Spark面试
Kafka分布式的情况下,如何保证消息的顺序
Kafka 分布式的单位是 Partition。如何保证消息有序,需要分几个情况讨论。
- 同一个 Partition 用一个 write ahead log 组织,所以可以保证 FIFO 的顺序,可以保证消息在同一分区的顺序。
- 不同 Partition 之间不能保证顺序。但是绝大多数用户都可以通过 message key 来定义,因为同一个 key 的 message 可以保证只发送到同一个 Partition。比如说 key 是 user id,table row id 等等,所以同一个 user 或者同一个 record 的消息永远只会发送到同一个 Partition上,这样就保证了同一个 user 或 record 的消息的顺序。
- 当然,如果你有 key skewness 就有些麻烦,会导致某些 Partition 非常大,这时候就需要特殊处理了。
From: https://blog.csdn.net/chunlongyu/article/details/53977819
实际情况中: (1)不关注所有消息的全部顺序的业务大量存在,比如说不同用户消息的绝对顺序 (2)队列无序不代表消息无序
第(2)条的意思是说: 我们不保证队列的全局有序,但可以保证消息的局部有序。举个例子: 保证来自同1个 order id 的消息,是有序的。
Kafka 中发送1条消息的时候,可以指定 (topic, partition, key) 3个参数。Partition 和 Key 是可选的。如果你指定了 Partition,那就是所有消息发往同1个 Partition,就是有序的。并且在消费端,Kafka 保证,1个 partition 只能被1个 consumer 消费。或者你指定 key(比如 order id),具有同1个 key 的所有消息,会发往同1个 partition。也是有序的。
对于Spark中的数据倾斜问题你有什么好的方案
先了解什么是数据倾斜。什么是数据倾斜? 对 Spark/Hadoop 这样的大数据系统来讲,数据量大并不可怕,可怕的是数据倾斜。数据倾斜指的是,并行处理的数据集中,某一部分(如 Spark 或 Kafka 的一个 Partition)的数据显著多于其它部分,从而使得该部分的处理速度成为整个数据集处理的瓶颈(木桶效应)。
简单一句: Spark 数据倾斜的几种场景以及对应的解决方案,包括:
- 避免数据源倾斜(源头)
- 调整并行度
- 使用自定义 Partitioner
- 使用 Map 侧 Join 代替 Reduce 侧 Join(内存表合并)
- 给倾斜 Key 加上随机前缀等
数据倾斜是如何造成的 在 Spark 中,同一个 Stage 的不同 Partition 可以并行处理(也可以理解是一个 Task 一个 Partition),而具有依赖关系的不同 Stage 之间是串行处理的。假设某个 Spark Job 分为 Stage 0和 Stage 1两个 Stage,且 Stage 1依赖于 Stage 0,那 Stage 0完全处理结束之前不会处理Stage 1。而 Stage 0可能包含 N 个 Task,这 N 个 Task 可以并行进行。如果其中 N-1个 Task 都在10秒内完成,而另外一个 Task 却耗时1分钟,那该 Stage 的总时间至少为1分钟。换句话说,一个 Stage 所耗费的时间,主要由最慢的那个 Task 决定。由于同一个 Stage 内的所有 Task 执行相同的计算,在排除不同计算节点计算能力差异的前提下,不同 Task 之间耗时的差异主要由该 Task 所处理的数据量决定。所以不要让某些节点承载特别巨大的数据计算量。
具体解决方案
- 调整并行度分散同一个 Task 的不同 Key: Spark 在做 Shuffle 时,默认使用
HashPartitioner对数据进行分区。如果并行度设置的不合适,可能造成大量不相同的 Key 对应的数据被分配到了同一个 Task 上,造成该 Task 所处理的数据远大于其它 Task,这就会造成数据倾斜,这个可能是最常见的原因了。如果调整 Shuffle 时的并行度,意思就是原来要求并行度为2,也就是分出2个 Task,现在调整并行度变成3,使得原本被分配到同一 Task 的不同 Key 可以发配到不同 Task 上处理,则可降低原 Task 所需处理的数据量,从而缓解数据倾斜问题造成的短板效应。图中左边绿色框表示 kv 样式的数据,key 可以理解成 name。可以看到 Task0 分配了许多的 key,调整并行度,多了几个 Task,那么每个 Task 处理的数据量就分散了。
- 自定义Partitioner: 使用自定义的 Partitioner(默认为
HashPartitioner),将原本被分配到同一个 Task 的不同 Key 分配到不同 Task,可以拿上图继续想象一下,通过自定义 Partitioner 可以把原本分到 Task0 的 Key 分到 Task1,那么 Task0 的要处理的数据量就少了。 - 将 Reduce side(侧) Join 转变为 Map side(侧) Join: 通过 Spark 的 Broadcast 机制,将 Reduce 侧 Join 转化为 Map 侧 Join,避免 Shuffle 从而完全消除 Shuffle 带来的数据倾斜。可以看到 RDD2 被加载到内存中了。
- 为 skew 的 key 增加随机前/后缀: 为数据量特别大的 Key 增加随机前/后缀,使得原来 Key 相同的数据变为 Key 不相同的数据,从而使倾斜的数据集分散到不同的 Task 中,彻底解决数据倾斜问题。Join 另一侧的数据中,与倾斜 Key 对应的部分数据,与随机前缀集作笛卡尔乘积,从而保证无论数据倾斜侧倾斜 Key 如何加前缀,都能与之正常 Join。
- 大表随机添加 N 种随机前缀,小表扩大 N 倍: 如果出现数据倾斜的 Key 比较多,上一种方法将这些大量的倾斜 Key 分拆出来,意义不大(很难一个 Key 一个 Key 都加上后缀)。此时更适合直接对存在数据倾斜的数据集全部加上随机前缀,然后对另外一个不存在严重数据倾斜的数据集整体与随机前缀集作笛卡尔乘积(即将数据量扩大 N 倍),可以看到 RDD2 扩大了 N 倍了,再和加完前缀的大数据做笛卡尔积。




Spark有哪些聚合类的算子,我们应该尽量避免什么类型的算子
在我们的开发过程中,能避免则尽可能避免使用 reduceByKey、join、distinct、repartition 等会进行 shuffle 的算子,尽量使用 map 类的非 shuffle 算子。这样的话,没有 shuffle 操作或者仅有较少 shuffle 操作的 Spark 作业,可以大大减少性能开销。相关例子可以参考这篇文章。
Spark on Yarn作业执行流程,yarn-client和yarn cluster有什么区别
Spark On Yarn 的优势
- Spark 支持资源动态共享(目前 Spark 3.0.0 已经支持 on K8S 的动态资源分配),运行于 Yarn 的框架都共享一个集中配置好的资源池
- 可以很方便的利用 Yarn 的资源调度特性来做分类·,隔离以及优先级控制负载,拥有更灵活的调度策略
- Yarn 可以自由地选择 Executor 数量
- Yarn 支持 Spark 安全的集群管理器,使用 Yarn,Spark 可以运行于 Kerberized Hadoop 之上,在它们进程之间进行安全认证
