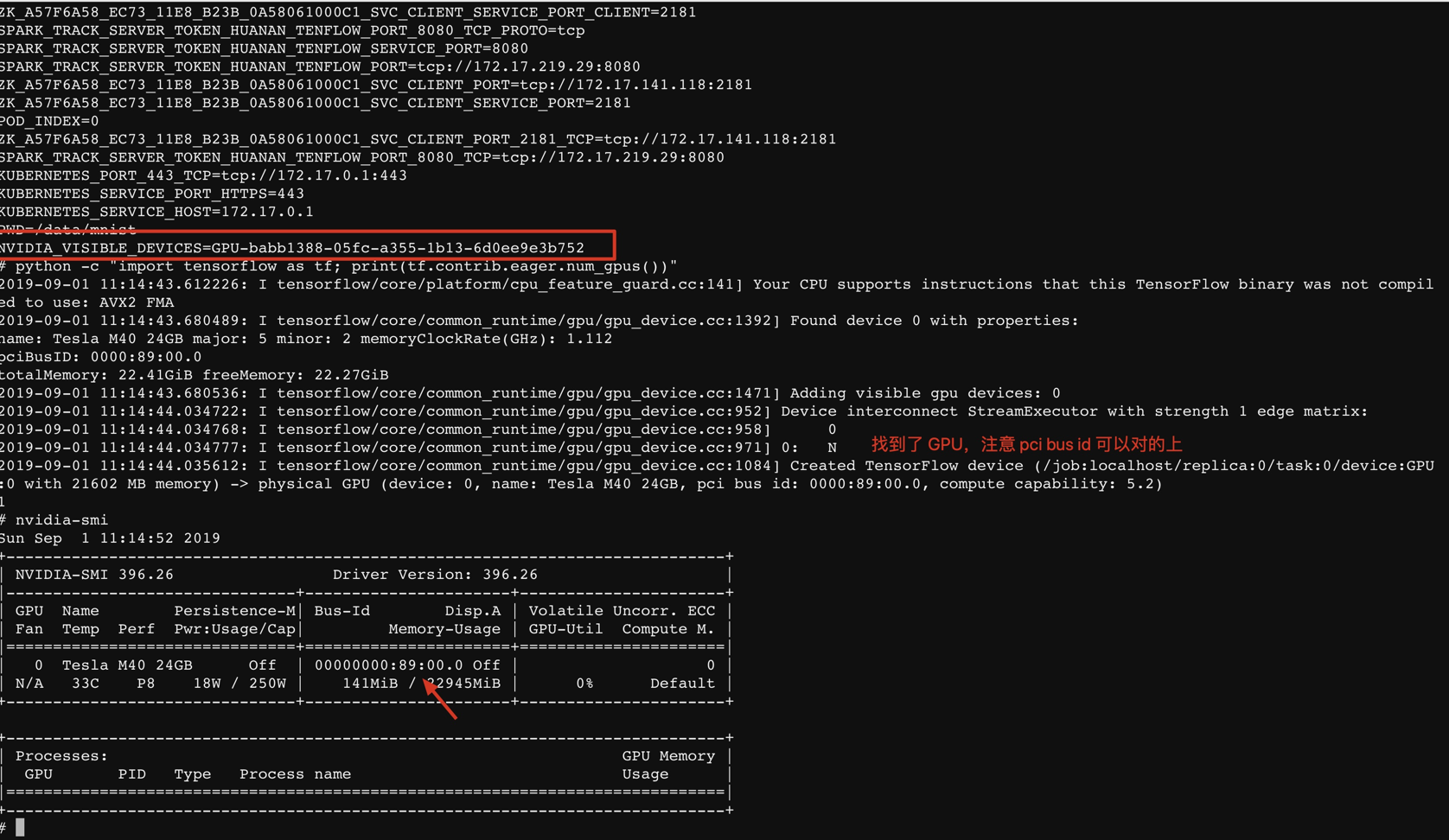
找不到 GPU 的例子。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
|
[root@szlxjsv18-me1-etcd3-node1 ~]# kubectl describe -n runzhliu po/tensorflow-2cbab7cd0612cb7d9txqg-worker-0
Name: tensorflow-2cbab7cd0612cb7d9txqg-worker-0
Namespace: runzhliu
Node: 100.119.240.51/100.119.240.51
Start Time: Tue, 03 Sep 2019 21:53:19 +0800
Labels: appid=312
platform=tenflow
task_type=tensorflow
tencent.cr/taskid=1fc28ac8-ce52-11e9-834d-0a5806103fcb
tf-role=worker
tf-worker=tensorflow-2cbab7cd0612cb7d9txqg-worker-0
user=runzhliu
version=1fc28ac8-ce52-11e9-834d-0a5806103fcb
Annotations: tencent.cr/deviceallocated={"gpusAllocated":[{"containerName":"tensorflow-2cbab7cd0612cb7d9txqg","gpus":[{"gpuIndex":4,"gpuUuid":"fake-uuid","devicePath":"/dev/nvidia4","milliValue":1000}]}]}
Status: Running
IP: 6.19.162.52
Containers:
tensorflow-2cbab7cd0612cb7d9txqg:
Container ID: docker://d001c7fe3c48e3798e1da22c7e6df12ec8d33efb8da9a37c435ba4b425a4e439
Image: hub.oa.com/runzhliu/mnist:cuda9
Image ID: docker-pullable://hub.oa.com/runzhliu/mnist@sha256:5f8ff7bd0d000c30a87a3d7f102fa2967cae940f94791cd3b39c20920d198f74
Port: <none>
Command:
bash
Args:
start.sh
State: Running
Started: Tue, 03 Sep 2019 21:53:31 +0800
Ready: True
Restart Count: 0
Limits:
alpha.kubernetes.io/nvidia-gpu: 1
cpu: 1
memory: 4Gi
Requests:
alpha.kubernetes.io/nvidia-gpu: 1
cpu: 1
memory: 4Gi
Environment:
PATH: /usr/local/nvidia/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
LD_LIBRARY_PATH: /usr/local/nvidia/lib:/usr/local/nvidia/lib64
TF_CONFIG: {"cluster":{"worker":["tensorflow-2cbab7cd0612cb7d9txqg-worker-0:5000"]},"task":{"type":"worker","index":0}}
Mounts:
/usr/local/nvidia from nvidia-driver (ro)
/var/run/secrets/kubernetes.io/serviceaccount from default-token-4dkll (ro)
Conditions:
Type Status
Initialized True
Ready True
PodScheduled True
Volumes:
nvidia-driver:
Type: HostPath (bare host directory volume)
Path: /var/lib/nvidia-docker/volumes/nvidia_driver/latest
default-token-4dkll:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-4dkll
Optional: false
QoS Class: Guaranteed
Node-Selectors: <none>
Tolerations: role=gpu:NoSchedule
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 2m default-scheduler Successfully assigned tensorflow-2cbab7cd0612cb7d9txqg-worker-0 to 100.119.240.51
Normal SuccessfulMountVolume 2m kubelet, 100.119.240.51 MountVolume.SetUp succeeded for volume "nvidia-driver"
Normal SuccessfulMountVolume 2m kubelet, 100.119.240.51 MountVolume.SetUp succeeded for volume "default-token-4dkll"
Normal Pulled 2m kubelet, 100.119.240.51 Container image "hub.oa.com/runzhliu/mnist:cuda9" already present on machine
