概述
Spark 和 Elasticsearch 是90%大数据工程师的基础技术栈了,前者不用多说了,就是业界的大数据计算框架,后者则是优秀的搜索框架。
推荐系统
业务上这两个框架经常需要进行交互,常见的场景就是通过 Spark 批处理把应用日志写入 ES 集群来构架,然后通过 Kibana 进行展示。特定场景下 ES 除了可以做搜索引擎以外,还可以作为存储方案。
笔者在两者的交互上使用较多,其中一个有意思的场景是用他们来构建推荐系统的召回层。所谓的召回层,可以理解成根据用户属性,在内容池子中,根据特定策略来挑选符合用户特征的内容(在进行推荐之前,一般还会有一个重排系统,来对召回内容进行打分,来判定推荐的顺序)。
在召回系统中用 ES 的好处是可以利用其搜索引擎的天然属性,来构建复杂的查询语句,假设用户属性很多,召回策略非常复杂的情况下,如果使用 sql 对内容进行查询,可能需要写出很复杂的语句,并且检索效率不会比使用 ES 更好。
在推荐系统中,Spark 和 ES 的交互可以发生在这样的场景。批处理情况下,可以通过 Spark Sql 来计算用户的新增属性,例如通过算法,来为用户画像增加不同维度的特征,例如计算用户对某种内容的偏好程度,并将计算完的特征写入 ES 集群。流处理情况下,Spark Streaming 来对用户实现秒级的画像更新,并更新存储在 ES 中的数据。最后根据召回策略来组合查询的 query 来实现复杂的查询。
下面是我们业务中一个查询示例(特征名和敏感数据进行了处理):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
{
"query": {
"bool": {
"filter": [
{
"terms": {
"pr": [
"-1",
"-2",
"3",
"6",
"7"
]
}
},
{
"bool": {
"should": [
{
"term": {
"vt": {
"value": "2"
}
}
}
]
}
}
]
}
},
"size": 1000,
"sort": [
{
"ok": {
"missing": "_last",
"order": "desc"
}
}
]
}
|
通过以上 query 可以把符合用户特征的内容召回出来。
交互操作
为了把内容写入 ES 集群,我们可以在本地简单的跑起来一个 Demo。首先,你需要一个本地的 ES 集群,brew install elasticsearch 安装 ES,然后运行 elasticsearch 命令来运行一个默认配置的集群。

然后可以通过官方文档的一个 Demo 来尝试一下把数据通过 Spark 写入到集群当中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.elasticsearch.spark._
object Write2Es {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("test").setMaster("local")
conf.set("es.nodes", "localhost")
conf.set("es.port", "9200")
conf.set("es.index.auto.create", "true")
conf.set("es.mapping.id", "one")
conf.set("es.write.operation", "upsert")
val sc = new SparkContext(conf)
val numbers = Map("one" -> 1, "five" -> 8)
val numbers1 = Map("one" -> 3)
sc.makeRDD(Seq(numbers, numbers1)).saveToEs("spark/docsid")
}
}
|
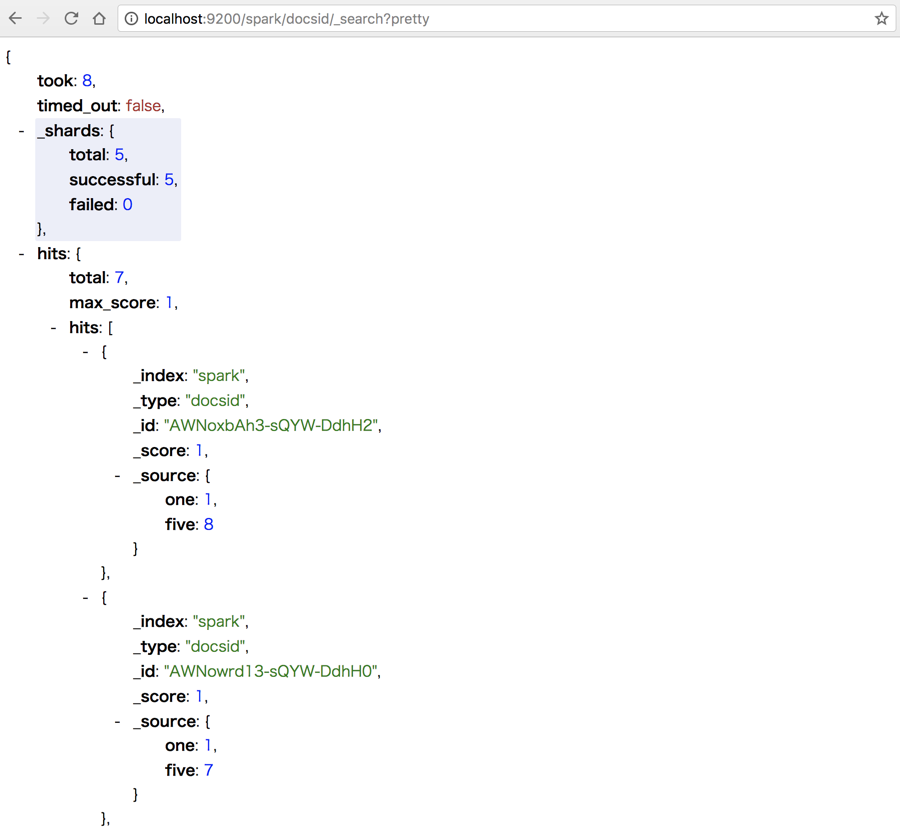
写入数据之后通过 RESTful 接口查看数据如下:
参考资料
- Apache Spark support
警告
本文最后更新于 2017年2月1日,文中内容可能已过时,请谨慎参考。