Spark-Operator-Introduction
概述
Spark Operator 大概是在 2017 年下半年开始开发的,但是因为并不是 GCP 官方团队支持的项目,但是也还是由 GCP 的工程师来发开维护。所以目前看,国内没有大规模生产环境的使用案例(阿里云没有看到产品介绍)。

没有流行起来的原因,个人认为主要是以下几个原因:
- Spark 从 2.2 开始探索 on K8S 的方式,并且在 2.3 原生支持 K8S 的 ResouceManager,但是 on K8S 的支持大多数比较 base,不够稳定
- 大多数公司的大数据架构是和 Hadoop 生态深度耦合,这样会很多好处,最典型的就是计算和存储组件混部可以提高计算速度,K8S 也可以做到,但是显然生态还不够好
Design & Architecture
Spark Operator
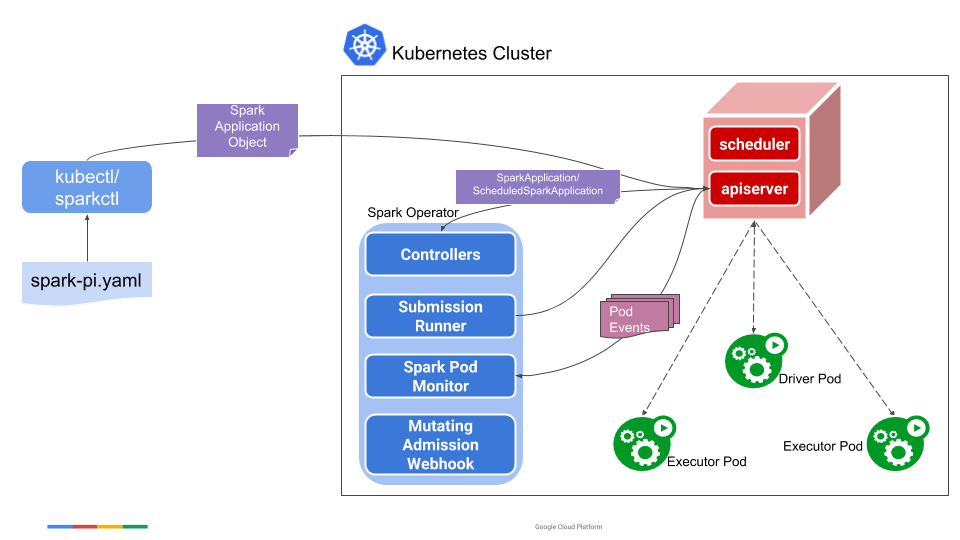
crd 目录下主要是定义的两个自定义资源 sparkapplication 和 scheduledsparkapplication 的结构。controller 目录下主要定义的就是这个 operator 的生命周期管理的逻辑;config 目录下主要处理 spark config 的转换。
sparkapplication 是对常规 Spark 任务的抽象,作业是单次运行的,作业运行完毕后,所有的 Pod 会进入 Succeed 或者 Failed 的状态。而 scheduledsparkapplication 是对离线定时任务的一种抽象,开发者可以在 scheduledsparkapplication 中定义类似 crontab 的任务,实现 Spark 离线任务的周期性定时调度。
Spark Operator 的状态机
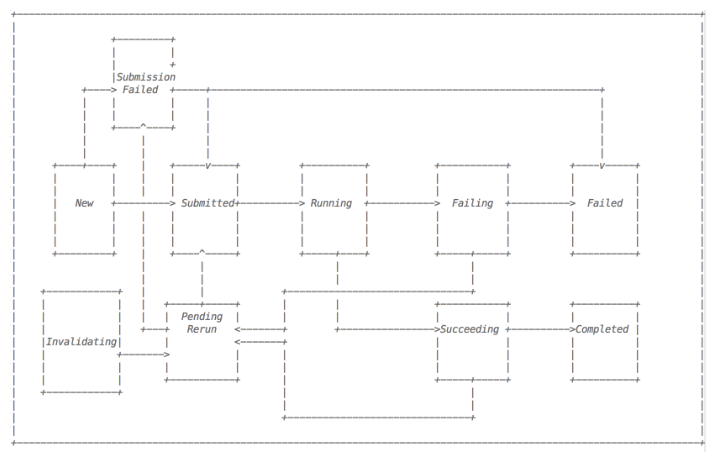
而当任务失败的时候会进行重试,若重试超过最大重试次数则会失败。也就是说如果在任务的执行过程中,由于资源、调度等因素造成Pod被驱逐或者移除,Spark Operator 都会通过自身的状态机状态转换进行重试。
一个 Spark 的作业任务可以通过上述的状态机转换图进行表示,一个正常的作业任务经历如下几个状态:
|
|
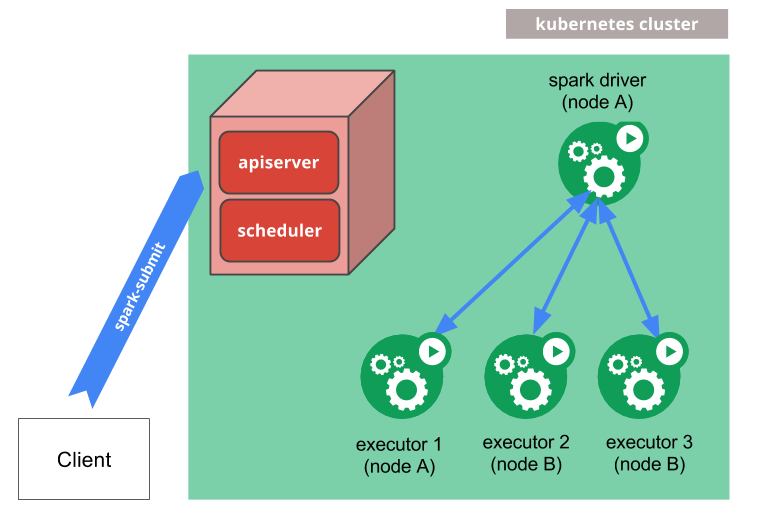
Spark Native
|
|
有限的 Job 管理方式,还是要通过 kubectl。2.2 是不支持 conf 中挂载指定的 volume 和 configmap 的。
spark-submit 可以运行 client 或者 cluster mode。区别在于 Driver 进程,前者是在 client 端的,后者可以运行在 K8S Pod 里。
Case by Case Comparison
Spark Operator & spark-submit
| Comparison | Spark Operator | spark-submit |
|---|---|---|
| Submit phase | kubectl | submssion failure |
| Run time | kubectl | kubectl |
| Definition | arbitrary | spark conf/image |
