概述
https://databricks.com/session/apache-spark-on-k8s-and-hdfs-security
Spark 从2.3开始支持 Native 的 K8S 作为 resourceManager 了,官网内容很多,就不赘述了,这里主要参考2018年的 Spark Submit 一个 Share,来尝试搭建一套做大数据计算时候经常碰到的一种场景: K8S 化的 Spark Job 和 HDFS 交互。
Practice
Share 中有作者分享的几个 github 地址,非常有用,分别是本地部署一个 Kerberized HDFS,以及部署 Spark Pi 作业,当然了 Keytab 是在 HDFS 上的,因此需要访问到 HDFS。
1
2
|
secure-hdfs-test: https://github.com/ifilonenko/secure-hdfs-test
hadoop-kerberos-helm: https://github.com/ifilonenko/hadoop-kerberos-helm
|
前提条件
这两个项目要部署起来,需要一些前提条件。
- Docker For Mac
- Enable Kubernetes
- 足够的内存和 CPU
首先,看看 Docker For Mac 关于 Kubernetes 的一些配置。

配置好本地的 Docker For Mac 之后,尝试部署一个 K8S 的集群,具体方法,这里就不列举了,分享一个很详细的教程,来自阿里云的。
https://github.com/AliyunContainerService/k8s-for-docker-desktop
好了,部署好集群之后,我们试一下下面的命令。
1
2
3
4
5
|
# kubectl cluster-info
Kubernetes master is running at https://localhost:6443
KubeDNS is running at https://localhost:6443/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.
|
可以看到 K8S 集群的一些信息,这里最主要是要记得 master 的地址。然后顺便安装换一下 K8S dashboard。
部署Kerberized HDFS
Kerberized HDFS 顾名思义,就是需要 Kerberos 验证的 HDFS 集群。访问 HDFS 的集群的机器都需要一个叫做 Keytab 的一个东西,也就是说,Spark Job 需要传入 Keytab 才可以读写 HDFS。
先剖析一下 hadoop-kerberos-helm 里都有些什么文件。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
# tree
.
├── Dockerfile // HDFS 的 Dockerfile