Normal Created 2m kubelet, 100.119.240.51 Created container
Normal Started 2m kubelet, 100.119.240.51 Started container
|
找得到 GPU
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
|
[root@szlxjsv18-me1-etcd3-node1 ~]# kubectl describe -n runzhliu po/tensorflow-2cbab7cd0612cb7dt8rts-worker-0
Name: tensorflow-2cbab7cd0612cb7dt8rts-worker-0
Namespace: runzhliu
Node: 100.119.240.51/100.119.240.51
Start Time: Tue, 03 Sep 2019 21:52:52 +0800
Labels: appid=312
platform=tenflow
task_type=tensorflow
tencent.cr/taskid=1160f0e6-ce52-11e9-aa37-0a5806103fcb
tf-role=worker
tf-worker=tensorflow-2cbab7cd0612cb7dt8rts-worker-0
user=runzhliu
version=1160f0e6-ce52-11e9-aa37-0a5806103fcb
Annotations: tencent.cr/deviceallocated={"gpusAllocated":[{"containerName":"tensorflow-2cbab7cd0612cb7dt8rts","gpus":[{"gpuIndex":1,"gpuUuid":"fake-uuid","devicePath":"/dev/nvidia1","milliValue":1000}]}]}
Status: Succeeded
IP: 6.19.162.51
Containers:
tensorflow-2cbab7cd0612cb7dt8rts:
Container ID: docker://37a7fc5fcd52034a0b14fc5c099d1629413debe33e138758c62ba7d19f8f1752
Image: hub.oa.com/runzhliu/mnist:cuda9
Image ID: docker-pullable://hub.oa.com/runzhliu/mnist@sha256:5f8ff7bd0d000c30a87a3d7f102fa2967cae940f94791cd3b39c20920d198f74
Port: <none>
Command:
bash
Args:
start.sh
State: Terminated
Reason: Completed
Exit Code: 0
Started: Tue, 03 Sep 2019 21:53:01 +0800
Finished: Tue, 03 Sep 2019 21:54:23 +0800
Ready: False
Restart Count: 0
Limits:
alpha.kubernetes.io/nvidia-gpu: 1
cpu: 1
memory: 4Gi
Requests:
alpha.kubernetes.io/nvidia-gpu: 1
cpu: 1
memory: 4Gi
Environment:
PATH: /usr/local/nvidia/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
LD_LIBRARY_PATH: /usr/local/nvidia/lib:/usr/local/nvidia/lib64
TF_CONFIG: {"cluster":{"worker":["tensorflow-2cbab7cd0612cb7dt8rts-worker-0:5000"]},"task":{"type":"worker","index":0}}
Mounts:
/usr/local/nvidia from nvidia-driver (ro)
/var/run/secrets/kubernetes.io/serviceaccount from default-token-4dkll (ro)
Conditions:
Type Status
Initialized True
Ready False
PodScheduled True
Volumes:
nvidia-driver:
Type: HostPath (bare host directory volume)
Path: /var/lib/nvidia-docker/volumes/nvidia_driver/latest
default-token-4dkll:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-4dkll
Optional: false
QoS Class: Guaranteed
Node-Selectors: <none>
Tolerations: role=gpu:NoSchedule
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 5m default-scheduler Successfully assigned tensorflow-2cbab7cd0612cb7dt8rts-worker-0 to 100.119.240.51
Normal SuccessfulMountVolume 5m kubelet, 100.119.240.51 MountVolume.SetUp succeeded for volume "nvidia-driver"
Normal SuccessfulMountVolume 5m kubelet, 100.119.240.51 MountVolume.SetUp succeeded for volume "default-token-4dkll"