yarn-client 和 yarn cluster 的异同 可以分两个层面来解释这个问题。
- 从广义上讲,yarn-cluster 适用于生产环境。而 yarn-client 适用于交互和调试,也就是希望快速地看到 application 的输出。
- 从深层次的含义讲,yarn-cluster 和 yarn-client 模式的区别其实就是 Application Master 进程的区别,yarn-cluster 模式下,driver 运行在 AM(Application Master)中,它负责向 YARN 申请资源,并监督作业的运行状况。当用户提交了作业之后,就可以关掉 Client,作业会继续在 YARN 上运行。然而 yarn-cluster 模式不适合运行交互类型的作业。而 yarn-client 模式下,Application Master 仅仅向 YARN 请求 executor,Client 会和请求的 Container 通信来调度他们工作,也就是说 Client 不能离开。
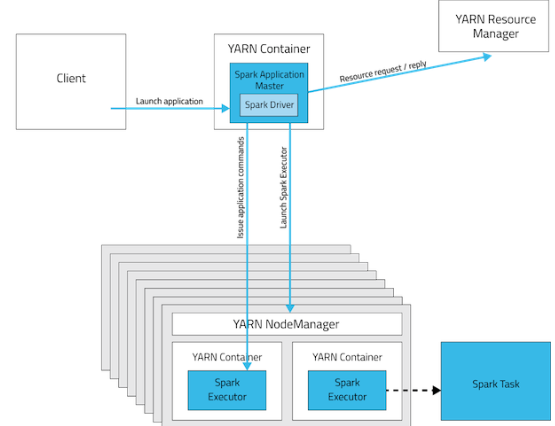
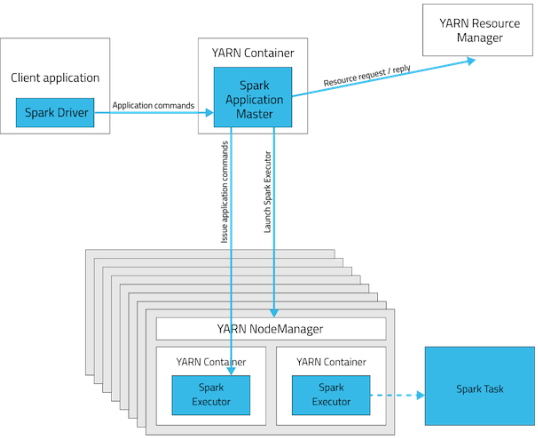
Spark粗粒度和细粒度
如果问的是操作的粗细粒度,应该是,Spark 在错误恢复的时候,只需要粗粒度的记住 lineage,就可实现容错。
关于 Mesos
- 粗粒度模式(Coarse-grained Mode): 每个应用程序的运行环境由一个 driver 和若干个 executor 组成,其中,每个 executor 占用若干资源,内部可运行多个 task(对应多少个 slot)。应用程序的各个任务正式运行之前,需要将运行环境中的资源全部申请好,且运行过程中要一直占用这些资源,即使不用,最后程序运行结束后,回收这些资源。举个例子,比如你提交应用程序时,指定使用5个 executor 运行你的应用程序,每个 executor 占用5GB内存和5个 CPU,每个 executor 内部设置了5个 slot(可以运行5哥 task),则 Mesos 需要先为 executor 分配资源并启动它们,之后开始调度任务。另外,在程序运行过程中,Mesos 的 master 和 slave 并不知道 executor 内部各个 task 的运行情况,executor 直接将任务状态通过内部的通信机制汇报给 driver,从一定程度上可以认为,每个应用程序利用 Mesos 搭建了一个虚拟集群自己使用。
- 细粒度模式(Fine-grained Mode): 鉴于粗粒度模式会造成大量资源浪费,Spark On Mesos 还提供了另外一种调度模式:细粒度模式,这种模式类似于现在的云计算,思想是按需分配。与粗粒度模式一样,应用程序启动时,先会启动 executor,但每个 executor 占用资源仅仅是自己运行所需的资源,不需要考虑将来要运行的任务,之后,Mesos 会为每个 executor 动态分配资源,每分配一些,便可以运行一个新任务 Task,单个 Task 运行完之后可以马上释放对应的资源。每个 Task 会汇报状态给 Mesos slave 和 Mesos Master,便于更加细粒度管理和容错,这种调度模式类似于 MapReduce 调度模式,每个 Task 完全独立,优点是便于资源控制和隔离,但缺点也很明显,短作业运行延迟大。
Spark中,每个 Application 对应一个 SparkContext。对于 SparkContext 之间的调度关系,取决于 Spark 的运行模式。对 Standalone 模式而言,Spark Master 节点先计算集群内的计算资源能否满足等待队列中的应用对内存和 CPU 资源的需求,如果可以,则 Master 创建 Spark Driver,启动应用的执行。宏观上来讲,这种对应用的调度类似于 FIFO 策略。在 Mesos 和 Yarn 模式下,底层的资源调度系统的调度策略都是由 Mesos 和 Yarn 决定的。具体分类描述如下:
- Standalone 模式: 默认以用户提交 Applicaiton 的顺序来调度,即 FIFO 策略。每个应用执行时独占所有资源。如果有多个用户要共享集群资源,则可以使用参数
spark.cores.max来配置应用在集群中可以使用的最大 CPU 核的数量。如果不配置,则采用默认参数spark.deploy.defaultCore的值来确定。 - Mesos 模式: 如果在 Mesos 上运行 Spark,用户想要静态配置资源的话,可以设置
spark.mesos.coarse为 true,这样 Mesos 变为粗粒度调度模式。然后可以设置spark.cores.max指定集群中可以使用的最大核数,与上面 Standalone 模式类似。同时,在 Mesos 模式下,用户还可以设置参数spark.executor.memory来配置每个 executor 的内存使用量。如果想使 Mesos 在细粒度模式下运行,可以通过mesos://<url-info>设置动态共享 CPU core 的执行模式。在这种模式下,应用不执行时的空闲 CPU 资源得以被其他用户使用,提升了 CPU 使用率。
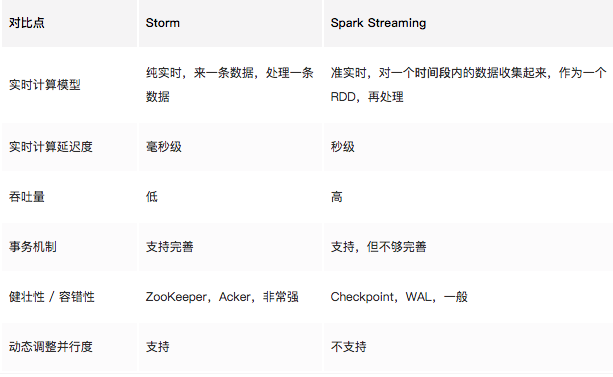
Spark Streaming工作流程是怎么样的,和Storm比有什么区别
Spark Streaming 与 Storm 都可以用于进行实时流计算。但是他们两者的区别是非常大的。其中区别之一,就是,Spark Streaming 和 Storm 的计算模型完全不一样,Spark Streaming 是基于 RDD 的,因此需要将一小段时间内的,比如1秒内的数据,收集起来,作为一个 RDD,然后再针对这个 batch 的数据进行处理。而 Storm 却可以做到每来一条数据,都可以立即进行处理和计算。因此,Spark Streaming 实际上严格意义上来说,只能称作准实时的流计算框架;而 Storm 是真正意义上的实时计算框架。 此外,Storm 支持的一项高级特性,是 Spark Streaming 暂时不具备的,即 Storm 支持在分布式流式计算程序(Topology)在运行过程中,可以动态地调整并行度,从而动态提高并发处理能力。而 Spark Streaming 是无法动态调整并行度的。 但是 Spark Streaming 也有其优点,首先 Spark Streaming 由于是基于 batch 进行处理的,因此相较于 Storm 基于单条数据进行处理,具有数倍甚至数十倍的吞吐量。 此外,Spark Streaming 由于也身处于 Spark 生态圈内,因此Spark Streaming可以与Spark Core、Spark SQL,甚至是Spark MLlib、Spark GraphX进行无缝整合。流式处理完的数据,可以立即进行各种map、reduce转换操作,可以立即使用sql进行查询,甚至可以立即使用machine learning或者图计算算法进行处理。这种一站式的大数据处理功能和优势,是Storm无法匹敌的。 因此,综合上述来看,通常在对实时性要求特别高,而且实时数据量不稳定,比如在白天有高峰期的情况下,可以选择使用Storm。但是如果是对实时性要求一般,允许1秒的准实时处理,而且不要求动态调整并行度的话,选择Spark Streaming是更好的选择。
补充一个比较好的比较文章,有时间可以看一下。
Spark机器学习和Spark图计算接触过没有,能举例说明你用它做过什么吗?
