概述
本文主要是结合 Rook 官方文档 v1.3,以及 Ceph 14.2.9 ,再加上自己的实践经验以及查看 Rook 的源码总结出来的,如果对文章任何内容有疑问,可以先参考一下官方文档或者 Rook v1.3 版本的源码。
Rook Quickstart
这里主要强调一下官方关于集群机器的存储设备方面的要求。下面这三个要求是或者的关系,任意满足其中之一即可,也就是要么有一块没有任何分区和文件系统的磁盘裸设备,要么就是没有文件系统的磁盘分区,要么就是有支持 block 模式的 PVs。
- Raw devices (no partitions or formatted filesystems)
- Raw partitions (no formatted filesystem)
- PVs available from a storage class in block mode
Rook测试机型配置
由于公司机器上架的流程问题,所以某些机型只会挂载一个硬盘,而如果需要单独挂载另外的硬盘,该硬盘还是会被格式化成 xfs 文件系统的。
BlueStore 是新一代的高性能对象存储后端。BlueStore 因为绕过了本地文件系统,资深接管裸设备,直接进行对象操作,不需要进行对象和文件的转换,🙆对象存储的I/
| IP |
机型 |
配置 |
| 10.50.146.222 |
Z3 |
23核,58G内存,794G磁盘,61台子机,1Gbps千兆网卡 |
| 10.50.146.223 |
Z3 |
23核,58G内存,794G磁盘,61台子机,1Gbps千兆网卡 |
| 10.50.86.213 |
Z3 |
23核,58G内存,794G磁盘,61台子机,1Gbps千兆网卡 |
这三台主要作为 osd 部署的机器,因为 osd 如果采用 Bluestore 的文件系统需要除了系统盘之外还多一个盘,并且这个盘最好是没有文件系统的裸盘。同时因为机器该集群合适的机器不多(有部分 windows 的机器),所以可以让 osd/mon/mgr 调度到合适的节点,可以给 Node 打上 Label,同时给 cluster.yaml 里对应组件的 NodeAffinity。
1
2
3
4
|
NAME VERSION LABELS
10.50.146.222 v1.14.10-tk8s.1 ceph-mon=enabled,ceph-osd=enabled
10.50.146.223 v1.14.10-tk8s.1 ceph-mon=enabled,ceph-osd=enabled
10.50.86.213 v1.14.10-tk8s.1 ceph-mgr=enabled,ceph-mon=enabled,ceph-osd=enabled
|
按照这个 Label,以及下面的 cluster.yaml 配置,就可以正常运行了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
# placement这里的意思就是Pod会被调度到哪里的意思
# 这里除了用NodeAffinity的属性还可以用其他调度的关键词
placement:
mon:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: ceph-mon
operator: In
values:
- enabled
osd:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: ceph-osd
operator: In
values:
- enabled
mgr:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: ceph-mgr
operator: In
values:
- enabled
|
Operator 可以在不同的 Namespace 下创建不同的集群,但是需要在 common.yaml 进行一些特殊的配置。common.yaml 里创建了很多 CRD。这些可以在 Rook 源码里找下定义。
1
2
3
4
5
6
7
8
9
10
|