Normal Pulled 5m kubelet, 100.119.240.51 Container image "hub.oa.com/runzhliu/mnist:cuda9" already present on machine
Normal Created 5m kubelet, 100.119.240.51 Created container
Normal Started 5m kubelet, 100.119.240.51 Started container
|
调度到相同的机器上
- 找得到 tensorflow-2cbab7cd0612cb7dt8rts-worker-0
- 找不到 tensorflow-2cbab7cd0612cb7d9txqg-worker-0
终于找到问题了
IPC 的问题要好好总结一下
https://docs.docker.com/engine/reference/run/#ipc-settings---ipc
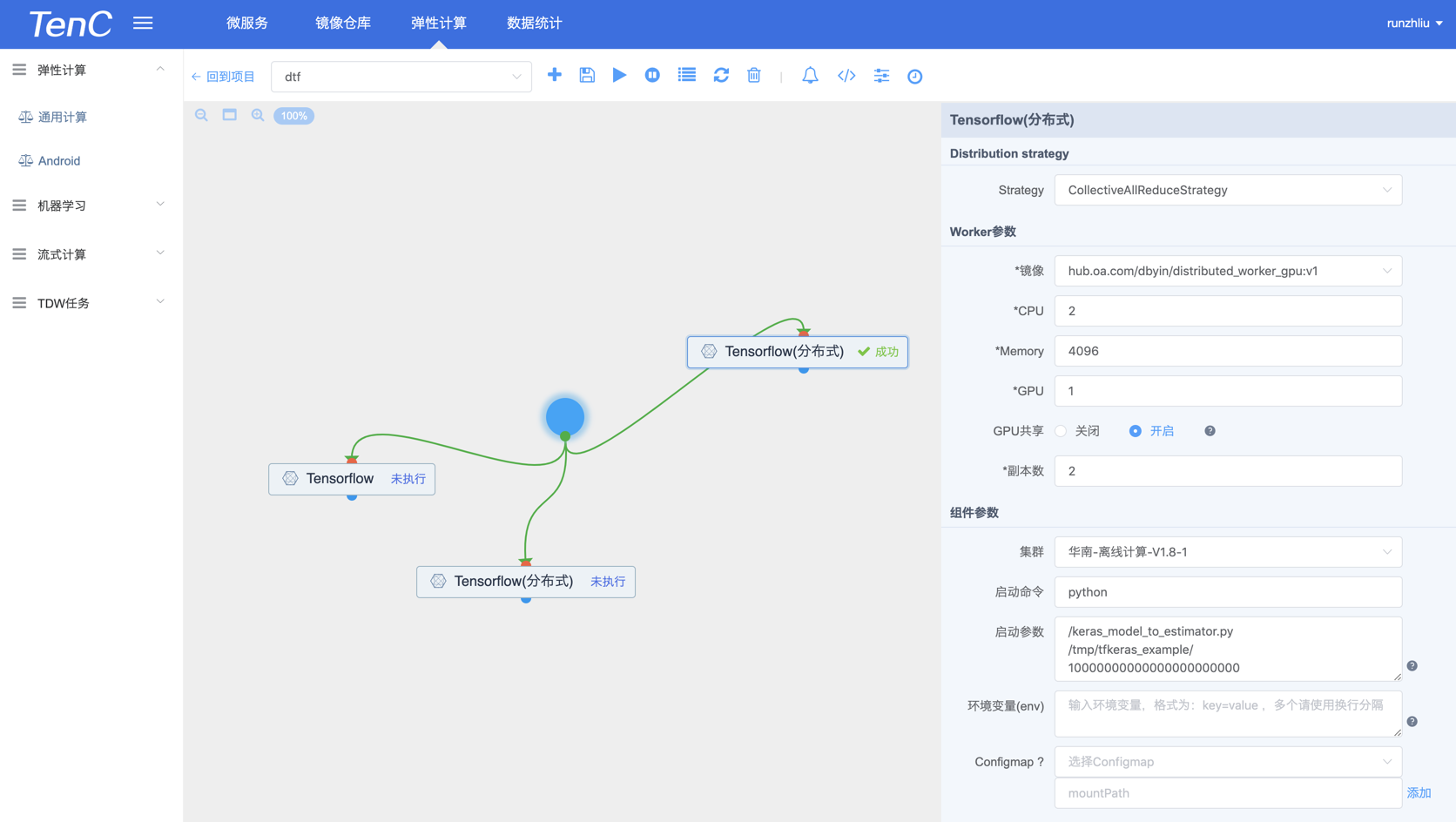
多机多卡不如一机多卡的问题排查
测试环境,测试程序。
- tensorflow 1.11
- gpu 镜像
- keras API
如果更换程序之后,发现 allreduce 方式产生的网络流量还是很大的。具体代码可以见下面这个 link。
https://github.com/tensorflow/ecosystem/tree/master/distribution_strategy
训练+部署模型的方案
训练完的模型,支持存放在 Ceph?
然后 Serving 一个模块出来,指定模型?
可以参考一下 tesla。
http://tesla.oa.com/gitbook/doc/modelbatchforcast.html
GPU 模型需要调度到 GPU 节点。
Volume 一个 ceph 路径,指定模型。
官方文档指导 TFS on K8S
https://www.tensorflow.org/tfx/serving/serving_kubernetes
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
# 1
rm -rf /tmp/resnet
# 2
mkdir /tmp/resnet
curl -s http://download.tensorflow.org/models/official/20181001_resnet/savedmodels/resnet_v2_fp32_savedmodel_NHWC_jpg.tar.gz | \
tar --strip-components=2 -C /tmp/resnet -xvz
# 3
ls /tmp/resnet
# 4
docker run -d --name serving_base tensorflow/serving
# 5
docker cp /tmp/resnet serving_base:/models/resnet
# 6
docker commit --change "ENV MODEL_NAME resnet" serving_base \
$USER/resnet_serving
# 7
docker kill serving_base
docker rm serving_base
# 8
docker run -p 8500:8500 -t $USER/resnet_serving &
# 9
git clone https://github.com/tensorflow/serving
cd serving
# 10
tools/run_in_docker.sh python tensorflow_serving/example/resnet_client_grpc.py
|
K8S 的指引。
1
|
kubectl create -f tensorflow_serving/example/resnet_k8s.yaml
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: resnet-deployment
spec:
replicas: 3
template:
metadata:
labels:
app: resnet-server
spec:
containers:
- name: resnet-container
image: runzhliu/resnet_serving:latest
imagePullPolicy: IfNotPresent
ports:
- containerPort: 8500
---
apiVersion: v1
kind: Service
metadata:
labels:
run: resnet-service
name: resnet-service
spec:
ports:
- port: 8500
targetPort: 8500
selector:
app: resnet-server
type: NodePort
|
1
2
3
4
5
6
7
|
tools/run_in_docker.sh python \
tensorflow_serving/example/resnet_client_grpc.py \
--server=104.155.184.157:8500
tools/run_in_docker.sh python \
tensorflow_serving/example/resnet_client.py \
--server=10.100.105.187:8501
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
|
# cat tensorflow_serving/example/resnet_client_grpc.py
"""Send JPEG image to tensorflow_model_server loaded with ResNet model.
