Spark动态资源分配Dynamic-Resource-Allocation
概述
Spark中所谓资源单位一般指的是 executors,和 Yarn 中的 Containers 一样,在 Spark On Yarn 模式下,通常使用 –num-executors 来指定 Application 使用的 executors 数量,而 –executor-memory 和 –executor-cores 分别用来指定每个 executor 所使用的内存和虚拟CPU核数。相信很多朋友至今在提交 Spark 应用程序时候都使用该方式来指定资源。
假设有这样的场景,如果使用 Hive,多个用户同时使用 hive-cli 做数据开发和分析,只有当用户提交执行了 Hive SQL 时候,才会向 YARN 申请资源,执行任务,如果不提交执行,无非就是停留在 Hive-cli 命令行,也就是个 JVM 而已,并不会浪费 YARN 的资源。现在想用 Spark-SQL 代替 Hive 来做数据开发和分析,也是多用户同时使用,如果按照之前的方式,以 yarn-client 模式运行 spark-sql 命令行,在启动时候指定–num-executors 10,那么每个用户启动时候都使用了10个 YARN 的资源(Container),这10个资源就会一直被占用着,只有当用户退出 spark-sql 命令行时才会释放。
spark-sql On Yarn,能不能像 Hive 一样,执行 SQL 的时候才去申请资源,不执行的时候就释放掉资源呢,其实从Spark1.2之后,对于 On Yarn 模式,已经支持动态资源分配(Dynamic Resource Allocation),这样,就可以根据Application的负载(Task情况),动态的增加和减少 executors,这种策略非常适合在 YARN 上使用 spark-sql 做数据开发和分析,以及将 spark-sql 作为长服务来使用的场景。
本文以 Spark1.5.0 和 hadoop-2.3.0-cdh5.0.0,介绍在 spark-sql On Yarn 模式下,如何使用动态资源分配策略。
YARN的配置
首先需要对 YARN 的 NodeManager 进行配置,使其支持 Spark 的 Shuffle Service。