cephclusters.ceph.rook.io
cephclients.ceph.rook.io
cephrbdmirrors.ceph.rook.io
cephfilesystems.ceph.rook.io
cephnfses.ceph.rook.io
cephobjectstores.ceph.rook.io
cephobjectstoreusers.ceph.rook.io
cephblockpools.ceph.rook.io
objectbuckets.objectbucket.io
objectbucketclaims.objectbucket.io
|
对象存储Object Storage
对象存储的创建,实际上是创建 CephObjectStore 这个 CRD 对象,这里主要是创建了 RGW 的服务。下面是一个简单的例子。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
apiVersion: ceph.rook.io/v1
kind: CephObjectStore
metadata:
name: my-store
namespace: rook-ceph
spec:
metadataPool:
failureDomain: host
replicated:
size: 3
dataPool:
failureDomain: host
erasureCoded:
dataChunks: 2
codingChunks: 1
preservePoolsOnDelete: true
gateway:
type: s3
sslCertificateRef:
port: 80
securePort:
instances: 1
|
如果有运维 Ceph 集群经验的同学,尤其是对象存储的话,可以看看 Pod 里具体的命令,看看 Rook 是怎么起来一个 RGW 服务的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
- args:
- --fsid=47527199-dfaf-42c8-ab96-47801eafe2c2
- --keyring=/etc/ceph/keyring-store/keyring
- --log-to-stderr=true
- --err-to-stderr=true
- --mon-cluster-log-to-stderr=true
- '--log-stderr-prefix=debug '
- --default-log-to-file=false
- --default-mon-cluster-log-to-file=false
- --mon-host=$(ROOK_CEPH_MON_HOST)
- --mon-initial-members=$(ROOK_CEPH_MON_INITIAL_MEMBERS)
- --id=rgw.my.store.a
- --setuser=ceph
- --setgroup=ceph
- --foreground
- --rgw-frontends=beast port=8080
- --host=$(POD_NAME)
- --rgw-mime-types-file=/etc/ceph/rgw/mime.types
command:
- radosgw
|
状态查询
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
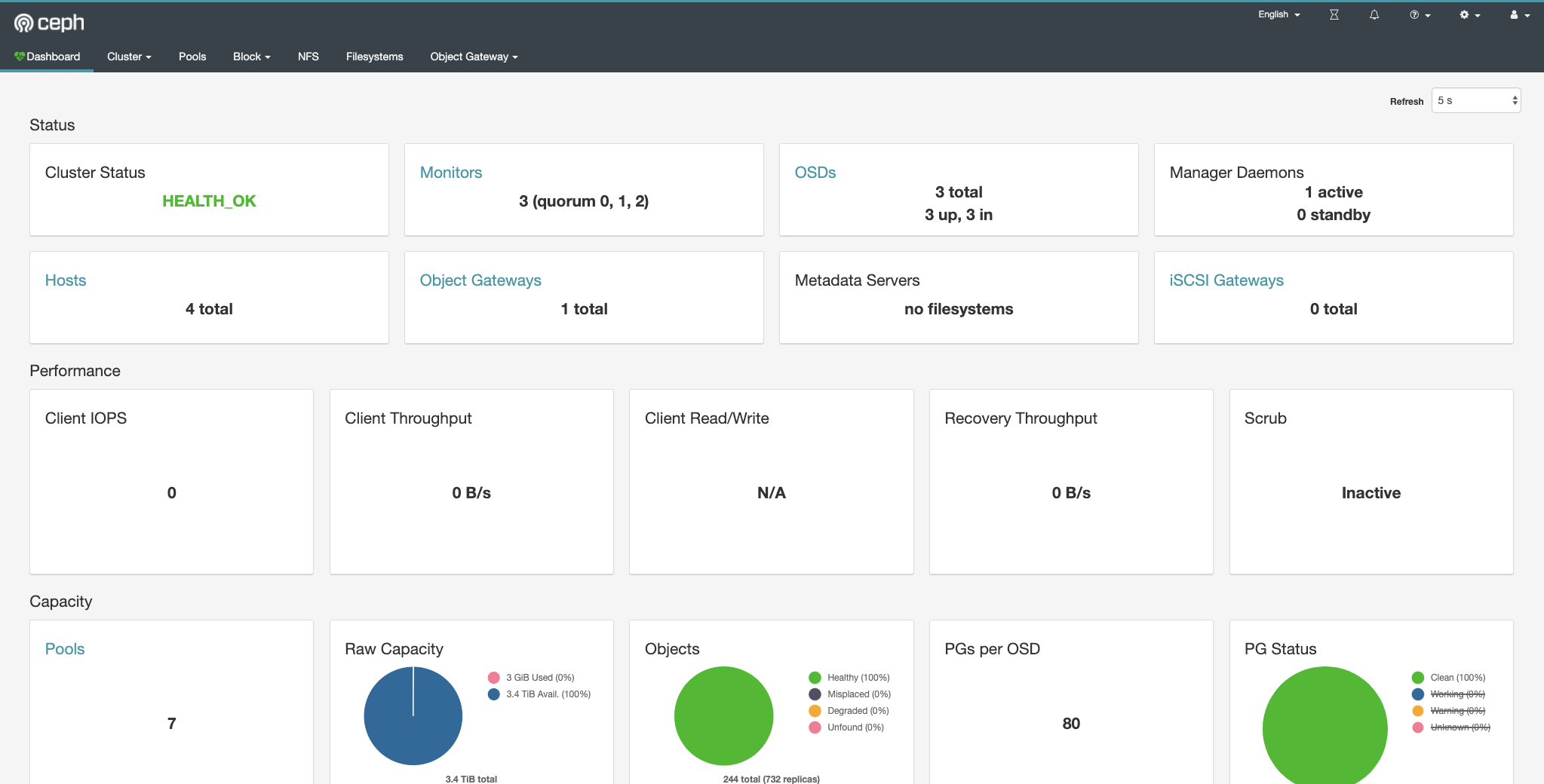
# ceph status
cluster:
id: 47527199-dfaf-42c8-ab96-47801eafe2c2
health: HEALTH_OK
services:
mon: 3 daemons, quorum a,b,c (age 2d)
mgr: a(active, since 15h)
osd: 3 osds: 3 up (since 2d), 3 in (since 2d)
rgw: 1 daemon active (my.store.a)
data:
pools: 7 pools, 80 pgs
