Spark-Operator输出App-Metrics
目录
概述
Spark Operator 计算任务类型,底层和 Kubernetes 集成的方式是采用了 spark-on-k8s-operator
而本文主要是讲述,如何使用开箱即用的指标输出功能。
|
|
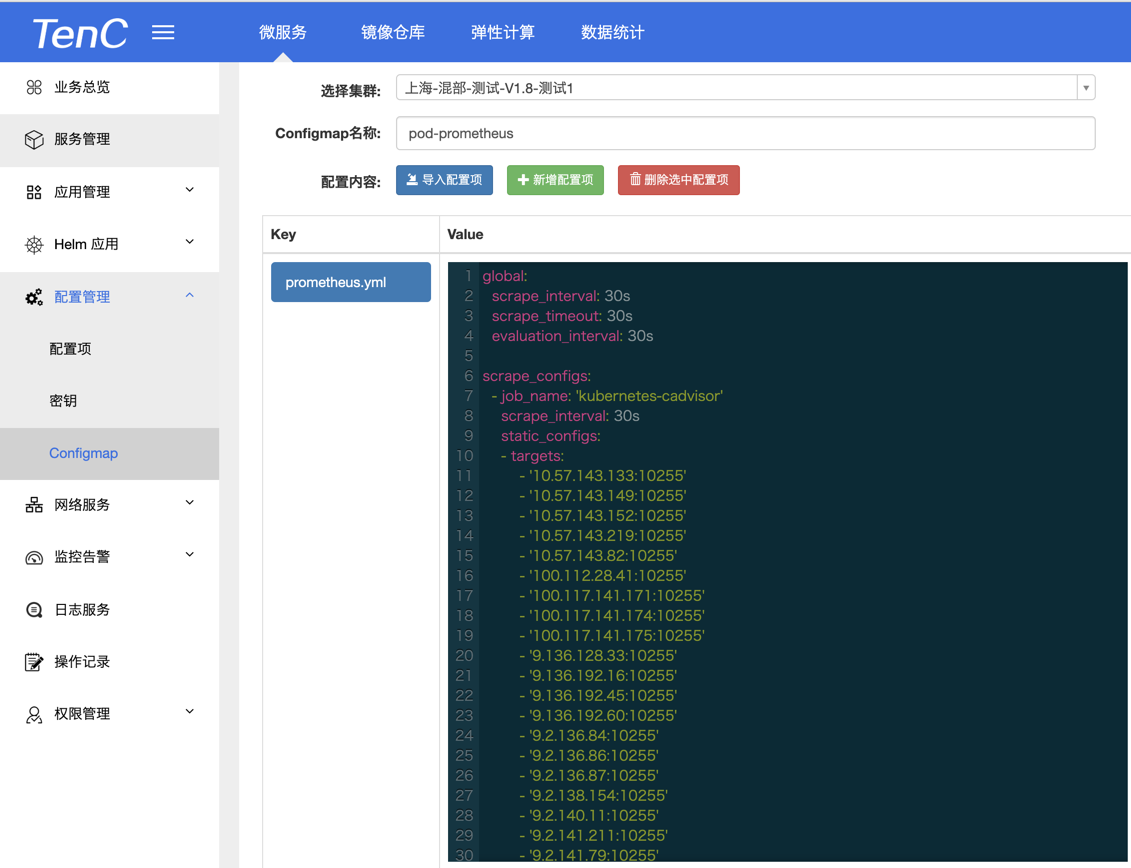
JMX 的 export port 定为 nodePort,固定到一个端口,由 promethues 都从这里拉出来数据。
主要是需要了解 JMX Exporter 的配置。
Prometheus 增加一个 Job Name。
/metrics 作为 endpoint 一般不需要怎么修改,是 Prometheus 的配置。
而且还需要考虑监控 Operator 本身。似乎是在 Spark Operator 起一个 Java Agent,然后去抓 Spark 的 metrics,而 Prometheus 只要从这个 IP 和 Host 拉取数据就可以?那么 Driver/Executor 的 Metrics 都会被这个 Java Agent 去拉数据。
问题是多个 Spark 应用,一个 Dashboard 够不够看。
Spark Operator 的参数。
- 多少个 Spark App