├── README.md
├── core-site.xml
├── datanode
│ ├── Chart.yaml
│ └── templates
│ ├── dn1-deployment.yml
│ └── dn1-service.yml
├── datapopulator
│ ├── Chart.yaml
│ └── templates
│ ├── data-populator-deployment.yml
│ └── data-populator-service.yml
├── hadoop-2.7.3.tar.gz // 这个需要提前下载或者自行编译
├── hdfs-site.xml
├── kdc
│ ├── Chart.yaml //
│ └── templates
│ ├── kerberos-deployment.yml //
│ └── kerberos-service.yml //
├── krb5.conf //
├── log4j.properties
├── namenode
│ ├── Chart.yaml
│ └── templates
│ ├── nn-deployment.yml
│ └── nn-service.yml
├── people.json
├── people.txt
├── populate-data.sh
├── pv
│ ├── Chart.yaml
│ └── templates
│ ├── namenode-hadoop-pv.yaml
│ ├── namenode-hadoop.yml
│ ├── server-keytab-pv.yaml
│ └── server-keytab.yaml
├── ssl-server.xml
├── start-datanode.sh
├── start-kdc.sh
├── start-namenode.sh
├── teardown.sh
└── yarn-site.xml
|
hadoop-kerberos-helm 里内容比较多,总结起来,其实就是打包了部署一个 HDFS 集群的一些 yaml 文件,以 Chart 作为管理。
关于这个如何用 K8S 部署一个 Kerberized HDFS,我后面会再写一篇文章解释一下。部署的顺序,可以理解成这样。
- 部署 KDC 服务(Kerberos 验证服务器)
- 部署 NameNode
- 部署 DataNode
- 将文件 put 到 HDFS 中。
关于 Kerberos 的学习资料,网上有很多。我之前看的时候主要是参考以下博客
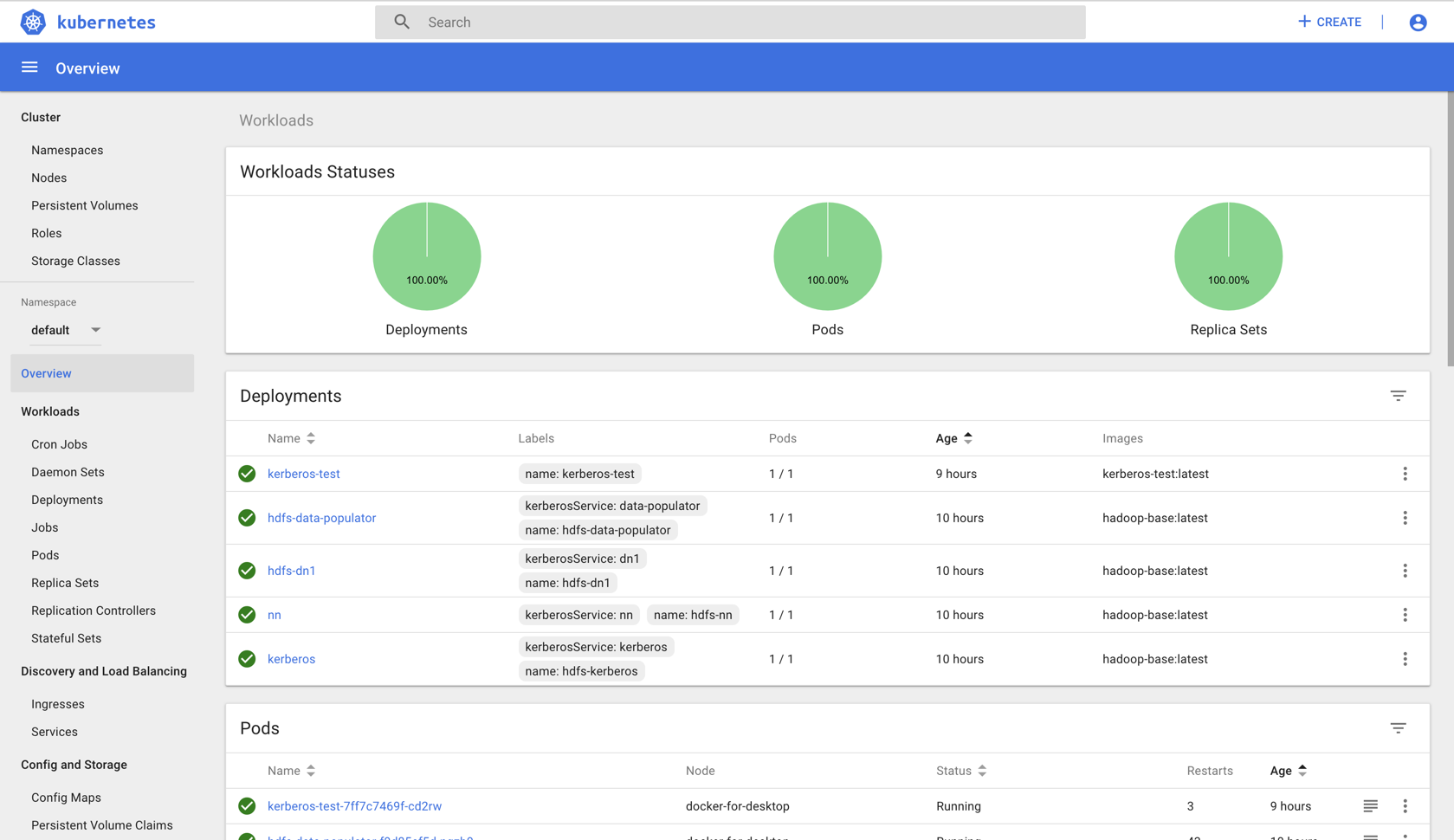
所以,最后部署好后,可以看看结果。
然后就是起一个 Pod,我们进入这个 Pod 里来运行 spark-submit。
然后大家看一下 secure-hdfs-test 这个项目的构成。
1
2
3
4
5
6
7
8
9
10
11
12
|
# tree
.