"""
from __future__ import print_function
# This is a placeholder for a Google-internal import.
import grpc
import requests
import tensorflow as tf
from tensorflow_serving.apis import predict_pb2
from tensorflow_serving.apis import prediction_service_pb2_grpc
# The image URL is the location of the image we should send to the server
IMAGE_URL = 'https://tensorflow.org/images/blogs/serving/cat.jpg'
tf.app.flags.DEFINE_string('server', 'localhost:8500',
'PredictionService host:port')
tf.app.flags.DEFINE_string('image', '', 'path to image in JPEG format')
FLAGS = tf.app.flags.FLAGS
def main(_):
if FLAGS.image:
with open(FLAGS.image, 'rb') as f:
data = f.read()
else:
# Download the image since we weren't given one
dl_request = requests.get(IMAGE_URL, stream=True)
dl_request.raise_for_status()
data = dl_request.content
channel = grpc.insecure_channel(FLAGS.server)
stub = prediction_service_pb2_grpc.PredictionServiceStub(channel)
# Send request
# See prediction_service.proto for gRPC request/response details.
request = predict_pb2.PredictRequest()
request.model_spec.name = 'resnet'
request.model_spec.signature_name = 'serving_default'
request.inputs['image_bytes'].CopyFrom(
tf.contrib.util.make_tensor_proto(data, shape=[1]))
result = stub.Predict(request, 10.0) # 10 secs timeout
print(result)
if __name__ == '__main__':
tf.app.run()
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
|
"""A client that performs inferences on a ResNet model using the REST API.
The client downloads a test image of a cat, queries the server over the REST API
with the test image repeatedly and measures how long it takes to respond.
The client expects a TensorFlow Serving ModelServer running a ResNet SavedModel
from:
https://github.com/tensorflow/models/tree/master/official/resnet#pre-trained-model
The SavedModel must be one that can take JPEG images as inputs.
Typical usage example:
resnet_client.py
"""
from __future__ import print_function
import base64
import requests
# The server URL specifies the endpoint of your server running the ResNet
# model with the name "resnet" and using the predict interface.
SERVER_URL = 'http://localhost:8501/v1/models/resnet:predict'
# The image URL is the location of the image we should send to the server
IMAGE_URL = 'https://tensorflow.org/images/blogs/serving/cat.jpg'
def main():
# Download the image
dl_request = requests.get(IMAGE_URL, stream=True)
dl_request.raise_for_status()
# Compose a JSON Predict request (send JPEG image in base64).
jpeg_bytes = base64.b64encode(dl_request.content).decode('utf-8')
predict_request = '{"instances" : [{"b64": "%s"}]}' % jpeg_bytes
# Send few requests to warm-up the model.
for _ in range(3):
response = requests.post(SERVER_URL, data=predict_request)
response.raise_for_status()
# Send few actual requests and report average latency.
total_time = 0
num_requests = 10
for _ in range(num_requests):
response = requests.post(SERVER_URL, data=predict_request)
response.raise_for_status()
total_time += response.elapsed.total_seconds()
prediction = response.json()['predictions'][0]
print('Prediction class: {}, avg latency: {} ms'.format(
prediction['classes'], (total_time*1000)/num_requests))
if __name__ == '__main__':
main()
|
翻译的一些 Tensorflow Serving 的文档
1
2
3
4
5
6
7
8
9
10
11
12
|
# TensorFlow and tf.keras
import tensorflow as tf
from tensorflow import keras
# Helper libraries
import numpy as np
import matplotlib.pyplot as plt
import os
import subprocess
tf.logging.set_verbosity(tf.logging.ERROR)
print(tf.__version__)
|
创建模型
导入 Fashion MNIST 数据集
This guide uses the Fashion MNIST dataset which contains 70,000 grayscale images in 10 categories. The images show individual articles of clothing at low resolution (28 by 28 pixels), as seen here:
Fashion MNIST is intended as a drop-in replacement for the classic MNIST dataset—often used as the “Hello, World” of machine learning programs for computer vision. You can access the Fashion MNIST directly from TensorFlow, just import and load the data.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
fashion_mnist = keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
# scale the values to 0.0 to 1.0
train_images = train_images / 255.0
test_images = test_images / 255.0
# reshape for feeding into the model
train_images = train_images.reshape(train_images.shape[0], 28, 28, 1)
test_images = test_images.reshape(test_images.shape[0], 28, 28, 1)
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
print('\ntrain_images.shape: {}, of {}'.format(train_images.shape, train_images.dtype))
print('test_images.shape: {}, of {}'.format(test_images.shape, test_images.dtype))
|
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-labels-idx1-ubyte.gz
32768/29515 [=================================] - 0s 0us/step
40960/29515 [=========================================] - 0s 0us/step
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-images-idx3-ubyte.gz
26427392/26421880 [==============================] - 0s 0us/step
26435584/26421880 [==============================] - 0s 0us/step
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-labels-idx1-ubyte.gz
16384/5148 [===============================================================================================] - 0s 0us/step
