Spark关于Kerberos解决的问题
目录
概述
Spark 跟 Hadoop 生态的紧密联系就不用多说了,由于最近在处理一个 Kerberos 相关的问题,所以就好奇看看 Spark 里是怎么操作 Kerberos 认证的,以后如果有需要自己做的话,也可以做个参考。
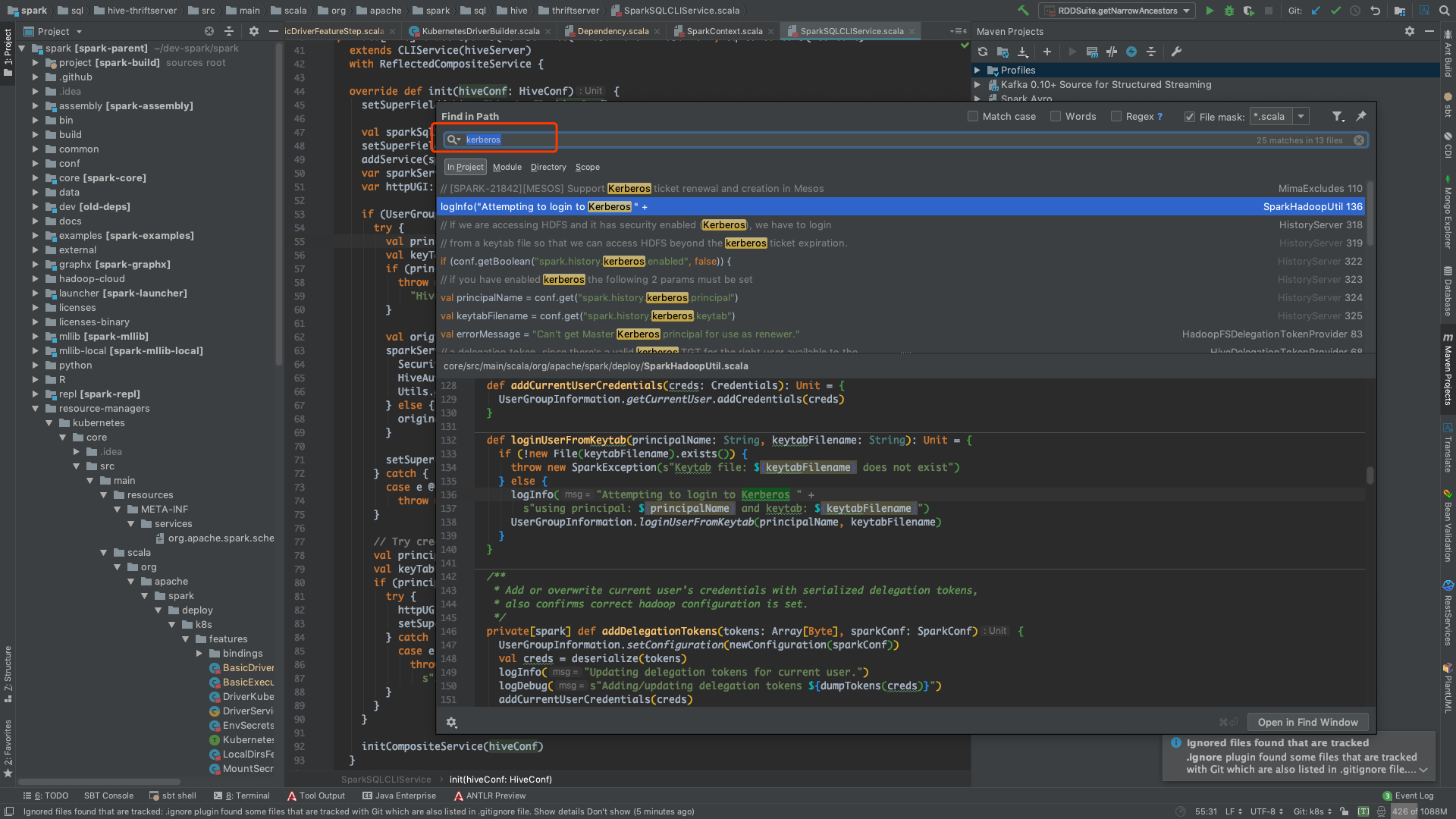
可以看到,相关的代码,还不少。
代码
loginUserFromKeytab

首先关注到的是 core 里面的 SparkHadoopUtil 这个类(core 里的代码一般都比较重要)。然后就发现,这个方法是跟 HistoryServer 有关系的,如下图。

