概述
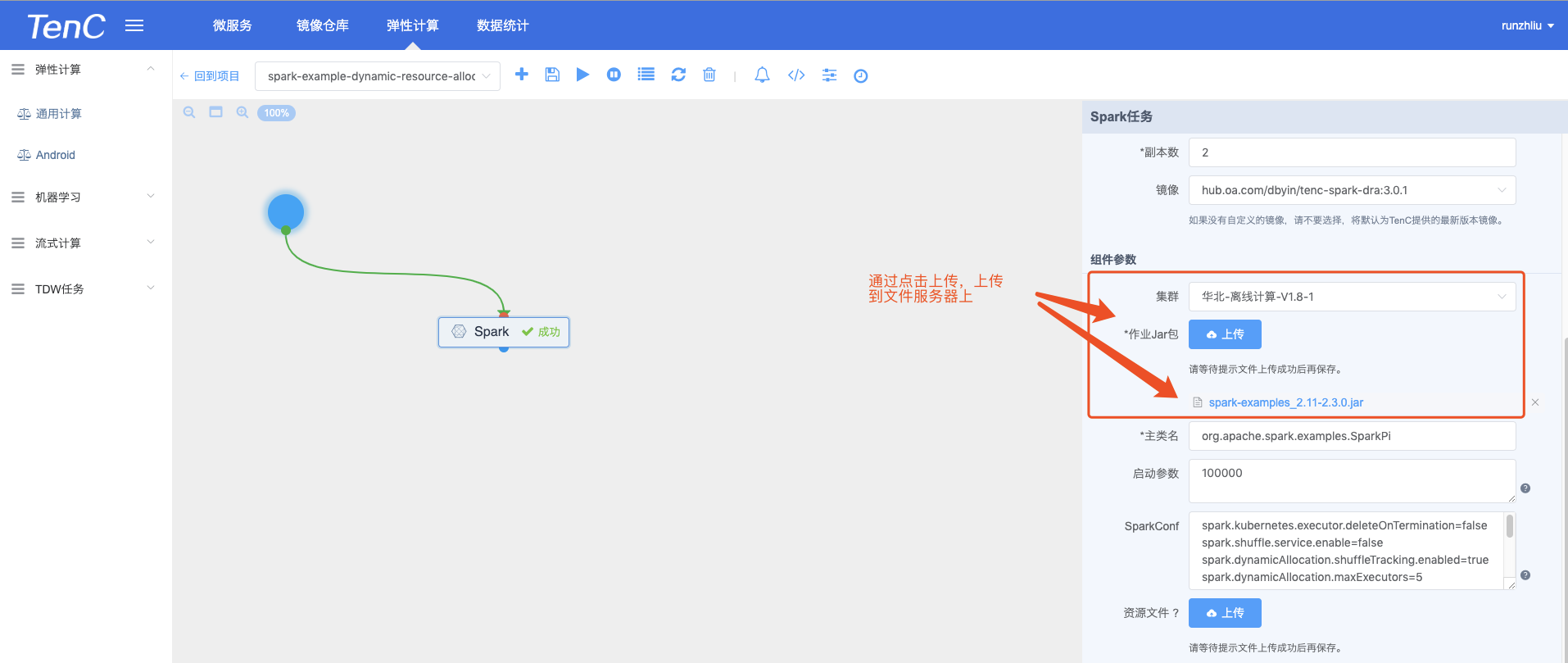
熟悉 Spark 的用户都知道,Spark 的 Application Jar 以及一些资源文件都需要一个 Submit/Driver/Executor 可达的地址,通常来都会通过 Local 或 HDFS 和 HTTP 服务的方式来提供。以往 TenC 弹性计算 Spark 任务是通过 HTTP/CEPH 的方式,或者用户将资源文件打包如镜像来提供服务的。

S3 是著名的对象存储服务,TenC 弹性计算 Spark 计算任务支持用户通过 S3 上传 Application Jar 文件以及其他资源文件(暂时不支持 HTTP 的方式了),具体的使用方法如下。
假设用户已经上传 jar 包到 S3,如下地址。
1
|
s3://testradosgw.cephrados.so.db:7480/runzhliu__runzhliu/spark-examples_2.12-3.0.0-SNAPSHOT.jar
|
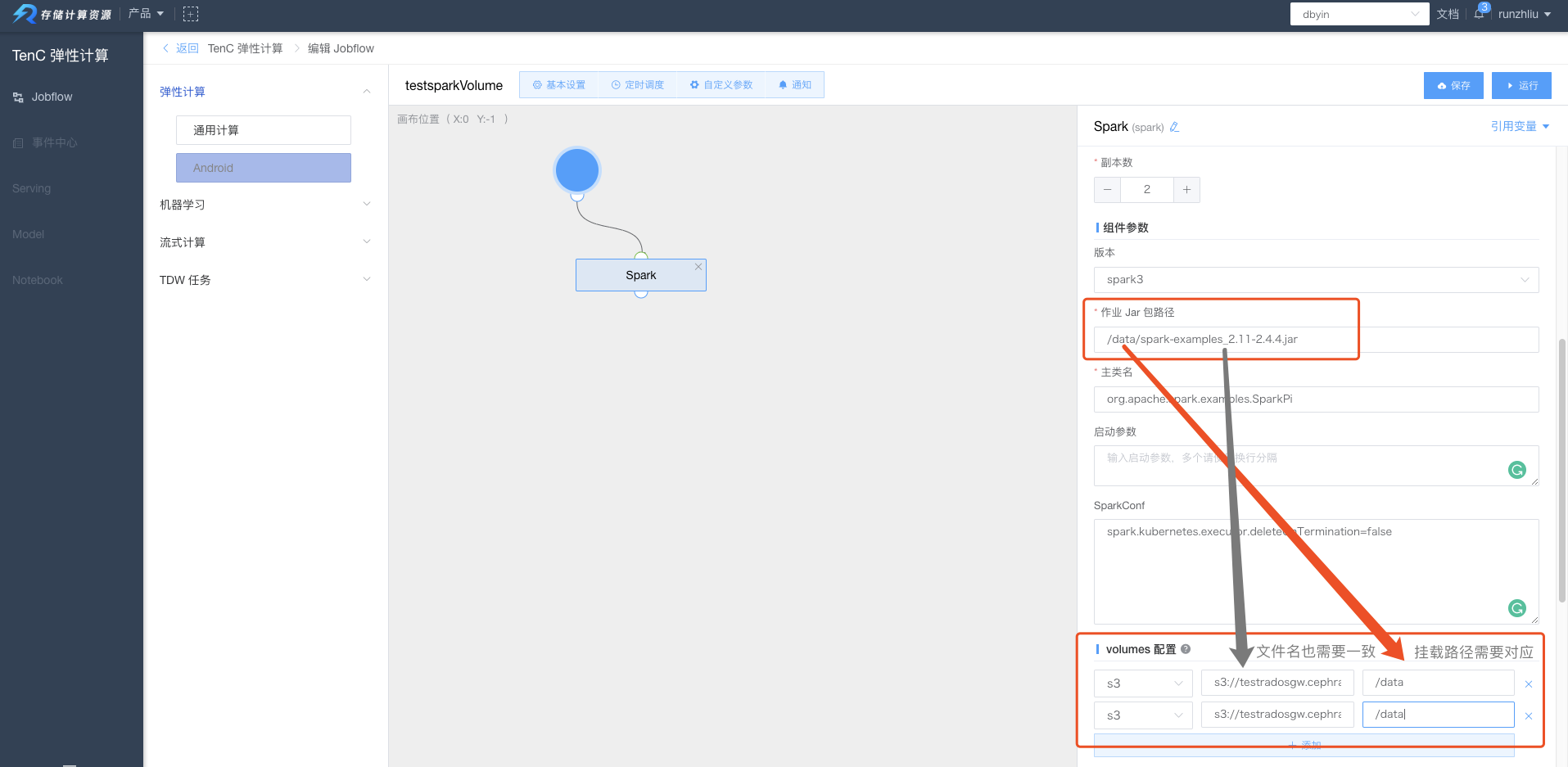
通过 Spark 计算任务页面,将该 jar 包通过放在 /data 目录下。这个目录可以当做是在后面 Spark 应用启动之后的本地目录,所以作业 Jar 包路径 就需要填入这样的地址 /data/spark-examples_2.11-2.4.4.jar
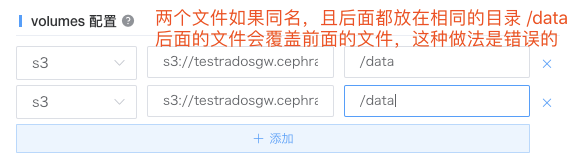
这里需要注意的是,如果需要配置多个 volumes 配置,请注意 S3 多个文件,如果同名,那么后面的地址不能写作一样,否则就会被后面的文件覆盖。
TenC Spark
在 TenC Spark 计算任务中,Spark Operator 在创建 Driver/Executor Pod 的时候,都会根据 volumes 配置,通过 init-container 的方式将 S3 的文件下载到容器的指定目录中。
由于 Spark 官方已经将 init-container 的逻辑去除,所以 TenC Spark 做了一点修改,会根据 volumes 配置来创建 init-container,具体的代码逻辑如下。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
|
/**
* Mount S3 volume by init-container
*/