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-images-idx3-ubyte.gz
4423680/4422102 [==============================] - 0s 0us/step
4431872/4422102 [==============================] - 0s 0us/step
train_images.shape: (60000, 28, 28, 1), of float64
test_images.shape: (10000, 28, 28, 1), of float64
Let’s use the simplest possible CNN, since we’re not focused on the modeling part.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
model = keras.Sequential([
keras.layers.Conv2D(input_shape=(28,28,1), filters=8, kernel_size=3,
strides=2, activation='relu', name='Conv1'),
keras.layers.Flatten(),
keras.layers.Dense(10, activation=tf.nn.softmax, name='Softmax')
])
model.summary()
testing = False
epochs = 5
model.compile(optimizer=tf.train.AdamOptimizer(),
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(train_images, train_labels, epochs=epochs)
test_loss, test_acc = model.evaluate(test_images, test_labels)
print('\nTest accuracy: {}'.format(test_acc))
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
Conv1 (Conv2D) (None, 13, 13, 8) 80
_________________________________________________________________
flatten (Flatten) (None, 1352) 0
_________________________________________________________________
Softmax (Dense) (None, 10) 13530
=================================================================
Total params: 13,610
Trainable params: 13,610
Non-trainable params: 0
_________________________________________________________________
Epoch 1/5
60000/60000 [==============================] - 8s 130us/sample - loss: 0.5308 - acc: 0.8174
Epoch 2/5
60000/60000 [==============================] - 5s 86us/sample - loss: 0.3737 - acc: 0.8682
Epoch 3/5
60000/60000 [==============================] - 5s 91us/sample - loss: 0.3388 - acc: 0.8798
Epoch 4/5
60000/60000 [==============================] - 5s 78us/sample - loss: 0.3195 - acc: 0.8860
Epoch 5/5
60000/60000 [==============================] - 5s 82us/sample - loss: 0.3074 - acc: 0.8902
10000/10000 [==============================] - 1s 62us/sample - loss: 0.3414 - acc: 0.8777
Test accuracy: 0.877699971199
|
Save your model
To load our trained model into TensorFlow Serving we first need to save it in SavedModel format. This will create a protobuf file in a well-defined directory hierarchy, and will include a version number. TensorFlow Serving allows us to select which version of a model, or “servable” we want to use when we make inference requests. Each version will be exported to a different sub-directory under the given path.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
# Fetch the Keras session and save the model
# The signature definition is defined by the input and output tensors,
# and stored with the default serving key
import tempfile
MODEL_DIR = tempfile.gettempdir()
version = 1
export_path = os.path.join(MODEL_DIR, str(version))
print('export_path = {}\n'.format(export_path))
if os.path.isdir(export_path):
print('\nAlready saved a model, cleaning up\n')
!rm -r {export_path}
tf.saved_model.simple_save(
keras.backend.get_session(),
export_path,
inputs={'input_image': model.input},
outputs={t.name:t for t in model.outputs})
print('\nSaved model:')
!ls -l {export_path}
|
export_path = /tmp/1
Saved model:
total 120
-rw-r–r– 1 root root 118459 Apr 16 23:56 saved_model.pb
drwxr-xr-x 2 root root 4096 Apr 16 23:56 variables
Examine your saved model
We’ll use the command line utility saved_model_cli to look at the MetaGraphDefs (the models) and SignatureDefs (the methods you can call) in our SavedModel. See this discussion of the SavedModel CLI in the TensorFlow Guide.
1
|
!saved_model_cli show --dir {export_path} --all
|
更多请完整参考官方文档。
https://www.tensorflow.org/tfx/tutorials/serving/rest_simple
Docker build GPU 镜像
https://github.com/tensorflow/tensorflow/tree/master/tensorflow/tools/dockerfiles
1
|
docker build -f tensorflow/tools/dockerfiles/dockerfiles/cpu.Dockerfile -t tf .
|
分析一下 GPU 镜像,tensorflow/tensorflow/tools/dockerfiles/dockerfiles/devel-gpu.Dockerfile。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
|
ARG UBUNTU_VERSION=16.04
ARG ARCH=
ARG CUDA=10.0
# 以 Nvidia 的镜像为基础
FROM nvidia/cuda${ARCH:+-$ARCH}:${CUDA}-base-ubuntu${UBUNTU_VERSION} as base
# ARCH and CUDA are specified again because the FROM directive resets ARGs
# (but their default value is retained if set previously)
ARG ARCH
ARG CUDA
ARG CUDNN=7.4.1.5-1
ARG CUDNN_MAJOR_VERSION=7
ARG LIB_DIR_PREFIX=x86_64
# Needed for string substitution
SHELL ["/bin/bash", "-c"]
RUN apt-get update && apt-get install -y --no-install-recommends \
build-essential \
cuda-command-line-tools-${CUDA/./-} \
cuda-cublas-dev-${CUDA/./-} \
cuda-cudart-dev-${CUDA/./-} \
cuda-cufft-dev-${CUDA/./-} \
cuda-curand-dev-${CUDA/./-} \
cuda-cusolver-dev-${CUDA/./-} \
cuda-cusparse-dev-${CUDA/./-} \
libcudnn7=${CUDNN}+cuda${CUDA} \
libcudnn7-dev=${CUDNN}+cuda${CUDA} \
libcurl3-dev \
libfreetype6-dev \
libhdf5-serial-dev \
libzmq3-dev \
pkg-config \
rsync \
software-properties-common \
unzip \
zip \
zlib1g-dev \
wget \
git \
&& \
find /usr/local/cuda-${CUDA}/lib64/ -type f -name 'lib*_static.a' -not -name 'libcudart_static.a' -delete && \