objects: 251 objects, 5.9 KiB
usage: 3.0 GiB used, 3.4 TiB / 3.4 TiB avail
pgs: 80 active+clean
|

关于对象网关存储,需要创建一个 --system 标记的用户。详情参考 Ceph官方文档。
1
|
radosgw-admin user create --uid=runzhliu --display-name=runzhliu --system
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
rm -rf /var/lib/rook
rm -rf /var/lib/ceph
pvremove -y -ff /dev/fioa
kubectl -n default get cm ceph-delete-bucket -o yaml | grep BUCKET_HOST | awk '{print $2}'
kubectl -n default get secret ceph-delete-bucket -o yaml | grep AWS_ACCESS_KEY_ID | awk '{print $2}' | base64 --decode
kubectl -n default get secret ceph-delete-bucket -o yaml | grep AWS_SECRET_ACCESS_KEY | awk '{print $2}' | base64 --decode
export AWS_HOST=rook-ceph-rgw-my-store.rook-ceph
export AWS_ACCESS_KEY_ID=CFNY8EM7HETH1S4GE4L5
export AWS_SECRET_ACCESS_KEY=9SxFgUm6BunIaI6UDeKF3CTnA7Xm03Rr8PJBXdpV
export AWS_ENDPOINT=172.17.229.128:80
kubectl -n rook-ceph get svc rook-ceph-rgw-my-store
export AWS_HOST=rook-ceph-rgw-my-store.rook-ceph
export AWS_ACCESS_KEY_ID=WFZC9ML6AY7IKBUX4AYO
export AWS_SECRET_ACCESS_KEY=z6DdnAbypXvzIEoswEtX7xj0CEOmWyUTILlJGXwf
export AWS_ENDPOINT=172.17.229.128:80
|
部署的最终结果
因为部分 Pod 是来源于 DaemonSet 的,所以有些 Pod 并未真正的创建出来,但是因为测试集群的机型和 Label 特别多,所以 DaemonSet 也会被调度到这些实际不应该调度上去的 Node 上。【关于这点如何规避?】
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
|
# kubectl get pods -n rook-ceph
NAME READY STATUS RESTARTS AGE
csi-cephfsplugin-7j79d 0/3 ContainerCreating 0 22h
csi-cephfsplugin-944vv 0/3 ContainerCreating 0 2d2h
csi-cephfsplugin-dlpqp 0/3 ContainerCreating 0 2d2h
csi-cephfsplugin-fxkvw 0/3 ContainerCreating 0 2d2h
csi-cephfsplugin-hm2zq 3/3 Running 0 2d2h
csi-cephfsplugin-hw92g 0/3 ContainerCreating 0 46h
csi-cephfsplugin-lngqd 0/3 ContainerCreating 0 2d2h
csi-cephfsplugin-mx9bc 0/3 ContainerCreating 0 2d2h
