概述
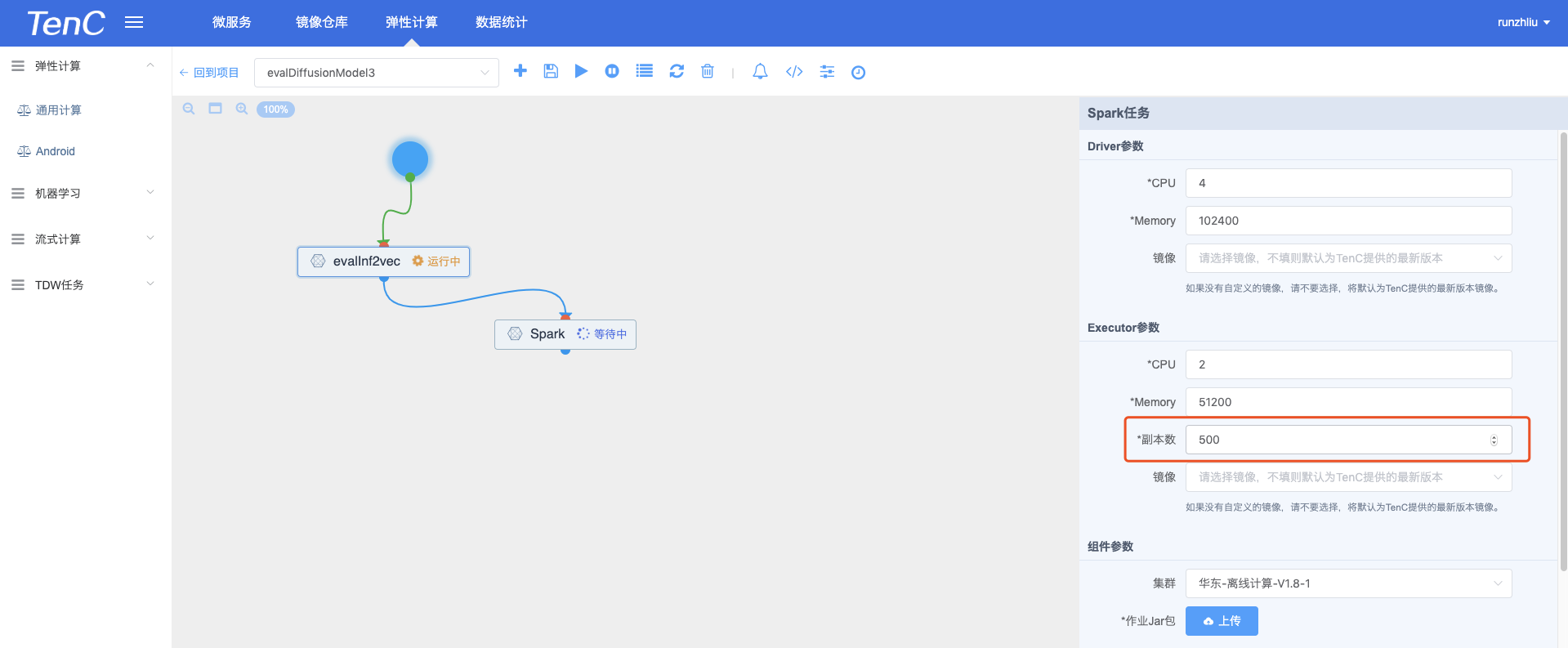
目前离线计算的 Spark 任务中,会提供「最小副本数」作为离线计算任务的 Executor 数,如下图。

也就是说,这个 Spark Job 最大的资源数就是500个 Executor,这样会导致 task 数量较多的任务一直在等待资源,并发度其实是被限制的,当然,写成1000个,也可能会导致资源浪费的问题。task 数量多,并行处理数为 cores * executors = 2 * 500 = 1000,也就是说同时处理1000个 task。
on Yarn 很早就提供了 Dynamic Resource Allocation(DRA),Spark Executor 可以根据 workload(task 数量) 进行 scale。所以就不用填这个参数了,spark.executor.instances。
Spark 2.2 on K8S 提供了一种 shuffle service 的实现,可以支持 DRA。
实践
spark shuffle service
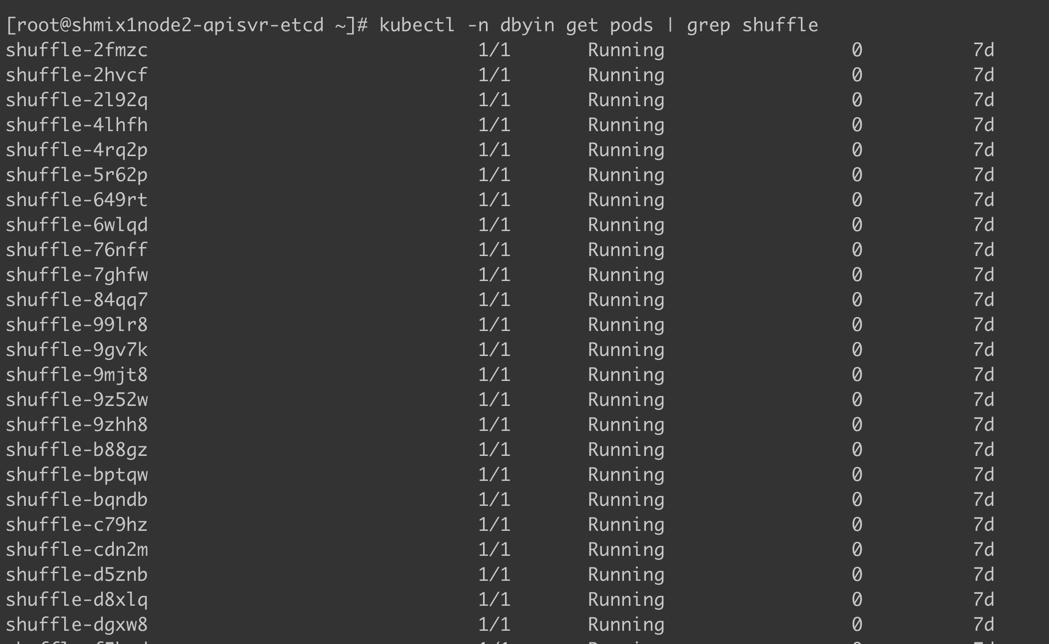
部署 Spark shuffle service 的 DaemonSet。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
apiVersion: extensions/v1beta1
kind: DaemonSet
metadata:
labels:
app: spark-shuffle-service
spark-version: 2.2.0
name: shuffle
spec:
template:
metadata:
labels:
app: spark-shuffle-service
spark-version: 2.2.0
spec:
volumes:
- name: temp-volume
hostPath:
# 本地 cache/shuffle 的地址
path: '/tmp/spark-local' # change this path according to your cluster configuration.
containers:
- name: shuffle