Spark 提供了很多机器学习库,我们只需要填入数据,设置参数就可以用了。使用起来非常方便。 另外一方面,由于它把所有的东西都写到了内部,我们无法修改其实现过程。要想修改里面的某个环节,还的修改源码,重新编译。 比如 Kmeans 算法,如果没有特殊需求,很方便。但是 Spark 内部使用的两个向量间的距离是欧式距离。如果你想改为余弦或者马氏距离,就的重新编译源码了。 Spark 里面的机器学习库都是一些经典的算法,这些代码网上也好找。这些代码使用起来叫麻烦,但是很灵活。 Spark 有一个很大的优势,那就是 RDD。模型的训练完全是并行的。
Spark 的 ML 和 MLLib 两个包区别和联系
- 技术角度上,面向的数据集类型不一样: ML 的 API 是面向 Dataset 的(Dataframe 是 Dataset 的子集,也就是 Dataset[Row]), mllib 是面对 RDD 的。Dataset 和 RDD 有啥不一样呢?Dataset 的底端是 RDD。Dataset 对 RDD 进行了更深一层的优化,比如说有 sql 语言类似的黑魔法,Dataset 支持静态类型分析所以在 compile time 就能报错,各种 combinators(map,foreach 等)性能会更好,等等。
- 编程过程上,构建机器学习算法的过程不一样: ML 提倡使用 pipelines,把数据想成水,水从管道的一段流入,从另一端流出。ML 是1.4比 Mllib 更高抽象的库,它解决如果简洁的设计一个机器学习工作流的问题,而不是具体的某种机器学习算法。未来这两个库会并行发展。
Spark RDD是怎么容错的,基本原理是什么
说说yarn-cluster和yarn-client的异同点
- cluster 模式会在集群的某个节点上为 Spark 程序启动一个称为 Master 的进程,然后 Driver 程序会运行在这个 Master 进程内部(AM -> Driver),由这种进程来启动 Driver 程序,客户端完成提交的步骤后就可以退出,不需要等待 Spark 程序运行结束,这是适合生产环境的运行方式
- client 模式也有一个 Master 进程,但是 Driver 程序(在客户端)不会运行在这个 Master 进程内部,而是运行在本地,只是通过 Master 来申请资源,直到运行结束,这种模式非常适合需要交互的计算。显然 Driver 在 client 模式下会对本地资源造成一定的压力,包括网络内存等。
解释一下groupByKey/reduceByKey/reduceByKeyLocally
Talk is cheap, show me the code.
|
|
说说Spark提供的两种共享变量
Spark 程序的大部分操作都是 RDD 操作,通过传入函数给 RDD 操作函数来计算,这些函数在不同的节点上并发执行,内部的变量有不同的作用域,不能相互访问,有些情况下不太方便。
- 广播变量,是一个只读对象,在所有节点上都有一份缓存,创建方法是
SparkContext.broadcast()。创建之后再更新它的值是没有意义的,一般用 val 来修改定义。 - 计数器,只能增加,可以用计数或求和,支持自定义类型。创建方法是
SparkContext.accumulator(V, name)。只有 Driver 程序可以读这个计算器的变量,RDD 操作中读取计数器变量是无意义的。但节点可以对该计算器进行增加。
以上两种类型都是 Spark 的共享变量。
说说对Master的理解
Master 是 local-cluster 部署模式和 Standalone 部署模式中,整个 Spark 集群最为重要的组件之一,分担了对整个集群资源的管理和分配的工作。
local-cluser 下,Master 作为 JVM 进程的对象启动,而在 Standalone 模式下,就是单独的进程启动。
说说什么是窗口间隔和滑动间隔
对于窗口操作,在其窗口内部会有 N 个批处理数据,批处理数据的个数由窗口间隔决定,其为窗口持续的时间,在窗口操作中只有窗口间隔满足了才会触发批数据的处理(指一开始的阶段)。
滑动间隔是指经过多长时间窗口滑动一次形成新的窗口,滑动传功库默认情况下和批次间隔的相同,而窗口间隔一般设置得要比它们都大。
说说Spark的预写日志功能
也叫 WriteAheadLogs,通常被用于数据库和文件系统中,保证数据操作的持久性。预写日志通常是先将操作写入到一个持久可靠的日志文件中,然后才对数据施加该操作,当加入施加该操作中出现异常,可以通过读取日志文件并重新施加该操作,从而恢复系统。
当 WAL 开启后,所有收到的数据同时保存到了容错文件系统的日志文件中,当 Spark Streaming 失败,这些接受到的数据也不会丢失。另外,接收数据的正确性只在数据被预写到日志以后接收器才会确认。已经缓存但还没有保存的数据可以在 Driver 重新启动之后由数据源再发送一次(经常问)。
这两个机制保证了数据的零丢失,即所有的数据要么从日志中恢复,要么由数据源重发。
Spark Streaming小文件问题
使用 Spark Streaming 时,如果实时计算结果要写入到 HDFS,那么不可避免的会遇到一个问题,那就是在默认情况下会产生非常多的小文件,这是由 Spark Streaming 的微批处理模式和 DStream(RDD) 的分布式(partition)特性导致的,Spark Streaming 为每个 Partition 启动一个独立的线程(一个 task/partition 一个线程)来处理数据,一旦文件输出到 HDFS,那么这个文件流就关闭了,再来一个 batch 的 parttition 任务,就再使用一个新的文件流,那么假设,一个 batch 为10s,每个输出的 DStream 有32(最大**???)个 partition,那么一个小时产生的文件数将会达到(3600/10)*32=11520个之多。众多小文件带来的结果是有大量的文件元信息**,比如文件的 location、文件大小、block number 等需要 NameNode 来维护,NameNode 会因此鸭梨山大。不管是什么格式的文件,parquet、text、JSON 或者 Avro,都会遇到这种小文件问题,这里讨论几种处理 Spark Streaming 小文件的典型方法。
- 增加 batch 大小: 这种方法很容易理解,batch 越大,从外部接收的 event 就越多,内存积累的数据也就越多,那么输出的文件数也就会变少,比如上边的时间从10s增加为100s,那么一个小时的文件数量就会减少到1152个。但别高兴太早,实时业务能等那么久吗,本来人家10s看到结果更新一次,现在要等快两分钟,是人都会骂娘。所以这种方法适用的场景是消息实时到达,但不想挤压在一起处理,因为挤压在一起处理的话,批处理任务在干等,这时就可以采用这种方法。
- Coalesce大法好: 文章开头讲了,小文件的基数是 batch_number * partition_number,而第一种方法是减少 batch_number,那么这种方法就是减少 partition_number 了,这个 api 不细说,就是减少初始的分区个数。看过 spark 源码的童鞋都知道,对于窄依赖,一个子 RDD 的 partition 规则继承父 RDD,对于宽依赖(就是那些个叉叉叉ByKey操作),如果没有特殊指定分区个数,也继承自父 rdd。那么初始的 SourceDstream 是几个 partiion,最终的输出就是几个 partition。所以 Coalesce 大法的好处就是,可以在最终要输出的时候,来减少一把 partition 个数。但是这个方法的缺点也很明显,本来是32个线程在写256M数据,现在可能变成了4个线程在写256M数据,而没有写完成这256M数据,这个 batch 是不算结束的。那么一个 batch 的处理时延必定增长,batch 挤压会逐渐增大。