def buildPodWithInitContainer(pod: Pod, conf: SparkConf): Pod = {
val needInitContainer = conf.get(Config.KUBERNETES_NEED_INITCONTAINER)
if (needInitContainer) {
var configuredPod = pod
// parse s3 args
val s3Mounts = conf.getAllWithPrefix(Config.KUBERNETES_TENC_PREFIX)
.map(x => {
val mps = x._2.split("\n")
S3Mount(x._1, mps(0), mps(1), mps(2), mps(3))
})
// s3 volumes could be multiple with multiple init-containers
s3Mounts.foreach {
s3 => {
// set up empty volume
val vl = new VolumeBuilder()
.withEmptyDir(new EmptyDirVolumeSource("", new Quantity()))
.withName(s3.mountName)
.build()
// set up volumeMount
val vm = new VolumeMountBuilder()
.withName(vl.getName)
.withMountPath(s3.mountPath)
.build()
configuredPod = new PodBuilder(configuredPod)
.editSpec()
.addToVolumes(vl)
.editFirstContainer()
.addToVolumeMounts(vm)
.endContainer()
.addNewInitContainer()
.withName(s3.mountName)
.withImage(conf.get(Config.KUBERNETES_INITCONTAINER_IMAGE))
.withArgs(s3.url, s3.mountPath)
.withEnv(
new EnvVarBuilder().withName("ACCESS_KEY").withValue(s3.accessKey).build(),