# This is an official image that is built
# from the dockerfiles/shuffle directory
# in the spark distribution.
image: kubespark/spark-shuffle:v2.2.0-kubernetes-0.4.0
imagePullPolicy: IfNotPresent
volumeMounts:
- mountPath: '/tmp/spark-local'
name: temp-volume
# more volumes can be mounted here.
# The spark job must be configured to use these
# mounts using the configuration:
# spark.kubernetes.shuffle.dir=<mount-1>,<mount-2>,...
resources:
requests:
cpu: "1"
limits:
cpu: "1"
|
spark groupbytest
测试一个 shuffle 程序,测试脚本如下。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
bin/spark-submit \
--deploy-mode cluster \
--class org.apache.spark.examples.GroupByTest \
--master=k8s://https://kubernetes.default.svc \
--kubernetes-namespace runzhliu \
--conf spark.local.dir=/tmp/spark-local \
--conf spark.app.name=group-by-test \
--conf spark.dynamicAllocation.enabled=true \
# shuffle 启动
--conf spark.shuffle.service.enabled=true \
--conf spark.kubernetes.shuffle.namespace=runzhliu \
--conf spark.kubernetes.shuffle.labels="app=spark-shuffle-service,spark-version=2.2.0" \
# spark.dynamicAllocation.minExecutors - Lower bound on the number of executors
--conf spark.dynamicAllocation.minExecutors=13 \
# spark.dynamicAllocation.maxExecutors - Upper bound on the number of executors
--conf spark.dynamicAllocation.maxExecutors=20 \
# spark.dynamicAllocation.initialExecutors - Number of executors to start with
--conf spark.dynamicAllocation.initialExecutors=13 \
--conf spark.kubernetes.driver.docker.image=spark-driver-runzhliu:0.0.2 \
--conf spark.kubernetes.executor.docker.image=spark-executor-runzhliu:0.0.2 \
local:///opt/spark/examples/jars/spark-examples_2.11-2.2.0-k8s-0.5.0.jar 10 4000000 2
|
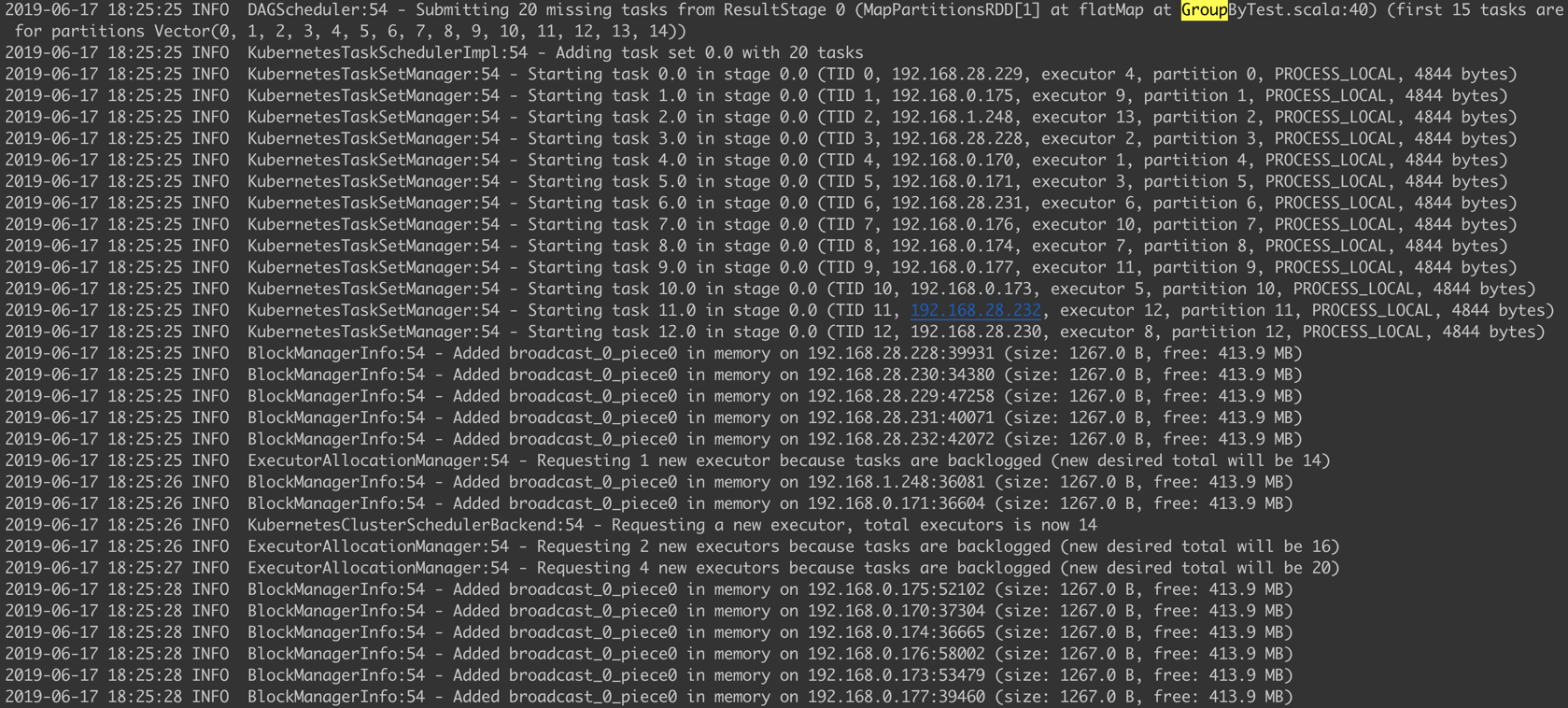
查看日志,Spark 启动的 Executor 按照最小值启动 13 个(默认10个)。
随便调整一下 GroupByTest 的参数,让他的 task 更多。就会启动20个 Executor 了。
总结
DRA 有个很合适的场景,就是用在流计算当中。当数据流有较大幅度的波动的时候,开启这个特性,可以让 Spark 根据自身的 workload 来调整 Executor 的数量,task 可以被调度到更多的 Executor 中。另外,在一些机器学习的场景中,以及 Spark SQL 中,这个特性都能带来资源的更好的利用率。
警告
本文最后更新于 2017年2月1日,文中内容可能已过时,请谨慎参考。