- Spark Streaming 外部来处理: 我们既然把数据输出到 hdfs,那么说明肯定是要用 Hive 或者 Spark Sql 这样的“sql on hadoop”系统类进一步进行数据分析,而这些表一般都是按照半小时或者一小时、一天,这样来分区的(注意不要和 Spark Streaming 的分区混淆,这里的分区,是用来做分区裁剪优化的),那么我们可以考虑在 Spark Streaming 外再启动定时的批处理任务来合并 Spark Streaming 产生的小文件。这种方法不是很直接,但是却比较有用,“性价比”较高,唯一要注意的是,批处理的合并任务在时间切割上要把握好,搞不好就可能会去合并一个还在写入的 Spark Streaming 小文件。
- 自己调用 foreach 去 append: Spark Streaming 提供的 foreach 这个 outout 类 api (一种 Action 操作),可以让我们自定义输出计算结果的方法。那么我们其实也可以利用这个特性,那就是每个 batch 在要写文件时,并不是去生成一个新的文件流,而是把之前的文件打开。考虑这种方法的可行性,首先,HDFS 上的文件不支持修改,但是很多都支持追加,那么每个 batch 的每个 partition 就对应一个输出文件,每次都去追加这个 partition 对应的输出文件,这样也可以实现减少文件数量的目的。这种方法要注意的就是不能无限制的追加,当判断一个文件已经达到某一个阈值时,就要产生一个新的文件进行追加了。所以大概就是一直32个文件咯。
用过UDF吗
因为目前 Spark SQL 本身支持的函数有限,一些常用的函数都没有,比如 len, concat…etc 但是使用 UDF 来自己实现根据业务需要的功能是非常方便的。Spark SQL UDF 其实是一个 Scala 函数,被 catalyst 封装成一个 Expression 结点,最后通过 eval 方法计根据当前 Row 计算 UDF 的结果。UDF 对表中的单行进行转换,以便为每行生成单个对应的输出值。例如,大多数 SQL 环境提供 UPPER 函数返回作为输入提供的字符串的大写版本。
用户自定义函数可以在 Spark SQL 中定义和注册为 UDF,并且可以关联别名,这个别名可以在后面的 SQL 查询中使用。作为一个简单的示例,我们将定义一个 UDF 来将以下 JSON 数据中的温度从摄氏度(degrees Celsius)转换为华氏度(degrees Fahrenheit)。
|
|
以下示例代码使用 SQL 别名为 CTOF 来注册我们的转换 UDF,然后在 SQL 查询使用它来转换每个城市的温度。为简洁起见,省略了 SQLContext 对象和其他代码的创建,每段代码下面都提供了完整的代码链接。
|
|
|
|
|
|
注意,Spark SQL 定义了 UDF1 到 UDF22 共22个类,UDF 最多支持22个输入参数。上面的例子中使用 UDF1 来处理我们单个温度值作为输入。如果我们不想修改 Apache Spark 的源代码,对于需要超过22个输出参数的应用程序我们可以使用数组或结构作为参数来解决这个问题,如果你发现自己用了 UDF6 或者更高 UDF 类你可以考虑这样操作。
用户定义的聚合函数(User-defined aggregate functions, UDAF)同时处理多行,并且返回一个结果,通常结合使用 GROUP BY 语句(例如 COUNT 或 SUM)。为了简单起见,我们将实现一个叫 SUMPRODUCT 的 UDAF 来计算以库存来分组的所有车辆零售价值,具体的数据如下:
|
|
Apache Spark UDAF 目前只支持在 Scala 和 Java 中通过扩展 UserDefinedAggregateFunction 类使用。下面例子中我们定义了一个名为 SumProductAggregateFunction 的类,并且为它取了一个名为 SUMPRODUCT 的别名,现在我们可以在 SQL 查询中初始化并注册它,和上面的 CTOF UDF 的操作步骤很类似,如下:
|
|
Apache Spark 中的其他 UDF 支持,Spark SQL 支持集成现有 Hive 中的 UDF,UDAF 和 UDTF 的(Java或Scala)实现。UDTFs(user-defined table functions, 用户定义的表函数)可以返回多列和多行 - 它们超出了本文的讨论范围,我们可能会在以后进行说明。集成现有的 Hive UDF 是非常有意义的,我们不需要向上面一样重新实现和注册他们。Hive 定义好的函数可以通过 HiveContext 来使用,不过我们需要通过 spark-submit 的 –jars 选项来指定包含 HIVE UDF 实现的 jar 包,然后通过 CREATE TEMPORARY FUNCTION 语句来定义函数,如下:
|
|
|
|
注意,Hive UDF 只能使用 Apache Spark 的 SQL 查询语言来调用 - 换句话说,它们不能与 Dataframe API 的领域特定语言(domain-specific-language, DSL)一起使用。
另外,通过包含实现 jar 文件(在 spark-submit 中使用 -jars 选项)的方式 PySpark 可以调用 Scala 或 Java 编写的 UDF(through the SparkContext object’s private reference to the executor JVM and underlying Scala or Java UDF implementations that are loaded from the jar file)。下面的示例演示了如何使用先前 Scala 中定义的 SUMPRODUCT UDAF:
|
|
|
|
每个版本的 Apache Spark 都在不断地添加与 UDF 相关的功能,比如在 2.0 中 R 增加了对 UDF 的支持。
了解 Apache Spark UDF 功能的性能影响很重要。例如,Python UDF(比如上面的 CTOF 函数)会导致数据在执行器的 JVM 和运行 UDF 逻辑的 Python 解释器之间进行序列化操作;与 Java 或 Scala 中的 UDF 实现相比,大大降低了性能。缓解这种序列化瓶颈的解决方案如下:
- 从 PySpark 访问 Hive UDF。 Java UDF 实现可以由执行器 JVM 直接访问。
- 在 PySpark 中访问在 Java 或 Scala 中实现的 UDF 的方法。正如上面的 Scala UDAF 实例。
https://my.oschina.net/cloudcoder/blog/640009 https://www.iteblog.com/archives/2038.html
Mesos粗粒度和细粒度对比
- 粗粒度运行模式: Spark 应用程序在注册到 Mesos 时会分配对应系统资源,在执行过程中由 SparkContext 和 Executor 直接交互,该模式优点是由于资源长期持有减少了资源调度的时间开销,缺点是该模式下 Mesos 无法感知资源使用的变化,容易造成系统资源的闲置,无法被 Mesos 其他框架使用,造成资源浪费。
- 细粒度的运行模式: Spark 应用程序是以单个任务的粒度发送到 Mesos 中执行,在执行过程中 SparkContext 并不能和 Executor 直接交互,而是由 Mesos Master 进行统一的调度管理,这样能够根据整个 Mesos 集群资源使用的情况动态调整。该模式的优点是系统资源能够得到充分利用,缺点是该模式中每个人物都需要从 Mesos 获取资源,调度延迟较大,对于 Mesos Master 开销较大。