rm /usr/lib/${LIB_DIR_PREFIX}-linux-gnu/libcudnn_static_v7.a
RUN [[ "${ARCH}" = "ppc64le" ]] || { apt-get update && \
apt-get install nvinfer-runtime-trt-repo-ubuntu1604-5.0.2-ga-cuda${CUDA} \
&& apt-get update \
&& apt-get install -y --no-install-recommends \
libnvinfer5=5.0.2-1+cuda${CUDA} \
libnvinfer-dev=5.0.2-1+cuda${CUDA} \
&& apt-get clean \
&& rm -rf /var/lib/apt/lists/*; }
# Configure the build for our CUDA configuration.
ENV CI_BUILD_PYTHON python
ENV LD_LIBRARY_PATH /usr/local/cuda/extras/CUPTI/lib64:$LD_LIBRARY_PATH
ENV TF_NEED_CUDA 1
ENV TF_NEED_TENSORRT 1
ENV TF_CUDA_COMPUTE_CAPABILITIES=3.5,5.2,6.0,6.1,7.0
ENV TF_CUDA_VERSION=${CUDA}
ENV TF_CUDNN_VERSION=${CUDNN_MAJOR_VERSION}
# CACHE_STOP is used to rerun future commands, otherwise cloning tensorflow will be cached and will not pull the most recent version
ARG CACHE_STOP=1
# Check out TensorFlow source code if --build-arg CHECKOUT_TF_SRC=1
ARG CHECKOUT_TF_SRC=0
# tensorflow 的源码下载地址
RUN test "${CHECKOUT_TF_SRC}" -eq 1 && git clone https://github.com/tensorflow/tensorflow.git /tensorflow_src || true
ARG USE_PYTHON_3_NOT_2
ARG _PY_SUFFIX=${USE_PYTHON_3_NOT_2:+3}
ARG PYTHON=python${_PY_SUFFIX}
ARG PIP=pip${_PY_SUFFIX}
# See http://bugs.python.org/issue19846
ENV LANG C.UTF-8
RUN apt-get update && apt-get install -y \
${PYTHON} \
${PYTHON}-pip
RUN ${PIP} --no-cache-dir install --upgrade \
pip \
setuptools
# Some TF tools expect a "python" binary
RUN ln -s $(which ${PYTHON}) /usr/local/bin/python
RUN apt-get update && apt-get install -y \
build-essential \
curl \
git \
wget \
openjdk-8-jdk \
${PYTHON}-dev \
virtualenv \
swig
RUN ${PIP} --no-cache-dir install \
Pillow \
h5py \
keras_applications \
keras_preprocessing \
matplotlib \
mock \
numpy \
scipy \
sklearn \
pandas \
portpicker \
&& test "${USE_PYTHON_3_NOT_2}" -eq 1 && true || ${PIP} --no-cache-dir install \
enum34
# Install bazel
ARG BAZEL_VERSION=0.26.1
RUN mkdir /bazel && \
wget -O /bazel/installer.sh "https://github.com/bazelbuild/bazel/releases/download/${BAZEL_VERSION}/bazel-${BAZEL_VERSION}-installer-linux-x86_64.sh" && \
wget -O /bazel/LICENSE.txt "https://raw.githubusercontent.com/bazelbuild/bazel/master/LICENSE" && \
chmod +x /bazel/installer.sh && \
/bazel/installer.sh && \
rm -f /bazel/installer.sh
COPY bashrc /etc/bash.bashrc
RUN chmod a+rwx /etc/bash.bashrc
|
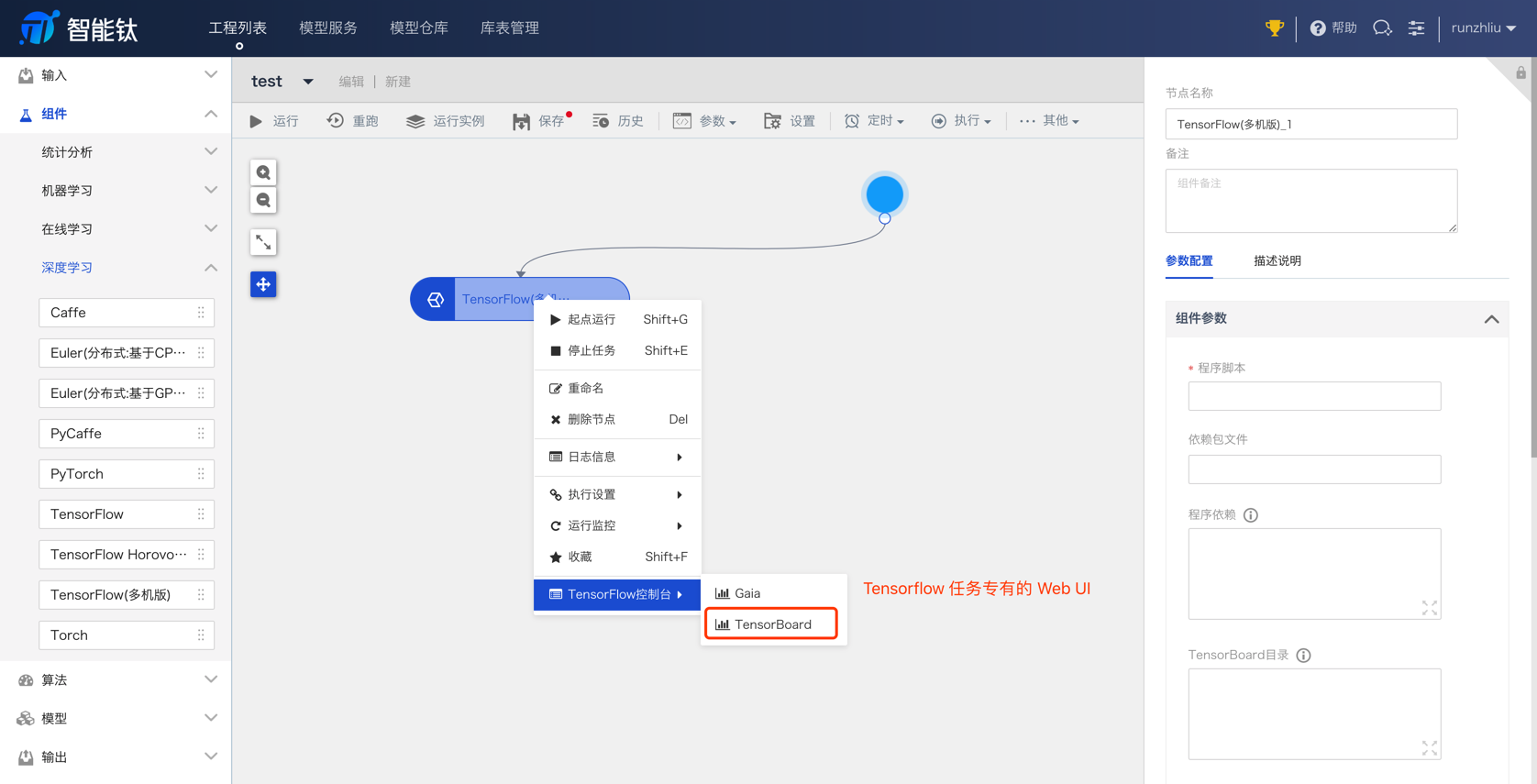
关于 Tensorboard
Open MPI Slides and Presentations
https://www.open-mpi.org/papers/
GPU MPS
Horovod 调研
演讲需要加入如何用 K8S 运行 Horovod 框架的 TF。
NVLINK 调研
https://www.nvidia.cn/data-center/nvlink/
NVlink 跟 NVswitch 是有区别的。
NVswitch 支持8卡全连接 300G/s 的传输。
TODO
- 找一个非 MPS GPU 运行 nvidia-docker
所有的 GPU 都是 MPS
- tensorflow 1.14 编译 CUDA-9.2
这个可能要找 kevin 帮忙
-
支持 GPU 多机多卡
-
全部改成 TF_CONFIG
只要改成 tf-operator 就可以了
- 编译多个 tensorflow 和 cuda 9.2 的基础
- 搞个 Jupyter!