修改每台NodeManager上的yarn-site.xml。
|
|
将 $SPARK_HOME/lib/spark-1.5.0-yarn-shuffle.jar 拷贝到每台 NodeManager 的 ${HADOOP_HOME}/share/hadoop/yarn/lib/ 下。重启所有NodeManager。
Spark的配置
配置$SPARK_HOME/conf/spark-defaults.conf,增加以下参数:
|
|
动态资源分配策略:
开启动态分配策略后,application会在task因没有足够资源被挂起的时候去动态申请资源,这种情况意味着该application现有的executor无法满足所有task并行运行。spark一轮一轮的申请资源,当有task挂起或等待spark.dynamicAllocation.schedulerBacklogTimeout(默认1s)时间的时候,会开始动态资源分配;之后会每隔spark.dynamicAllocation.sustainedSchedulerBacklogTimeout(默认1s)时间申请一次,直到申请到足够的资源。每次申请的资源量是指数增长的,即1,2,4,8等。
之所以采用指数增长,出于两方面考虑:其一,开始申请的少是考虑到可能application会马上得到满足;其次要成倍增加,是为了防止application需要很多资源,而该方式可以在很少次数的申请之后得到满足。
资源回收策略:
当application的executor空闲时间超过spark.dynamicAllocation.executorIdleTimeout(默认60s)后,就会被回收。
使用spark-sql On Yarn执行SQL,动态分配资源
|
|

该查询需要123个Task。
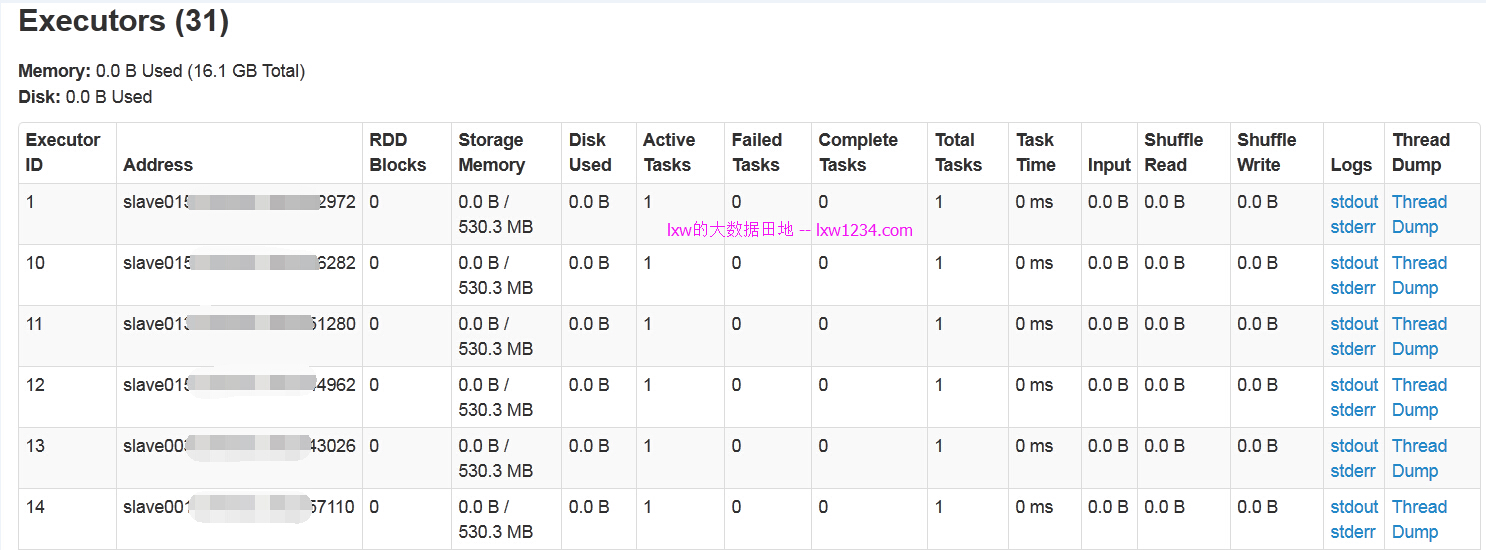
从AppMaster的WEB界面可以看到,总共有31个Executors,其中一个是Driver,既有30个Executors并发执行,而30,正是在spark.dynamicAllocation.maxExecutors参数中配置的最大并发数。如果一个查询只有10个Task,那么只会向Yarn申请10个executors的资源。
需要注意:
如果使用./spark-sql –master yarn-client –executor-memory 1G
进入spark-sql命令行,在命令行中执行任何SQL查询,都不会执行,原因是spark-sql在提交到Yarn时候,已经被当成一个Application,而这种,除了Driver,是不会被分配到任何executors资源的,所有,你提交的查询因为没有executor而不能被执行。
而这个问题,我使用Spark的ThriftServer(HiveServer2)得以解决。
使用Thrift JDBC方式执行SQL,动态分配资源
首选以yarn-client模式,启动Spark的ThriftServer服务,也就是HiveServer2。
配置ThriftServer监听的端口号和地址:
|
|
以yarn-client模式启动ThriftServer:
|
|
启动后,ThriftServer会在Yarn上作为一个长服务来运行:

使用beeline通过JDBC连接spark-sql:
|
|
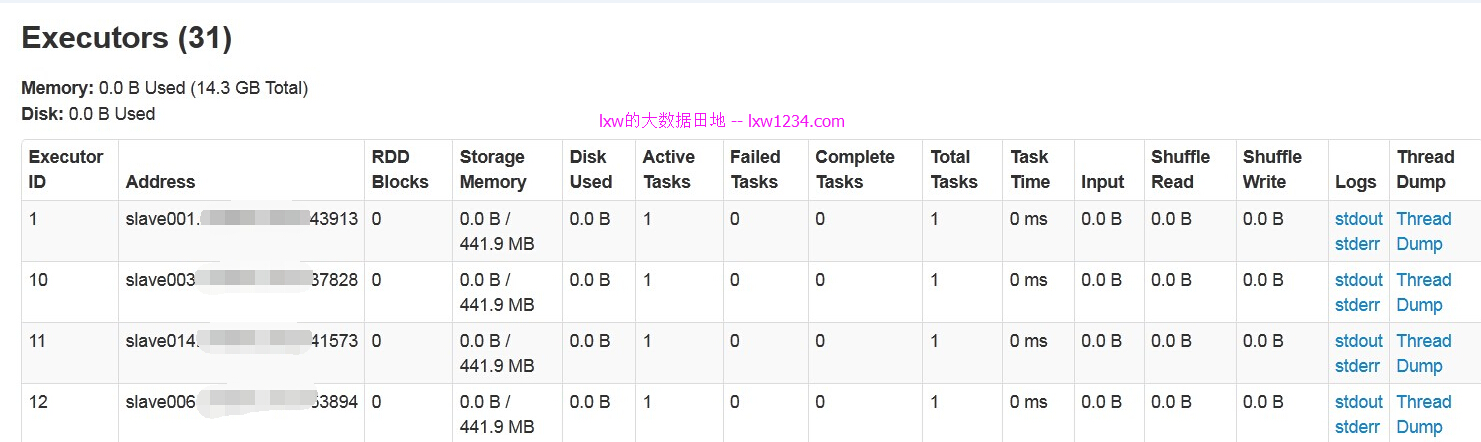
执行查询select count(1) from ut.t_ut_site_log where pt = ‘2015-12-10′;,该任务有64个Task:

而监控页面上的并发数仍然是30:
执行完后,executors数只剩下1个,应该是缓存数据,其余的全部被回收:
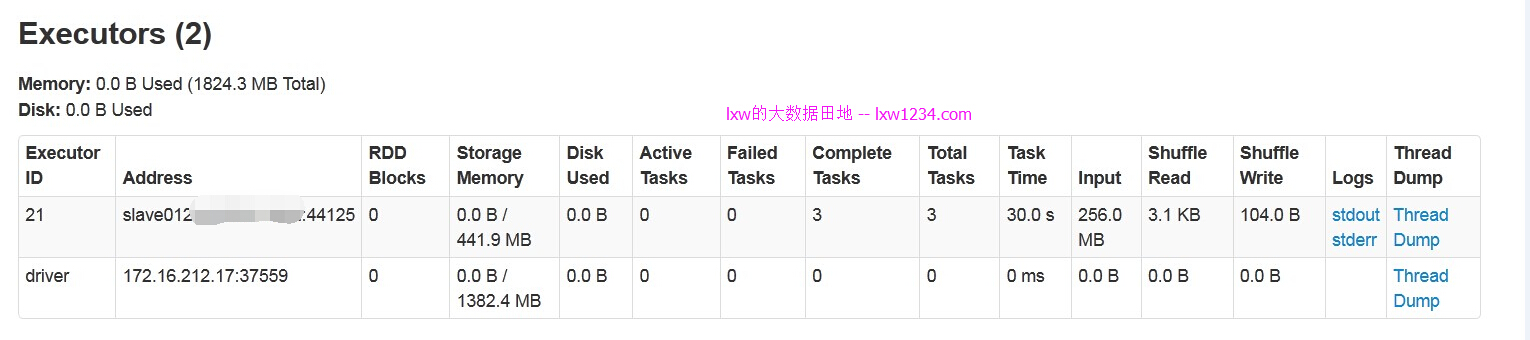
这样,多个用户可以通过beeline,JDBC连接到Thrift Server,执行SQL查询,而资源也是动态分配的。
需要注意的是,在启动ThriftServer时候指定的spark.dynamicAllocation.maxExecutors=30,是整个ThriftServer同时并发的最大资源数,如果多个用户同时连接,则会被多个用户共享竞争,总共30个。
这样,也算是解决了多用户同时使用spark-sql,并且动态分配资源的需求了。
Spark动态资源分配官方文档:http://spark.apache.org/docs/1.5.0/job-scheduling.html#dynamic-resource-allocation