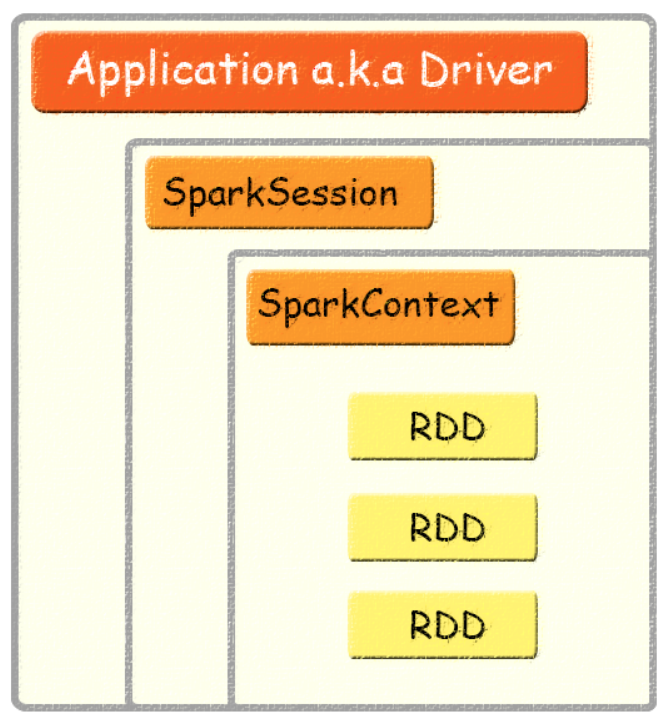
说说SparkContext和SparkSession有什么区别
- Application: 用户编写的 Spark 应用程序,Driver 即运行上述 Application 的 main() 函数并且创建 SparkContext,Application 也叫应用。
- SparkContext: 整个应用的上下文,控制应用的生命周期。
- RDD: 不可变的数据集合,可由 SparkContext 创建,是 Spark 的基本计算单元。
- SparkSession: 可以由上节图中看出,Application、SparkSession、SparkContext、RDD之间具有包含关系,并且前三者是1对1的关系。SparkSession 是 Spark 2.0 版本引入的新入口,在这之前,创建一个 Application 对应的上下文是这样的:
|
|
现在 SparkConf、SparkContext 和 SQLContext 都已经被封装在 SparkSession 当中,并且可以通过 builder 的方式创建:
|
|
通过 SparkSession 创建并操作 Dataset 和 DataFrame,代码中的 Spark 对象就是 SparkSession:
|
|
如果Spark Streaming停掉了,如何保证Kafka的重新运作是合理的呢
首先要说一下 Spark 的快速故障恢复机制,在节点出现故障的情况下,传统流处理系统会在其他节点上重启失败的连续算子,并可能冲洗能运行先前数据流处理操作获取部分丢失数据。在此过程中只有该节点重新处理失败的过程。只有在新节点完成故障前所有计算后,整个系统才能够处理其他任务。在 Spark 中,计算将会分成许多小的任务,保证能在任何节点运行后能够正确合并,因此,就算某个节点出现故障,这个节点的任务将均匀地分散到集群中的节点进行计算,相对于传递故障恢复机制能够更快地恢复。
列举所有 Transformation 和 Action(哪里有比较官方的答案呢)
Transformation: Map, Filter, FlatMap, Sample, GroupByKey, ReduceByKey, Union, Join, Cogroup, MapValues, Sort, PartionBy
Action: Collect, Reduce, Lookup, Save (主要记住,结果不是 RDD 的就是 Action)
说说Yarn-cluster的运行阶段
在 Yarn-cluset 模式下,当用户向 Yarn 提交一个应用程序后,Yarn 将两个阶段运行该应用程序:
- 第一阶段是把 Spark 的 Driver 作为一个 Application Master 在 Yarn 集群中先启动。
- 第二阶段是由 Application Master(Driver) 创建应用程序,然后为它向 Resource Manager 申请资源,并启动 Executor 来运行任务集,同时监控它的整个过程,直到运行介绍结束。
Mesos粗细度对比
Mesos 粗粒度运行模式中,Spark 程序在注册到 Mesos 的时候会分配对应系统资源,在执行过程中由 SparkContext 和 Executor 直接进行交互。该模式优点是由于资源长期持有,减少了资源调度的时间开销,缺点是该模式之下,Mesos 无法感知资源使用的变化,容易造成资源的闲置,无法被 Mesos 其他框架所使用,从而造成资源浪费。
而在细粒度运行模式下,Spark 应用程序是以单个任务的粒度发送到 Mesos 中执行,在执行过程中 SparkContext 并不能与 Executor 直接进行交互,而是由 Mesos Master 进行统一的调度管理,这样能够根据整个 Mesos 集群资源使用的情况动态调整。该模式的优点是系统资源能够得到充分利用,缺点是该模式中每个任务都需要从 Mesos 获取资源,调度延迟比较大,对于 Mesos 开销比较大。
说说Standalone模式下运行Spark程序的大概流程
Standalone 模式分别由客户端、Master 节点和 Worker 节点组成。在 Spark Shell 提交计算搜狗日志行数代码的时候,所在机器作为客户端启动应用程序,然后向 Master 注册应用程序,由 Master 通知 Worker 节点启动 Executor,Executor 启动之后向客户端的 Driver 注册,最后由 Driver 发送执行任务给 Executor 并监控任务执行情况。该程序代码中,在触发计算行数动作之前,需要设置缓存代码,这样在执行计算行数行为的时候进行缓存数据,缓存后再运行计算行数。
如何区分Application(应用程序)还有Driver(驱动程序)
Application 是指用户编写的 Spark 应用程序,包含驱动程序 Driver 和分布在集群中多个节点上运行的 Executor 代码,在执行过程之中由一个或多个做作业组成。
Driver 是 Spark 中的 Driver 即运行上述 Application 的 main 函数并且创建 SparkContext,其中创建 SparkContext 的目的是为了准备 Spark 应用程序的运行环境。在 Spark 中由 SparkContext 负责与 ClusterManager 通信,进行资源的申请,任务的分配和监控等。当 Executor 部分运行完毕后,Driver 负责把 SparkContext 关闭,通常 Driver 会拿 SparkContext 来代表。
介绍一下Spark通信的启动方式
Spark 启动过程主要是 Master 与 Worker 之间的通信,首先由 Worker 节点向 Master 发送注册消息,然后 Master 处理完毕后,返回注册成功消息或失败消息,如果成功注册,那么 Worker 就会定时发送心跳消息给 Master。
介绍一下Spark运行时候的消息通信
关键词,Application -> SparkContext -> Master -> Register -> Executor -> RDD -> DAGScheduler -> Stage -> TaskScheduler -> TaskSet。
用户提交应用程序时,应用程序的 SparkContext 会向 Master 发送应用注册消息,并由 Master 给该应用分配 Executor,Excecutor 启动之后,Executor 会向 SparkContext 发送注册成功消息。当 SparkContext 的 RDD 触发行动操作之后,将创建 RDD 的 DAG。通过 DAGScheduler 进行划分 Stage 并把 Stage 转化为 TaskSet,接着 TaskScheduler 向注册的 Executor 发送执行消息,Executor 接收到任务消息后启动并运行。最后当所有任务运行时候,由 Driver 处理结果并回收资源。
解释一下Stage
每个作业 Job 会因为 RDD 之间的依赖关系拆分成多组任务集合,称为调度阶段,也叫做任务集 TaskSet 。调度阶段的划分由 DAGScheduler 划分,调度阶段有 Shuffle Map Stage 和 Result Stage 两种。
然后按照这个划分 Stage。
描述一下Worker异常的情况
Spark 独立运行模式 Standalone 采用的是 Master/Slave 的结构,其中 Slave 是由 Worker 来担任的,在运行的时候会发送心跳给 Master,让 Master 知道 Worker 的实时状态,另一方面,Master 也会检测注册的 Worker 是否超时,因为在集群运行的过程中,可能由于机器宕机或者进程被杀死等原因造成 Worker 异常退出。