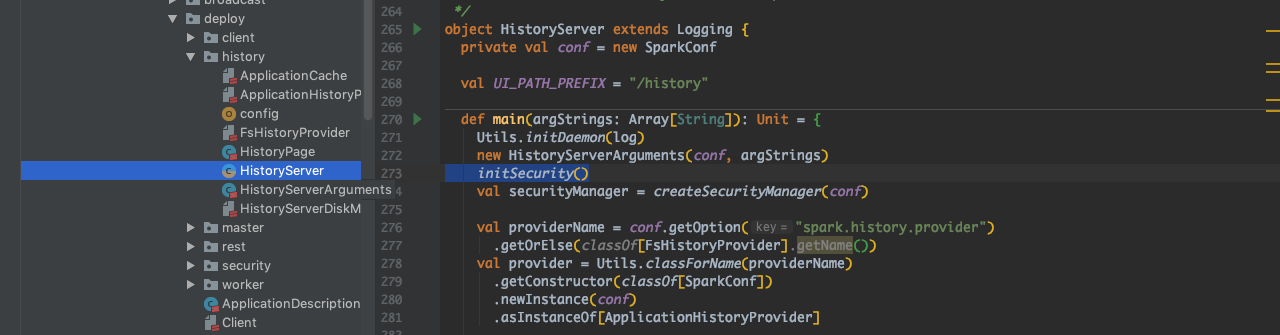
很好理解,因为 HistoryServer 用来写入 EventLog,那么读写都是在 HDFS 上的,如果 HDFS 是 Kerberized 的,那就肯定要用 Keytab 了。
AMCredentialRenewer
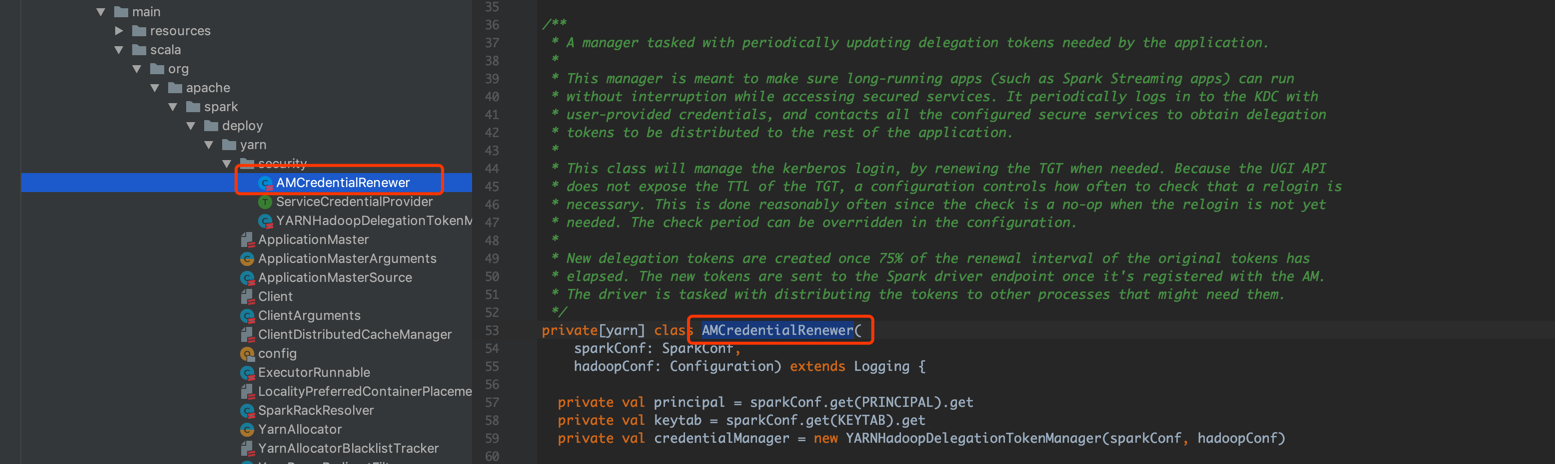
然后就是 AMCredentialRenewer,我把他的注释摘出来解读一下。这个类主要作用就是起一个 daemon 线程,去定时更新 token。
警告
本文最后更新于 2017年2月1日,文中内容可能已过时,请谨慎参考。