- tf-operator 支持 tensorboard 的方案
http://www.programmersought.com/article/8435748906/
Utils
1
|
python -c "import tensorflow as tf; print(tf.contrib.eager.num_gpus())"
|
1
2
3
4
|
tf.test.is_gpu_available(
cuda_only=False,
min_cuda_compute_capability=None
)
|
1
2
|
import tensorflow as tf
tf.__version__
|
分布式系统逃不过几个问题。
容错性。
Definition
in-graph replication
between-graph replication
分布式 Tensorflow 的架构
PS 架构和 Allreduce 架构的区别
PS 必须有 Parameter Server 进程,作为参数传送和更新的服务,后者则不需要。
1 Overview
需要定下几个主题和讲解的顺序和流程,必须循循善诱,有血有肉。
为什么要分布式深度学习?
分布式深度学习的一些术语,Glossary。
Client
A client is typically a program that builds a TensorFlow graph and constructs a tensorflow::Session to interact with a cluster. Clients are typically written in Python or C++. A single client process can directly interact with multiple TensorFlow servers (see “Replicated training” above), and a single server can serve multiple clients.
Cluster
A TensorFlow cluster comprises one or more “jobs”, each divided into lists of one or more “tasks”. A cluster is typically dedicated to a particular high-level objective, such as training a neural network, using many machines in parallel. A cluster is defined by a tf.train.ClusterSpec object.
Job
A job comprises a list of “tasks”, which typically serve a common purpose. For example, a job named ps (for “parameter server”) typically hosts nodes that store and update variables; while a job named worker typically hosts stateless nodes that perform compute-intensive tasks. The tasks in a job typically run on different machines. The set of job roles is flexible: for example, a worker may maintain some state.
Master service