描述一下Master异常的情况
Master 出现异常的时候,会有几种情况,而在独立运行模式 Standalone 中,Spark 支持几种策略,来让 Standby Master 来接管集群。主要配置的地方在于 spark-env.sh 文件中。配置项是 spark.deploy.recoveryMode 进行设置,默认是 None。
- ZOOKEEPER: 集群元数据持久化到 Zookeeper 中,当 Master 出现异常,ZK 通过选举机制选举新的 Master,新的 Master 接管的时候只要从 ZK 获取持久化信息并根据这些信息恢复集群状态。StandBy 的 Master 随时候命的。
- FILESYSTEM: 集群元数据持久化到本地文件系统中,当 Master 出现异常的时候,只要在该机器上重新启动 Master,启动后新的 Master 获取持久化信息并根据这些信息恢复集群的状态。
- CUSTOM: 自定义恢复方式,对 StandaloneRecoveryModeFactory 抽象类进行实现并把该类配置到系统中,当 Master 出现异常的时候,会根据用户自定义的方式进行恢复集群状态。
- NONE: 不持久化集群的元数据,当出现异常的是,新启动 Master 不进行信息恢复集群状态,而是直接接管集群。
一句话Spark存储体系
Spark 存储介质包括内存和磁盘等。
介绍一下Spark存储体系
Spark Streaming概述
具有高吞吐量和容错能力强的特点,输入源有很多,如 Kafka, Flume 等。
关于流式计算的做法,如果按照传统工具的做法把数据存储到数据库中再进行计算,这样是无法做到实时的,而完全把数据放到内存中计算,万一宕机、断电了,数据也就丢失了。
因此 Spark 流式计算引入了检查点 CheckPoint 和日志,以便能够从中恢复计算结果。而本质上 Spark Streaming 是接收实时输入数据流并把他们按批次划分,然后交给 Spark 计算引擎处理生成按照批次划分的结果流。
知道Hadoop MRv1的局限吗
总结一句,可扩展性、可用性、资源利用率、不兼容等。
- 可扩展性差,在运行的时候,JobTracker 既负责资源管理,又负责任务调度,当集群繁忙的时候,JobTracker 很容易成为瓶颈,最终导致可扩展性的问题。
- 可用性差,采用单节点的 Master 没有备用 Master 以及选举操作,这导致一旦 Master 出现故障,整个集群将不可用。
- 资源利用率低,TaskTracker 使用 slot 等量划分本节点上的资源量,slot 代表计算资源将各个 TaskTracker 上的空闲 slot 分配给 Task 使用,一些 Task 并不能充分利用 slot,而其他 Task 无法使用这些空闲的资源。有时会因为作业刚刚启动等原因导致 MapTask 很多,而 Reduce Task 任务还没调度的情况,这时 Reduce slot 也会被闲置。
- 不能支持多种 MapReduce 框架,无法通过可插拔方式将自身的 MapReduce 框架替换为其他实现,例如 Spark,Storm。
了解Spark的架构吗
从集群部署的角度来看,Spark 集群由集群管理器 Cluster Manager、工作节点 Worker、执行器 Executor、驱动器 Driver、应用程序 Application 等部分组成。
- Cluster Manager: 主要负责对集群资源的分配和管理,Cluster Manager 在 YARN 部署模式下为 RM,在 Mesos 下为 Mesos Master,Standalone 模式下为 Master。CM 分配的资源属于一级分配,它将各个 Worker 上的内存、CPU 等资源分配给 Application,但是不负责对 Executor 的资源分类。Standalone 模式下的 Master 会直接给 Application 分配内存、CPU 及 Executor 等资源。
- Worker: Spark 的工作节点。在 YARN 部署模式下实际由 NodeManager 替代。Worker 节点主要负责,把自己的内存、CPU 等资源通过注册机制告知 Cluster Manager,创建 Executor,把资源和任务进一步分配给 Executor,同步资源信息,Executor 状态信息给 CM 等等。Standalone 部署模式下,Master 将 Worker 上的内存、CPU 以及 Executor 等资源分配给 Application 后,将命令 Worker 启动 CoarseGrainedExecutorBackend 进程(此进程会创建 Executor 实例)。
- Executor: 执行计算任务的一线组件,主要负责任务的执行及与 Worker Driver 信息同步。
- Driver: Application 的驱动程序,Application 通过 Driver 与 CM、Executor 进行通信。Driver 可以运行在 Application 中,也可以由 Application 提交给 CM 并由 CM 安排 Worker 运行。
- Application: 用户使用 Spark 提供的 API 编写的应用程序,Application 通过 Spark API 将进行 RDD 的转换和 DAG 的创建,并通过 Driver 将 Application 注册到 CM,CM 将会根据 Application 的资源需求,通过一级资源分配将 Executor、内存、CPU 等资源分配给 Application。Driver 通过二级资源分配将 Executor 等资源分配给每一个任务,Application 最后通过 Driver 告诉 Executor 运行任务。
能否在Mac上运行Mesos和Spark
首先参考 Mesos 官网,在 Mac 上编译运行 Mesos,直到可以打开 Mesos UI。
如果在编译过程发生错误,也许这个 Link 会帮助到你。
|
|
说说Spark Streaming是如何收集和处理数据的
在 Spark Streaming 中,数据采集是逐条进行的,而数据处理是按批 mini batch进行的,因此 Spark Streaming 会先设置好批处理间隔 batch duration,当超过批处理间隔就会把采集到的数据汇总起来成为一批数据交给系统去处理。
解释一下窗口间隔window duration和滑动间隔slide duration
图忘记从哪里找的了
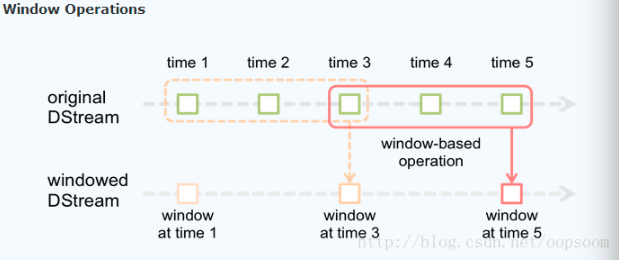
- 红色的矩形就是一个窗口,窗口 hold 的是一段时间内的数据流。
- 这里面每一个 time 都是时间单元,在官方的例子中,每隔 window size 是3 time unit, 而且每隔2个单位时间,窗口会滑动 slide 一次。
所以基于窗口的操作,需要指定2个参数:
1.窗口大小,就是一段时间内数据的容器 2.滑动间隔,就是我们可以理解成间隔
窗口间隔一般大于(批处理间隔、滑动间隔),会有一些重叠。这都是理解窗口操作的关键。
介绍一下Spark Streaming的foreachRDD(func)方法
将函数应用于 DStream 的 RDD 上,这个操作会输出数据到外部系统,比如保存 RDD 到文件或者网络数据库等。需要注意的是 func 函数是运行该 Streaming 应用的 Driver 进程里执行的。
简单描述一下Spark Streaming的容错原理
Spark Streaming 的一个特点就是高容错。
