概述
当第一次碰到 Spark,尤其是 Checkpoint 的时候难免有点一脸懵逼,不禁要问,Checkpoint 到底是什么。所以,当我们在说 Checkpoint 的时候,我们到底是指什么?
网上找到一篇文章,说到 Checkpoint,大概意思是检查点创建一个已知的节点,SQL Server 数据库引擎可以在意外关闭或崩溃后从恢复期间开始应用日志中包含的更改。所以你可以简单理解成 Checkpoint 是用来容错的,当错误发生的时候,可以迅速恢复的一种机制,这里就不展开讲了。
A checkpoint creates a known good point from which the SQL Server Database Engine can start applying changes contained in the log during recovery after an unexpected shutdown or crash.
回到 Spark 上,尤其在流式计算里,需要高容错的机制来确保程序的稳定和健壮。从源码中看看,在 Spark 中,Checkpoint 到底做了什么。在源码中搜索,可以在 Streaming 包中的 Checkpoint。
作为 Spark 程序的入口,我们首先关注一下 SparkContext 里关于 Checkpoint 是怎么写的。SparkContext 我们知道,定义了很多 Spark 内部的对象的引用。可以找到 Checkpoint 的文件夹路径是这么定义的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
// 定义 checkpointDir
private[spark] var checkpointDir: Option[String] = None
/**
* Set the directory under which RDDs are going to be checkpointed. The directory must
* be a HDFS path if running on a cluster.
*/
def setCheckpointDir(directory: String) {
// If we are running on a cluster, log a warning if the directory is local.
// Otherwise, the driver may attempt to reconstruct the checkpointed RDD from
// its own local file system, which is incorrect because the checkpoint files
// are actually on the executor machines.
// 如果运行的是 cluster 模式,当设置本地文件夹的时候,会报 warning
// 道理很简单,被创建出来的文件夹路径实际上是 executor 本地的文件夹路径,不是不行,
// 只是有点不合理,Checkpoint 的东西最好还是放在分布式的文件系统中
if (!isLocal && Utils.nonLocalPaths(directory).isEmpty) {
logWarning("Spark is not running in local mode, therefore the checkpoint directory " +
s"must not be on the local filesystem. Directory '$directory' " +
"appears to be on the local filesystem.")
}
checkpointDir = Option(directory).map { dir =>
// 显然文件夹名就是 UUID.randoUUID() 生成的
val path = new Path(dir, UUID.randomUUID().toString)
val fs = path.getFileSystem(hadoopConfiguration)
fs.mkdirs(path)
fs.getFileStatus(path).getPath.toString
}
}
|

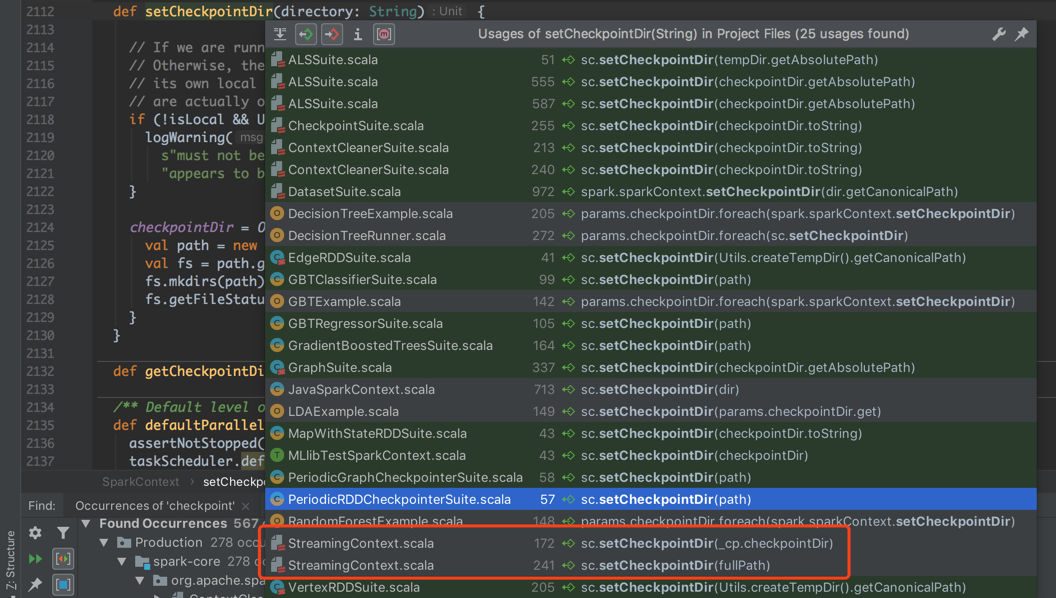
关于 setCheckpointDir 被那些类调用了,可以看以下截图。除了常见的 StreamingContext 中需要使用(以为容错性是流式计算的基本保证),另外的就是一些需要反复迭代计算使用 RDD 的场景,包括各种机器学习算法的时候,图中可以看到像 ALS, Decision Tree 等等算法,这些算法往往需要反复使用 RDD,遇到大的数据集用 Cache 就没有什么意义了,所以一般会用 Checkpoint。