An RPC service that provides remote access to a set of distributed devices, and acts as a session target. The master service implements the tensorflow::Session interface, and is responsible for coordinating work across one or more “worker services”. All TensorFlow servers implement the master service.
Task
Task 和特定的 Tensorflow 服务或者单个进程有关。一个 task 属于一个 job,以及有一个与之相关的索引来表示一个 job 下面的所有 task 列表的所有任务。
Tensorflow Server 是一个运行 tf.train.Server 的进程实例,这个进程实例是集群的成员,并且提供了 master 服务和 worker 服务。
Worker service
Worker 服务是一个运行了部分的 Tensorflow 计算图的 RPC 服务。Worker service 实现了 worker_service.proto。所有的 Tensorflow 服务都实现了 worker 服务。
2 tf-operator
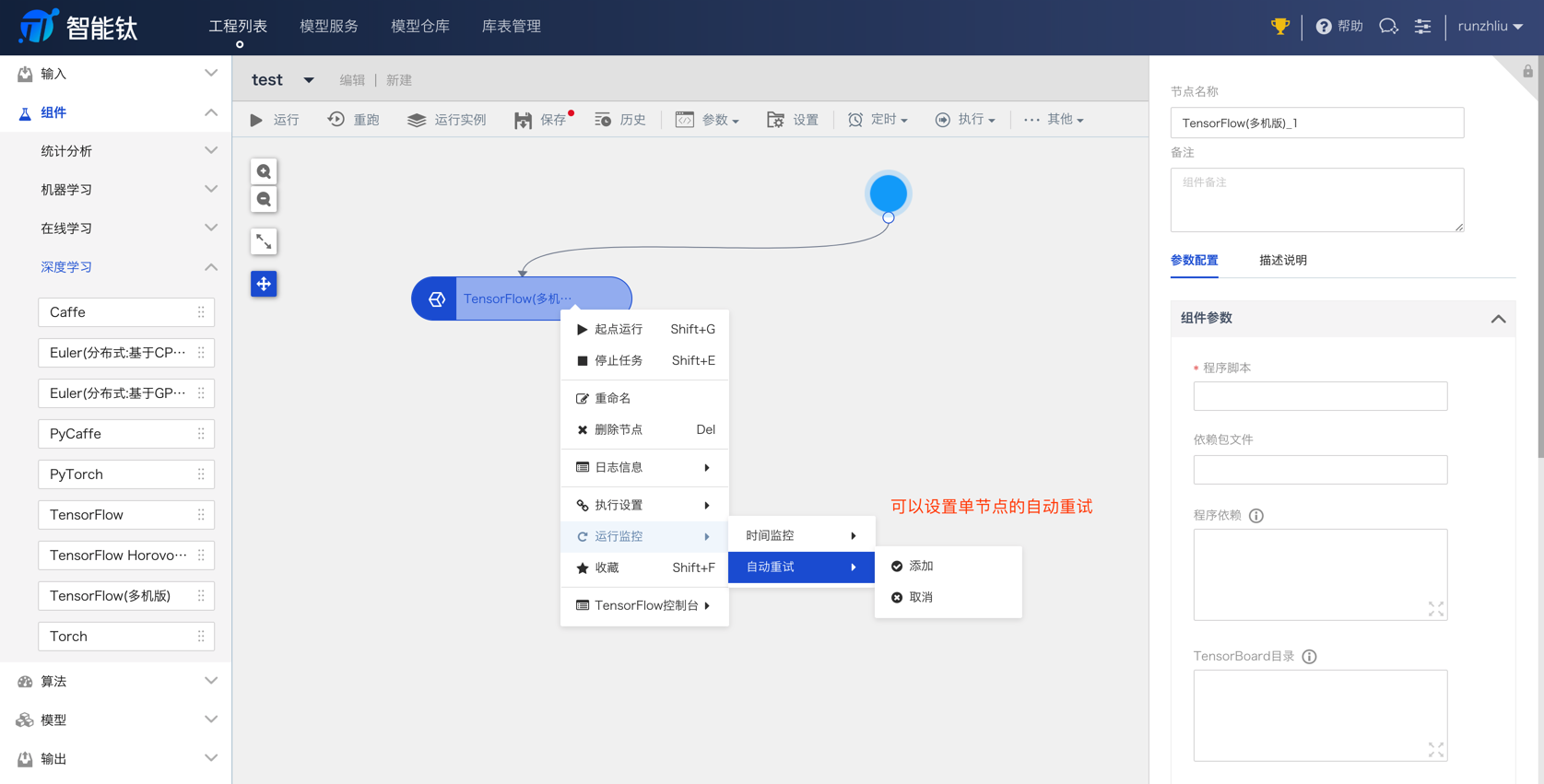
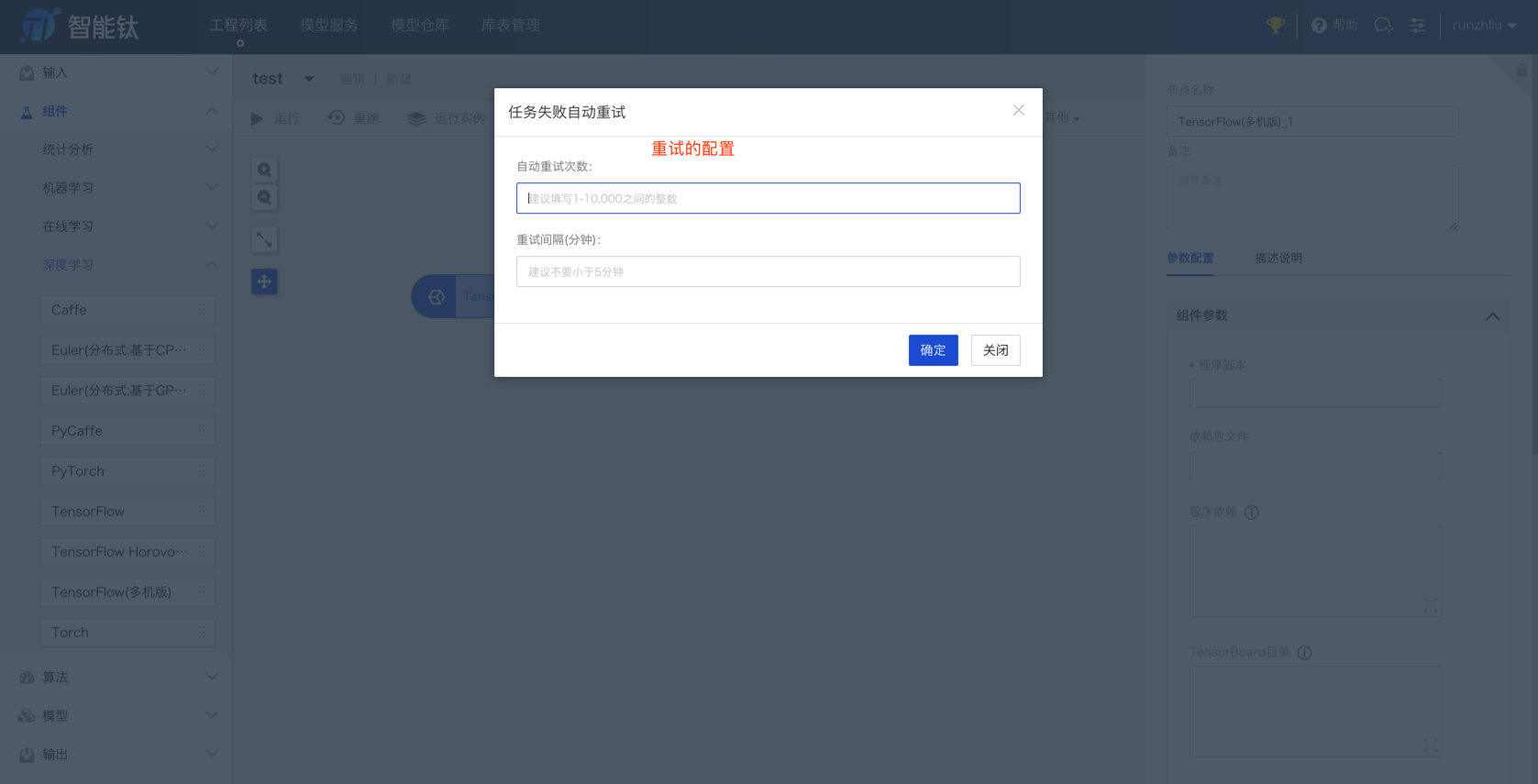
有很多状态的帮助,比如重试 retry 等等。
PPT 安排
1-3 Overview/DL是什么/K8S的支持
必看 Youtube 视频
https://www.youtube.com/watch?v=la_M6bCV91M
https://www.youtube.com/watch?v=-h0cWBiQ8s8
https://www.youtube.com/watch?v=bRMGoPqsn20
https://www.youtube.com/watch?v=Tw5AAGh_P7E
Distributed Tensorflow 使用指南
如何运行一个分布式Tensorflow示例程序
镜像来源于 tf-operator 的例子。
目前有效的示例镜像。
1
|
hub.oa.com/public/dist-tensorflow-mnist:v1.5.0
|
分布式分为 PS 架构和非 PS 架构。
1
|
hub.oa.com/public/dist-tensorflow-mnist:v1.5.0
|
参考资料
- 微信公众号的文章
- Youtube视频
- tf-operator的介绍
- tf-operator的设计文档
- tensorflow/ecosystem里面包含一些测试代码
- GPU通信技术
- Tensorflow团队的官方keras做分布式训练的文档
- vivo基于Kubernetes构建企业级TaaS平台实践
- TensorBoard可视化学习官方文档
- Tensorflow Serving的结合
- Serving ML Quickly with TensorFlow Serving and Docker
- Tesla的模型服务
- kubeflow的tf-serving模块
- 关于分布式Tensorflow的几个要点和基础知识补充
- in-graph和between-graph的正确理解
- Distributed Tensorflow的官方解释
- Distributed Tensorflow
- 陈迪豪的深度学习平台
- 非常赞的TF分布式讲解
Caicloud 关于 K8S 和分布式 tensorflow 的介绍
https://www.youtube.com/watch?v=yFXNASK0cPk
Aliyun 的 Kubeflow
https://www.youtube.com/watch?v=jyLi1cfJeM8&t=1471s
Data Parallelism 和 Model Parallelism 还有 Mesh Parallelism
https://www.youtube.com/watch?v=HgGyWS40g-g
警告
本文最后更新于 2017年2月1日,文中内容可能已过时,请谨慎参考。