首先 Spark RDD 就有容错机制,每一个 RDD 都是不可变的分布式可重算的数据集,其记录这确定性的操作血统,所以只要输入数据是可容错的,那么任意一个 RDD 的分区出错或不可用,都是可以利用原始输入数据通过转换操作而重新计算出来的。
预写日志通常被用于数据库和文件系统中,保证数据操作的持久性。预写日志通常是先将操作写入到一个持久可靠的日志文件中,然后才对数据施加该操作,当加入施加操作中出现了异常,可以通过读取日志文件并重新施加该操作。
另外接收数据的正确性只在数据被预写到日志以后接收器才会确认,已经缓存但还没保存的数据可以在 Driver 重新启动之后由数据源再发送一次,这两个机制确保了零数据丢失,所有数据或者从日志中恢复,或者由数据源重发。
DStream有几种转换操作
分为三类,普通的转换操作,窗口操作和输出操作。
如何对RDD进行继承创建领域RDD
Spark-redis 给出了例子。
说说DStreamGraph
Spark Streaming 中作业生成与 Spark 核心类似,对 DStream 进行的各种操作让它们之间的操作会被记录到名为 DStream 使用输出操作时,这些依赖关系以及它们之间的操作会被记录到 DStreamGraph 的对象中表示一个作业。这些作业注册到 DStreamGraph 并不会立即运行,而是等到 Spark Streaming 启动之后,达到批处理时间,才根据 DG 生成作业处理该批处理时间内接收的数据。
分析一下Spark Streaming的transform()和updateStateByKey()两个操作
transform(func): 允许 DStream 任意的 RDD-to-RDD 函数。updateStateByKey(): 可以保持任意状态,同时进行信息更新,先定义状态,后定义状态更新函数。
说说Spark Streaming的输出操作
其实就几个,比如 print(), saveAsTextFiles(), foreachRDD() 等等。
一句话Spark Streaming流数据处理过程
启动流处理引擎、接收及存储流数据、处理流数据和输出结果4个步骤。
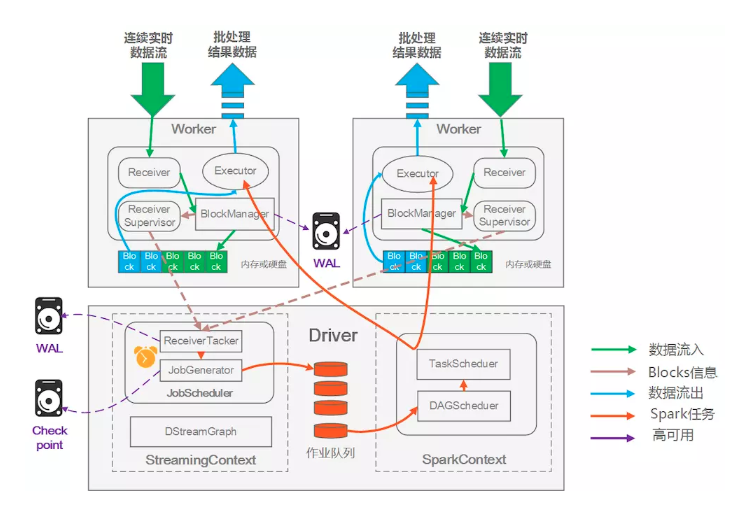
聊聊Spark Streaming的运行架构
了解StreamingContext启动时序图吗
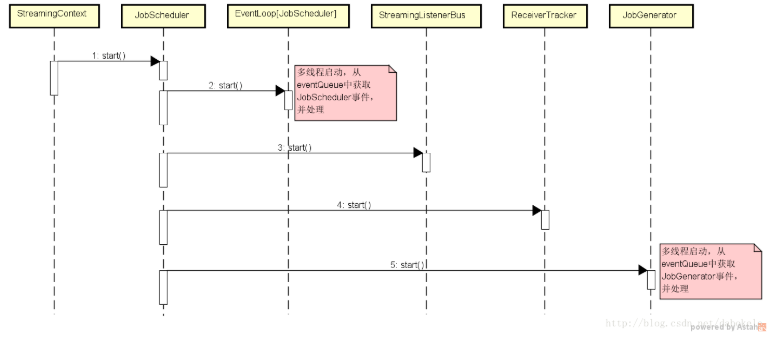
- 初始化 StreamingContext 中的 DStreamGraph 和 JobScheduler,进而启动 JobScheduler 的 ReceiveTracker 和 JobGenerator。
- 初始化阶段会进行成员变量的初始化,重要的包括 DStreamGraph(包含 DStream 之间相互依赖的有向无环图),JobScheduler(定时查看 DStreamGraph,然后根据流入的数据生成运行作业),StreamingTab(在 Spark Streaming 运行的时候对流数据处理的监控)。
- 然后就是创建 InputDStream,接着就是对 InputDStream 进行 flatMap, map, reduceByKey, print 等操作,类似于 RDD 的转换操作。
- 启动 JobScheduler,实例化并启动 ReceiveTracker 和 JobGenerator。
- 启动 JobGenerator
- 启动 ReceiverTracker
流数据存储
作为流数据接收器调用 Receiver.store 方式进行数据存储,该方法有多个重载方法,如果数据量很小,则攒多条数据成数据块再进行块存储,如果数据量大,则直接进行块存储。
再谈Spark Streaming的容错性
实时流处理系统需要长时间接收并处理数据,这个过程中出现异常是难以避免的,需要流程系统具备高容错性。Spark Streaming 一开始就考虑了两个方面。
- 利用 Spark 自身的容错设计、存储级别和 RDD 抽象设计能够处理集群中任何 Worker 节点的故障
- Spark 运行多种运行模式,其 Driver 端可能运行在 Master 节点或者集群中的任意节点,这样让 Driver 端具备容错能力是很大的挑战,但是由于其接收的数据是按照批进行存储和处理,这些批次数据的元数据可以通过执行检查点的方式定期写入到可靠的存储中,在 Driver 端重新启动中恢复这些状态
当接收到的数据缓存在 Executor 内存中的丢失风险要怎么处理呢?
如果是独立运行模式/Yarn/Mesos 模式,当 Driver 端失败的时候,该 Driver 端所管理的 Executor 以及内存中数据将终止,即时 Driver 端重新启动这些缓存的数据也不能被恢复。为了避免这种数据损失,就需要预写日志功能了。
当 Spark Streaming 应用开始的时候,也就是 Driver 开始的时候,接收器成为长驻运行任务,这些接收器接收并保存流数据到 Spark 内存以供处理。
- 接收器将数据分成一系列小块,存储到 Executor 内存或磁盘中,如果启动预写日志,数据同时还写入到容错文件系统的预写日志文件。
- 通知 StreamingContext,接收块中的元数据被发送到 Driver 的 StreamingContext,这个元数据包括两种,一是定位其 Executor 内存或磁盘中数据位置的块编号,二是块数据在日志中的偏移信息(如果启用 WAL 的话)。
谈谈Spark Streaming Driver端重启会发生什么
- 恢复计算: 使用检查点 Checkpoint 信息重启 Driver 端,重构上下文并重启接收器
- 恢复元数据块: 为了保证能够继续下去所必备的全部元数据块都被恢复
- 未完成作业的重新形成: 由于失败而没有处理完成的批处理,将使用恢复的元数据再次产生 RDD 和对应的作业
- 读取保存在日志中的块数据: 在这些作业执行的时候,块数据直接从预写日志中读出,这将恢复在日志中可靠地保存所有必要的数据
- 重发尚未确认的数据: 失败时没有保存到日志中的缓存数据将由数据源再次发送
说说RDD和DataFrame和DataSet的关系
这里主要对比 Dataset 和 DataFrame,因为 Dataset 和 DataFrame 拥有完全相同的成员函数,区别只是每一行的数据类型不同。
DataFrame 也可以叫 Dataset[Row],每一行的类型是 Row,不解析,每一行究竟有哪些字段,各个字段又是什么类型都无从得知。而 Dataset 中,每一行是什么类型是不一定的,在自定义了 case class 之后可以很自由的获得每一行的信息。
聊聊Spark SQL运行架构
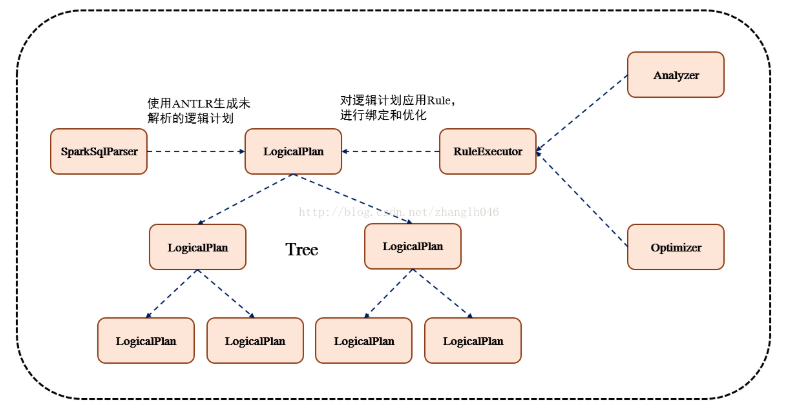
Spark SQL 运行架构 Spark SQL 对 SQL 语句的处理和关系型数据库类似,即词法/语法解析、绑定、优化、执行。Spark SQL 会先将 SQL 语句解析成一棵树 Tree,然后使用规则 (Rule) 对 Tree 进行绑定 bind、优化等处理过程。Spark SQL 由 Core、Catalyst、Hive、Hive-ThriftServer 四部分构成:
- Core: 负责处理数据的输入和输出,如获取数据,查询结果输出成 DataFrame 等
- Catalyst: 负责处理整个查询过程,包括解析、绑定、优化等
- Hive: 负责对 Hive 数据进行处理
- Hive-ThriftServer: 主要用于对 Hive 的访问
