Spark-Operator记录
概述
Google 了一下,目前关于 Spark Operator 的讨论还比较少。
|
|
- sparkapplication 是对常规spark任务的抽象,作业是单次运行的,作业运行完毕后,所有的 Pod 会进入 Succeed 或者 Failed 的状态。
- scheduledsparkapplication 是对离线定时任务的一种抽象,开发者可以在 scheduledsparkapplication 中定义类似 crontab 的任务,实现 Spark 离线任务的周期性定时调度。
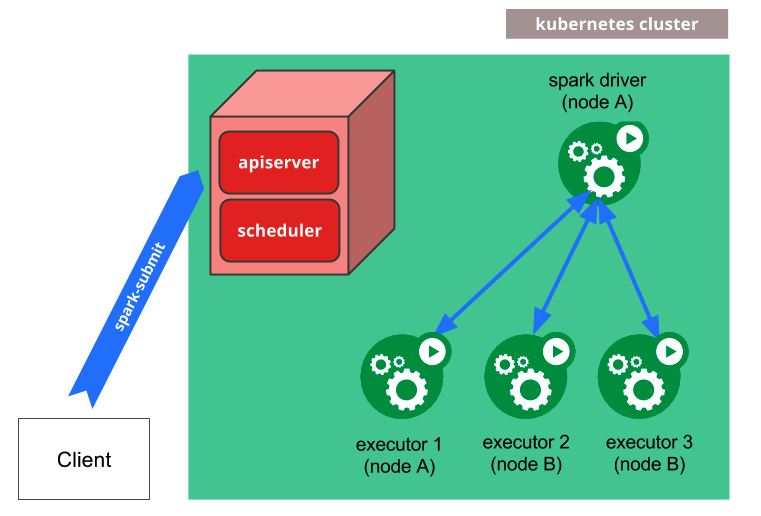
这张图是 Spark Operator 的流程图,在上面的操作中,第一个步骤里面,实际上是将图中的中心位置蓝色的 Spark Operator 安装到集群中,Spark Operator 本身即是是一个 CRD 的 Controller 也是一个 Mutating Admission Webhook 的 Controller。当我们下发 spark-pi 模板的时候,会转换为一个名叫 SparkApplication 的 CRD 对象,然后 Spark Operator 会监听 Apiserver,并将 SparkApplication 对象进行解析,变成 spark-submit 的命令并进行提交,提交后会生成 Driver Pod,用简单的方式理解,Driver Pod 就是一个封装了 Spark Jar 的镜像。如果是本地任务,就直接在 Driver Pod 中执行;如果是集群任务,就会通过 Driver Pod 再生成 Exector Pod 进行执行。当任务结束后,可以通过 Driver Pod 进行运行日志的查看。此外在任务的执行中,Spark Operator 还会动态 attach 一个 Spark UI 到 Driver Pod 上,希望查看任务状态的开发者,可以通过这个 UI 页面进行任务状态的查看。
其实到此,我们就已经基本了解 Spark Operator 做的事情了,首先定义了两种不同的 CRD 对象,分别对应普通的计算任务与定时周期性的计算任务,然后解析 CRD 的配置文件,拼装成为 spark-submit 的命令,通过 prometheus 暴露监控数据采集接口,创建 Service 提供 spark-ui 的访问。然后通过监听 Pod 的状态,不断回写更新 CRD 对象,实现了 Spark 作业任务的生命周期管理。
使用 Spark Operator 是在 K8S 上实践 Spark 的最佳方式,和传统的 spark-submit 相比提供了更多的故障恢复与可靠性保障,并且提供了监控、日志、UI等能力的集成与支持。