├── Dockerfile
├── README.md
├── core-site.xml // Kerberized HDFS 的配置
├── hdfs-site.xml // Kerberized HDFS 的配置
├── kerberos-test-deployment.yml
├── krb5.conf // Kerberized HDFS 的配置
├── spark-examples_2.11-2.2.0-k8s-0.5.0.jar // 作业 jar 包
├── ssl-server.xml // Kerberized HDFS 的配置
├── test-env.sh // 容器里运行的
└── yarn-site.xmla // Kerberized HDFS 的配置
|
Spark程序访问HDFS
这个项目更简单一些,大家可以看看 Dockerfile,其实就是到容器里去执行 test-env.sh 这个脚本而已,看看这个脚本的内容。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
#!/usr/bin/env bash
sed -i -e 's/#//' -e 's/default_ccache_name/# default_ccache_name/' /etc/krb5.conf
export HADOOP_OPTS="-Djava.net.preferIPv4Stack=true -Dsun.security.krb5.debug=true"
export HADOOP_JAAS_DEBUG=true
export HADOOP_ROOT_LOGGER=DEBUG,console
export NAMESPACE=default
# Spark 运行需要配置 Hadoop 的配置文件位置,如果 ClassPath 没有,则无法访问 HDFS
export HADOOP_CONF_DIR=/opt/spark/hconf
# Kerberos 相关配置
mkdir -p /etc/krb5.conf.d
until /usr/bin/kinit -kt /var/keytabs/hdfs.keytab hdfs/nn.${NAMESPACE}.svc.cluster.local; do sleep 15; done
/opt/spark/bin/spark-submit \
--deploy-mode cluster \
--class org.apache.spark.examples.HdfsTest \
--master k8s://10.96.0.1:443 \
--kubernetes-namespace ${NAMESPACE} \
--conf spark.executor.instances=1 \
--conf spark.app.name=spark-hdfs \
--conf spark.driver.extraClassPath=/opt/spark/hconf/core-site.xml:/opt/spark/hconf/hdfs-site.xml:/opt/spark/hconf/yarn-site.xml:/etc/krb5.conf \
--conf spark.kubernetes.driver.docker.image=spark-driver:latest \
--conf spark.kubernetes.executor.docker.image=spark-executor:latest \
--conf spark.kubernetes.initcontainer.docker.image=spark-init:latest \
--conf spark.kubernetes.kerberos.enabled=true \
--conf spark.kubernetes.kerberos.keytab=/var/keytabs/hdfs.keytab \
--conf spark.kubernetes.kerberos.principal=hdfs/nn.${NAMESPACE}.svc.cluster.local@CLUSTER.LOCAL \
local:///opt/spark/examples/jars/spark-examples_2.11-2.2.0-k8s-0.5.0.jar \
hdfs://nn.${NAMESPACE}.svc.cluster.local:9000/user/ifilonenko/people.
|
然后 kubectl create -f kerberos-test-deployment.yml,这样之后,这个 Pod 就起来了。
1
2
3
4
5
6
7
|
# kubectl get pods
NAME READY STATUS RESTARTS AGE
hdfs-data-populator-f9d85cf5d-nqzb9 1/1 Running 0 1d
hdfs-dn1-fdbb479d6-mkngt 1/1 Running 0 1d
kerberos-86b44bf796-dq4d8 1/1 Running 0 1d
kerberos-test-7ff7c7469f-cd2rw 1/1 Running 0 1d
nn-644bb56d5b-rbmk9 1/1 Running 0 1d
|
通过 exec 进入容器,运行脚本,如果一切顺利,就会得到下面的结果。记住,要看到使用了那个 principal 和 keytab,成功认证后,才能访问到 HDFS,也才会有下面的日志,否则就需要排查问题了(一般问题都在 KDC 的 Pod 日志可以查到)。
1
2
3
4
5
6
|
2019-06-02 15:01:30 WARN NativeCodeLoader:62 - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Debug is true storeKey true useTicketCache false useKeyTab true doNotPrompt true ticketCache is null isInitiator true KeyTab is /var/keytabs/hdfs.keytab refreshKrb5Config is true principal is hdfs/nn.default.svc.cluster.local@CLUSTER.LOCAL tryFirstPass is false useFirstPass is false storePass is false clearPass is false
Refreshing Kerberos configuration
principal is hdfs/nn.default.svc.cluster.local@CLUSTER.LOCAL
Will use keytab
Commit Succeeded
|
总结
Kerberos 的配置是真的挺麻烦的……但你总要适应哪一天你的运维同学告诉你说你不能以不安全的方式来访问 HDFS,那么你迟早要搞这一套。
Spark on K8S 访问上,其实没太多的 trick,都集中在 Kerberos 认证的问题上,往往是 token 过期,造成无法访问,至于 long-running 还是 short-running,需求是不一样的,短任务一般24小时可以跑完,常驻任务需要跑超过24小时甚至7天,这时候就要去 renew 你的 Keytab 了,具体怎么做,没有通用的标准,各位可以按照自己的思路配合业务进行尝试。
警告
本文最后更新于 2017年2月1日,文中内容可能已过时,请谨慎参考。