new EnvVarBuilder().withName("SECRET_KEY").withValue(s3.secretKey).build()
).addToVolumeMounts(vm)
.endInitContainer()
.endSpec()
.build()
}
}
configuredPod
} else {
pod
}
}
case class S3Mount(
mountName: String,
url: String,
accessKey: String,
secretKey: String,
mountPath: String)
|
然后这个在 KubernetesUtils.buildPodWithInitContainer() 这个方法会在创建 Driver/Executor Pod 的时候都会调用,所以每次 Pod 创建时,都会通过先创建 init-container 来挂载这些文件。
默认 TenC Spark Operator 会给 SparkConf 加上下面的一些配置。
1
2
3
4
|
spark.kubernetes.tenc.need.initContainer
spark.kubernetes.tenc.initContainer.image
// prefix
spark.kubernetes.tenc.s3.xxx
|
当 volumes 配置 配置正确,spark.kubernetes.tenc.need.initContainer=true,会触发配置 init-container 的流程,然后 volumes 配置 的参数会通过 spark.kubernetes.tenc.s3.xxx 的一系列参数将 Volume 创建 emptyDir,并由 Kubernetes 将其挂载到 Driver/Executor 的 Pod 上。
总结
以往通过 HTTP 服务的方式,由于用户有时候需要启动成百上千的 Executor,所以此时我们的文件服务器压力比较大,经常会因为拉取超时或者 DNS 访问出错而导致任务失败,目前改由 S3 的方式,相信一定程度上会缓解任务因为 Jar 包拉取问题而失败的情况。
因为 Spark on Kubernetes 社区的代码一直在变化,为了增加 init-container 这只是一个临时的实现,所以不一定是最优的方案,如果有这方面的需求或者建议,欢迎各位同学提出!
警告
本文最后更新于 2017年2月1日,文中内容可能已过时,请谨慎参考。