| Dynamic resource allocation | N/A | only 2.2 provided |
| Job management | kubectl | kubectl |
| Monitor | Great | N/A |
| Others | fllow updates for Spark | faster updates |
Spark Operator 相比于 Spark 提供的 K8S 支持,会有更多的好处。
- 非常 K8S Style
- 传统的 spark-submit 相比提供了更多的故障恢复与可靠性保障
- 提供了监控、日志、UI 等能力的集成与支持
Spark 2.2 & Spark 2.3 and Above
Spark 2.2 很多代码没有合进去 2.3 里,而且一直到 2.4 都是一些 base 级别的 K8S 支持。
Spark 2.3.0 Spark on Kubernetes: [SPARK-18278] A new kubernetes scheduler backend that supports native submission of spark jobs to a cluster managed by kubernetes. Note that this support is currently experimental and behavioral changes around configurations, container images and entrypoints should be expected.
Spark 2.4.0 Kubernetes Scheduler Backend [SPARK-23984] PySpark bindings for K8S [SPARK-24433] R bindings for K8S [SPARK-23146] Support client mode for Kubernetes cluster backend [SPARK-23529] Support for mounting K8S volumes
Spark 升级的问题。
- Spark 2.2 支持动态资源分配 Dynamic Resource Allocation,2.3 被移除了,主要是在 Shuffle 的时候需要本地文件系统的支持,并且当 Executor 挂掉之后可以 Shuffle Service 中恢复文件。2.2 的做法是每个 Node 部署一个 shuffle-service,2.3 认为方案不完美,被移除了。TenC 目前应该是没有使用的。
- Spark 2.3 对镜像进行了整合,现在只有一个 image,在镜像版本的控制上更省事。
- Spark 2.2 提供了 Resource Staging Server,可以提交本地文件,目前 TenC 是远程拉取的,问题应该不大。2.4 是不支持的。
总结
总体而言,Spark Operator 是把 Spark 跑在 K8S 上的最佳方案,目前支持 Spark 2.3 或以上。根据官方 RoadMap 来看,Spark 3.0 是会有一定改进,但是相信 Spark Operator 是会跟进集成的,光从 Job 的 Management 和 Monitor 看,Operator 的方式,显然是更 K8S 的。