- 一个集群里所有 Spark App 包括 Driver/Executor 的 JVM 内存占用率,可以分不同 NameSpace,不同 Spark App Name。
感觉一些需要马上增加的 Dashboard。
- Task 为 Spark 的内存和 CPU 使用率,并且按 NameSpace 或者 Spark App Name 里区分。
- Spark App 运行的时间,超过1小时的有多,超过2小时的有多少。
- 同一个 Spark App 多次运行的时间对比,和当时集群的负载对比(数据量不一样怎么比较)。
- 统计 Spark App 申请更多 Executor 的情况,来说明 Pending Task 的影响。
我们想要证明一定,增加了动态资源申请的功能之后,Spark 任务的吞吐率提高了,运行效率更高了。但是因为业务集群的情况更加复杂,所以以单一任务的情况来统计。
另外就是 batch scheduler 的使用。
关于 Prometheus 的配置。
|
|
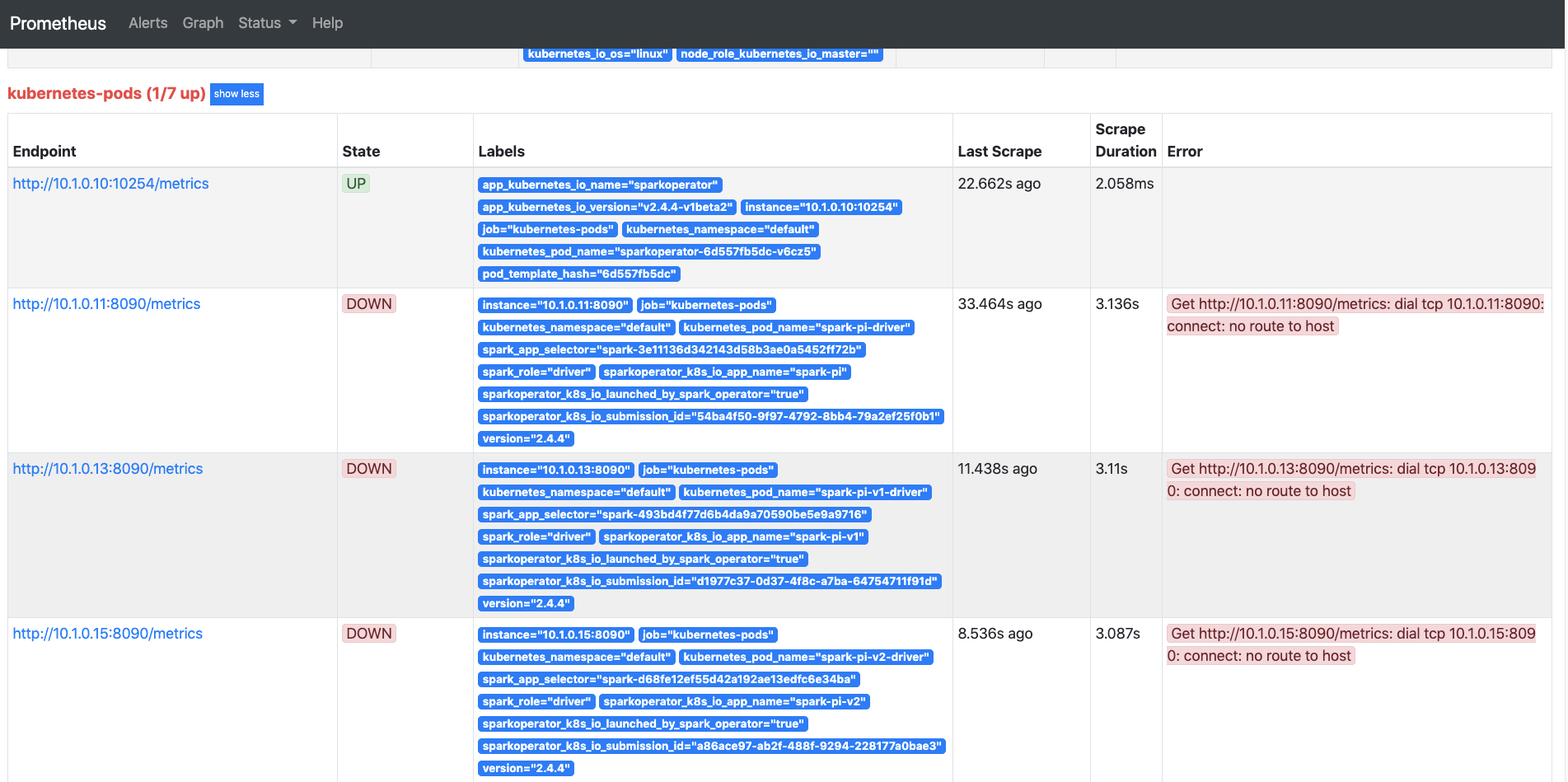
主要参考 Prometheus 的 kubenetes_sd_config。
也可以参考中文文档。

参考自: https://segmentfault.com/a/1190000013230914

警告
本文最后更新于 2019年10月9日,文中内容可能已过时,请谨慎参考。