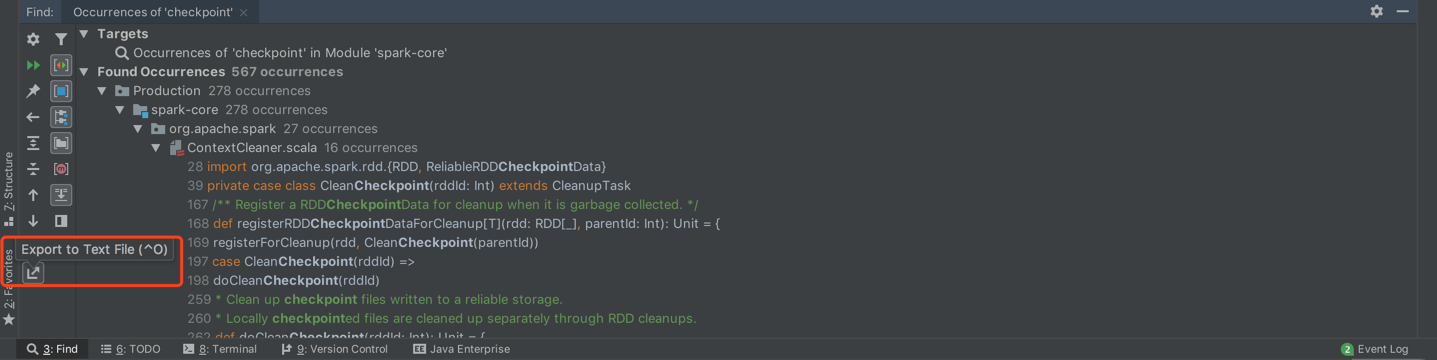
此处我只计划深挖一下 spark core 里的代码。推荐大家一个 IDEA 的功能,下图右下方可以将你搜索的关键词的代码输出到外部文件中,到时候可以打开自己看看 spark core 中关于 Checkpoint 的代码是怎么组织的。
继续找找 Checkpoint 的相关信息,可以看到 runJob 方法的最后是一个 rdd.toCheckPoint() 的使用。runJob 我们知道是触发 action 的一个方法,那么我们进入 doCheckpoint() 看看。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
/**
* Run a function on a given set of partitions in an RDD and pass the results to the given
* handler function. This is the main entry point for all actions in Spark.
*/
def runJob[T, U: ClassTag](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
resultHandler: (Int, U) => Unit): Unit = {
if (stopped.get()) {
throw new IllegalStateException("SparkContext has been shutdown")
}
val callSite = getCallSite
val cleanedFunc = clean(func)
logInfo("Starting job: " + callSite.shortForm)
if (conf.getBoolean("spark.logLineage", false)) {
logInfo("RDD's recursive dependencies:\n" + rdd.toDebugString)
}
dagScheduler.runJob(rdd, cleanedFunc, partitions, callSite, resultHandler, localProperties.get)
progressBar.foreach(_.finishAll())
rdd.doCheckpoint()
}
|
然后基本就发现了 Checkpoint 的核心方法了。而 doCheckpoint() 是 RDD 的私有方法,所以这里基本可以回答最开始提出的问题,我们在说 Checkpoint 的时候,到底是 Checkpoint 什么。答案就是 RDD。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
/**
* Performs the checkpointing of this RDD by saving this. It is called after a job using this RDD
* has completed (therefore the RDD has been materialized and potentially stored in memory).
* doCheckpoint() is called recursively on the parent RDDs.
*/
// 显然 checkpoint 是在使用完前一个 RDD 之后才会被执行的操作
private[spark] def doCheckpoint(): Unit = {
RDDOperationScope.withScope(sc, "checkpoint", allowNesting = false, ignoreParent = true) {
if (!doCheckpointCalled) {
doCheckpointCalled = true
if (checkpointData.isDefined) {
if (checkpointAllMarkedAncestors) {
// TODO We can collect all the RDDs that needs to be checkpointed, and then checkpoint
// them in parallel.