1.1 TreeNode 逻辑计划、表达式等都可以用 Tree 来表示,它只是在内存中维护,并不会进行磁盘的持久化,分析器和优化器对树的修改只是替换已有节点。 TreeNode 有2个直接子类,QueryPlan 和 Expression。QueryPlan 下又有 LogicalPlan 和 SparkPlan,Expression 是表达式体系,不需要执行引擎计算而是可以直接处理或者计算的节点,包括投影操作,操作符运算等。 1.2 Rule & RuleExecutor Rule 就是指对逻辑计划要应用的规则,以到达绑定和优化。他的实现类就是 RuleExecutor。优化器和分析器都需要继承 RuleExecutor。每一个子类中都会定义 Batch、Once、FixPoint。其中每一个 Batch 代表着一套规则,Once 表示对树进行一次操作,FixPoint 表示对树进行多次的迭代操作。RuleExecutor 内部提供一个 Seq[Batch] 属性,里面定义的是 RuleExecutor 的处理逻辑,具体的处理逻辑由具体的 Rule 子类实现。
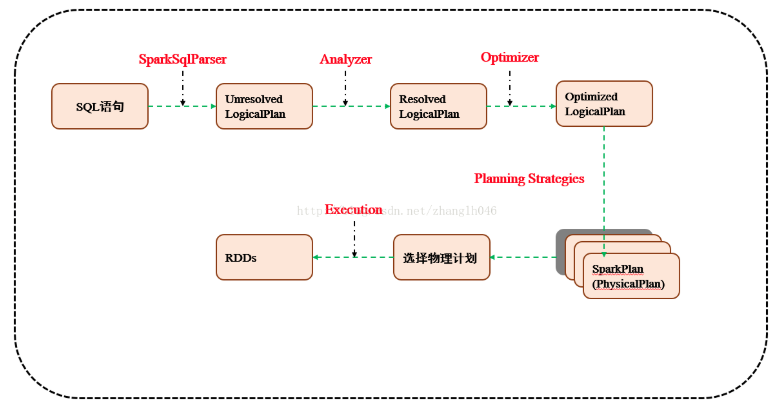
Spark SQL 运行原理
- 使用 SessionCatalog 保存元数据: 在解析 SQL 语句之前,会创建 SparkSession,或者如果是2.0之前的版本初始化 SQLContext,SparkSession 只是封装了 SparkContext 和 SQLContext 的创建而已,Spark 会把元数据保存在 SessionCatalog 中,涉及到表名,字段名称和字段类型。创建临时表或者视图,其实就会往 SessionCatalog 注册。
- 解析 SQL,使用 ANTLR 生成未绑定的逻辑计划: 当调用 SparkSession 的 sql 或者 SQLContext 的sql方法,我们以2.0为例,就会使用 SparkSqlParser 进行解析 SQL,使用的 ANTLR 进行词法解析和语法解析。它分为2个步骤来生成 Unresolved LogicalPlan: (1)Lexical Analysis,负责将 token 分组成符号类; (2)构建一个分析树或者语法树 AST。
- 使用分析器 Analyzer 绑定逻辑计划: 在该阶段,Analyzer 会使用 Analyzer Rules,并结合 SessionCatalog,对未绑定的逻辑计划进行解析,生成已绑定的逻辑计划。
- 使用优化器 Optimizer 优化逻辑计划: 优化器也是会定义一套 Rules,利用这些 Rule 对逻辑计划和 Exepression 进行迭代处理,从而使得树的节点进行和并和优化。
- 使用 SparkPlanner 生成物理计划: SparkSpanner 使用 Planning Strategies,对优化后的逻辑计划进行转换,生成可以执行的物理计划 SparkPlan。
- 使用 QueryExecution 执行物理计划: 此时调用 SparkPlan 的 execute 方法,底层其实已经再触发 JOB 了,然后返回RDD。
总结一下,除了上图的表达,语言上应该至少说到 sql 解析到任务执行的流程,比如通过 SparkSession 初始化把表名、字段名等元数据注册到 SessionCatalog 上,然后就是通过 ANTLR 解析 sql,生成未绑定的逻辑计划,然后通过 Analyzer 绑定逻辑计划,并通过 Optimizer 来优化逻辑计划,通过 SparkPlanner 来生成物理计划,然后通过 QueryExecution 来执行物理计划。
总结一下Spark的运行架构
Spark 应用程序一般由三部分组成,包括 SparkContext, Cluster Manager 和 Executor。SparkContext 负责和 Cluster Manager 通信,进行资源申请、任务分配和监控等,负责作业执行的全生命周期管理,而 Cluster Manager 提供了资源的分配和管理,在不同的运行模式下担任的角色和具体实现是不一样的。此外 TaskScheduler 负责具体任务的调度执行,而 SchedulerBackend 则负责应用程序运行期间与底层资源调度系统交互。
createDirectStream有什么用
官方为 Spark 提供了两种方式来消费 Kafka 中的数据,高阶 api 由 Kafka 自己来来维护 offset, 有篇 blog 总结的比较好
第一种是利用 Kafka 消费者高级 API 在 Spark 的工作节点上创建消费者线程,订阅 Kafka 中的消息,数据会传输到 Spark 工作节点的执行器中,但是默认配置下这种方法在 Spark Job 出错时会导致数据丢失,如果要保证数据可靠性,需要在 Spark Streaming 中开启Write Ahead Logs(WAL),也就是上文提到的 Kafka 用来保证数据可靠性和一致性的数据保存方式。可以选择让 Spark 程序把 WAL 保存在分布式文件系统(比如 HDFS)中,
第二种方式不需要建立消费者线程,使用 createDirectStream 接口直接去读取 Kafka 的 WAL,将 Kafka 分区与 RDD 分区做一对一映射,相较于第一种方法,不需再维护一份 WAL 数据(Kafka 和 Spark 都有),提高了性能。读取数据的偏移量由 Spark Streaming 程序通过检查点机制自身处理,避免在程序出错的情况下重现第一种方法重复读取数据的情况,消除了 Spark Streaming 与 ZooKeeper/Kafka 数据不一致的风险。保证每条消息只会被 Spark Streaming 处理一次。
Spark读取Kafka数据createStream和createDirectStream的区别
KafkaUtils.createDstream 构造函数为:
|
|
使用了 receivers 来接收数据,利用的是 Kafka 高层次的消费者 api,对于所有的 receivers 接收到的数据将会保存在 Spark executors 中,然后通过 Spark Streaming 启动 job 来处理这些数据,默认可能会丢失,可启用WAL日志,该日志存储在HDFS上(防止丢失的折中的方法)。
创建一个 receiver 来对 Kafka 进行定时拉取数据,ssc 的 rdd 分区和 Kafka 的 topic 分区不是一个概念,故如果增加特定主体分区数仅仅是增加一个 receiver 中消费 topic 的线程数,并不增加 Spark 的并行处理数据数量。对于不同的 group 和 topic 可以使用多个 receivers 创建不同的 DStream。如果启用了WAL,需要设置存储级别,即 KafkaUtils.createStream(….,StorageLevel.MEMORY_AND_DISK_SER)
KafkaUtils.createDirectStream
区别 receiver 接收数据,这种方式定期地从 Kafka 的 topic+partition 中查询最新的偏移量,再根据偏移量范围在每个 batch 里面处理数据,使用的是 Kafka 的简单消费者 api。
优点:
- 简化并行,不需要多个 Kafka 输入流,该方法将会创建和 Kafka 分区一样的 rdd 个数,而且会从 Kafka 并行读取。
- 高效,这种方式并不需要 WAL,WAL 模式需要对数据复制两次,第一次是被 Kafka 复制,另一次是写到 WAL 中。
- 恰好一次语义(exactly-once),传统的读取 Kafka 数据是通过 Kafka 高层次 api 把偏移量写入 ZooKeeper 中,存在数据丢失的可能性是 Zookeeper 中和 ssc 的偏移量不一致。EOS 通过实现 Kafka 低层次 api,偏移量仅仅被 ssc 保存在 checkpoint 中,消除了 zk 和 ssc 偏移量不一致的问题。缺点是无法使用基于 ZooKeeper 的 Kafka 监控工具。