// Checkpoint parents first because our lineage will be truncated after we
// checkpoint ourselves
dependencies.foreach(_.rdd.doCheckpoint())
}
checkpointData.get.checkpoint()
} else {
dependencies.foreach(_.rdd.doCheckpoint())
}
}
}
}
|
上面代码可以看到,需要判断一下一个变量 checkpointData 是否为空。那么它是这么被定义的。
1
|
private[spark] var checkpointData: Option[RDDCheckpointData[T]] = None
|
然后看看 RDDCheckPointData 是个什么样的数据结构。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
|
/**
* This class contains all the information related to RDD checkpointing. Each instance of this
* class is associated with an RDD. It manages process of checkpointing of the associated RDD,
* as well as, manages the post-checkpoint state by providing the updated partitions,
* iterator and preferred locations of the checkpointed RDD.
*/
private[spark] abstract class RDDCheckpointData[T: ClassTag](@transient private val rdd: RDD[T])
extends Serializable {
import CheckpointState._
// The checkpoint state of the associated RDD.
protected var cpState = Initialized
// The RDD that contains our checkpointed data
// 显然,这个就是被 Checkpoint 的 RDD 的数据
private var cpRDD: Option[CheckpointRDD[T]] = None
// TODO: are we sure we need to use a global lock in the following methods?
/**
* Return whether the checkpoint data for this RDD is already persisted.
*/
def isCheckpointed: Boolean = RDDCheckpointData.synchronized {
cpState == Checkpointed
}
/**
* Materialize this RDD and persist its content.
* This is called immediately after the first action invoked on this RDD has completed.
*/
final def checkpoint(): Unit = {
// Guard against multiple threads checkpointing the same RDD by
// atomically flipping the state of this RDDCheckpointData
RDDCheckpointData.synchronized {
if (cpState == Initialized) {
cpState = CheckpointingInProgress
} else {
return
}
}
val newRDD = doCheckpoint()
// Update our state and truncate the RDD lineage
// 可以看到 cpRDD 在此处被赋值,通过 newRDD 来生成,而生成的方法是 doCheckpointa()
RDDCheckpointData.synchronized {
cpRDD = Some(newRDD)
cpState = Checkpointed
rdd.markCheckpointed()
}
}
/**
* Materialize this RDD and persist its content.
*
* Subclasses should override this method to define custom checkpointing behavior.
* @return the checkpoint RDD created in the process.
*/
// 这个是 Checkpoint RDD 的抽象方法
protected def doCheckpoint(): CheckpointRDD[T]
/**
* Return the RDD that contains our checkpointed data.
* This is only defined if the checkpoint state is `Checkpointed`.
*/
def checkpointRDD: Option[CheckpointRDD[T]] = RDDCheckpointData.synchronized { cpRDD }
/**
* Return the partitions of the resulting checkpoint RDD.
* For tests only.
*/
def getPartitions: Array[Partition] = RDDCheckpointData.synchronized {
cpRDD.map(_.partitions).getOrElse { Array.empty }
}
}
|
根据注释,可以知道这个类涵盖了 RDD Checkpoint 的所有信息。除了控制 Checkpoint 的过程,还会处理之后的状态变更。说到 Checkpoint 的状态变更,我们看看是如何定义的。
1
2
3
4
5
6
7
8
9
|
/**
* Enumeration to manage state transitions of an RDD through checkpointing
*
* [ Initialized --{@literal >} checkpointing in progress --{@literal >} checkpointed ]
*/
private[spark] object CheckpointState extends Enumeration {
type CheckpointState = Value
val Initialized, CheckpointingInProgress, Checkpointed = Value
}
|
显然 Checkpoint 的过程分为初始化[Initialized] -> 正在 Checkpoint[CheckpointingInProgress] -> 结束 Checkpoint[Checkpointed] 三种状态。
关于 RDDCheckpointData 有两个实现,分别分析一下。
- LocalRDDCheckpointData: RDD 会被保存到 Executor 本地文件系统中,以减少保存到分布式容错性文件系统的巨额开销,因此 Local 形式的 Checkpoint 是基于持久化来做的,没有写到外部分布式文件系统。
- ReliableRDDCheckpointData: Reliable 很好理解,就是把 RDD Checkpoint 到可依赖的文件系统,言下之意就是 Driver 重启的时候也可以从失败的时间点进行恢复,无需再走一次 RDD 的转换过程。
1.1 LocalRDDCheckpointData
LocalRDDCheckpointData 中的核心方法 doCheckpoint()。需要保证 RDD 用了 useDisk 级别的持久化。需要运行一个 Spark 任务来重新构建这个 RDD。最终 new 一个 LocalCheckpointRDD 实例。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
......
/**
* Ensure the RDD is fully cached so the partitions can be recovered later.
*/
protected override def doCheckpoint(): CheckpointRDD[T] = {
val level = rdd.getStorageLevel
// Assume storage level uses disk; otherwise memory eviction may cause data loss
assume(level.useDisk, s"Storage level $level is not appropriate for local checkpointing")
// Not all actions compute all partitions of the RDD (e.g. take). For correctness, we
// must cache any missing partitions. TODO: avoid running another job here (SPARK-8582).
val action = (tc: TaskContext, iterator: Iterator[T]) => Utils.getIteratorSize(iterator)
val missingPartitionIndices = rdd.partitions.map(_.index).filter { i =>
!SparkEnv.get.blockManager.master.contains(RDDBlockId(rdd.id, i))
}
if (missingPartitionIndices.nonEmpty) {
rdd.sparkContext.runJob(rdd, action, missingPartitionIndices)
}
new LocalCheckpointRDD[T](rdd)
}
.....
|
1.2 ReliableRDDCheckpointData
这个是写外部文件系统的 Checkpoint 类。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
......
/**
* Materialize this RDD and write its content to a reliable DFS.
* This is called immediately after the first action invoked on this RDD has completed.
*/
protected override def doCheckpoint(): CheckpointRDD[T] = {
val newRDD = ReliableCheckpointRDD.writeRDDToCheckpointDirectory(rdd, cpDir)
// Optionally clean our checkpoint files if the reference is out of scope
if (rdd.conf.getBoolean("spark.cleaner.referenceTracking.cleanCheckpoints", false)) {
rdd.context.cleaner.foreach { cleaner =>
cleaner.registerRDDCheckpointDataForCleanup(newRDD, rdd.id)
}
}
logInfo(s"Done checkpointing RDD ${rdd.id} to $cpDir, new parent is RDD ${newRDD.id}")
newRDD
}
......
|
可以看到核心方法是通过 ReliableCheckpointRDD.writeRDDToCheckpointDirectory() 来写 newRDD。这个方法就不进去看了,代码逻辑非常清晰,同样是起一个 Spark 任务把 RDD 生成之后按 Partition 来写到文件系统中。
Checkpoint尝试
Spark 的 Checkpoint 机制通过上文在源码上分析了一下,那么也可以在 Local 模式下实践一下。利用 spark-shell 来简单尝试一下就好了。
1
2
3
4
5
6
|
scala> val data = sc.parallelize(List(1, 2, 3))
data: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:24
scala> sc.setCheckpointDir("/tmp")
scala> data.checkpoint
scala> data.count
res2: Long = 3
|
从以上代码示例上可以看到,首先构建一个 rdd,并且设置 Checkpoint 文件夹,因为是 Local 模式,所以可以设定本地文件夹做尝试。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
# list 一下 /tmp 目录,发现 Checkpoint 的文件夹
➜ /tmp ls
73d8442e-a375-401c-b1fc-84284e25b89c
# tree 一下 Checkpoint 文件夹看看是什么结构的,可以看到默认构建的 rdd 四个分区都被 checkpoint 了
➜ /tmp tree 73d8442e-a375-401c-b1fc-84284e25b89c
73d8442e-a375-401c-b1fc-84284e25b89c
└── rdd-0
├── part-00000
├── part-00001
├── part-00002
└── part-00003
1 directory, 4 files
|
总结
至此,Spark 的 Checkpoint 机制已经说得差不多了,顺便提一下 这个 SPARK-8582 已经提出很久时间了,Spark 社区似乎一直都在尝试解决而又未有解决。大意就是每次 Checkpoint 实际上是对同一个 RDD 进行了两次计算,第一次是在程序运行的时候,第二次则是 Checkpoint 的时候就需要把这个 RDD 的转换关系重新计算一次。那么很显然,能否在第一次计算的时候就 Checkpoint 呢?这是社区几个大神的 PR 的趋势,具体大家可以参照一下 JIRA 上提及到的 PR。
警告
本文最后更新于 2017年2月1日,文中内容可能已过时,请谨慎参考。