csi-cephfsplugin-mz4h6 0/3 ContainerCreating 0 2d2h
csi-cephfsplugin-provisioner-8446b99fb7-642d5 5/5 Running 0 2d2h
csi-cephfsplugin-provisioner-8446b99fb7-fdxmw 5/5 Running 0 2d2h
csi-cephfsplugin-t84j7 0/3 ContainerCreating 0 2d2h
csi-cephfsplugin-ttvpt 3/3 Running 0 2d2h
csi-rbdplugin-5t547 3/3 Running 0 2d2h
csi-rbdplugin-6kl7l 0/3 ContainerCreating 0 2d2h
csi-rbdplugin-9g2cj 0/3 ContainerCreating 0 46h
csi-rbdplugin-c5czv 0/3 ContainerCreating 0 2d2h
csi-rbdplugin-ch9gf 0/3 ContainerCreating 0 2d2h
csi-rbdplugin-d4d4l 0/3 ContainerCreating 0 2d2h
csi-rbdplugin-hbwjk 0/3 ContainerCreating 0 2d2h
csi-rbdplugin-k2gqk 0/3 ContainerCreating 0 2d2h
csi-rbdplugin-provisioner-675fc95ff7-cq76r 6/6 Running 0 2d2h
csi-rbdplugin-provisioner-675fc95ff7-l4dcz 6/6 Running 0 2d2h
csi-rbdplugin-qzqf5 3/3 Running 0 2d2h
csi-rbdplugin-spqfz 0/3 ContainerCreating 0 22h
csi-rbdplugin-zggsf 0/3 ContainerCreating 0 2d2h
lb-rgw-0 2/2 Running 0 11h
lb-rook-ceph-dashboard-0 2/2 Running 0 12h
rook-ceph-mgr-a-65df97f769-dpdfv 1/1 Running 0 2d2h
rook-ceph-mon-a-67fb49667b-gkmp9 1/1 Running 0 2d2h
rook-ceph-mon-b-5fbdcfc4f4-ttvd7 1/1 Running 0 2d2h
rook-ceph-mon-c-56c794f69-vjvfx 1/1 Running 0 2d2h
rook-ceph-operator-6954d454d4-jhhjn 1/1 Running 0 2d
rook-ceph-osd-0-9f44784c5-8sl9m 1/1 Running 0 2d2h
rook-ceph-osd-1-7d58767784-t76w5 1/1 Running 0 2d2h
rook-ceph-osd-2-78585b5d8c-zmh2x 1/1 Running 0 2d2h
rook-ceph-osd-prepare-10.50.146.222-hlgdt 0/1 Completed 0 15h
rook-ceph-osd-prepare-10.50.146.223-b5jhh 0/1 Completed 0 15h
rook-ceph-osd-prepare-10.50.86.213-q2m7n 0/1 Completed 0 15h
rook-ceph-rgw-my-store-a-57c4f8445d-zvp59 1/1 Running 0 2d1h
rook-ceph-tools-7df5bf76bf-z8vvc 1/1 Running 0 2d2h
rook-discover-5chw9 1/1 Running 0 2d2h
rook-discover-6cwhq 1/1 Running 0 2d2h
rook-discover-csc8d 1/1 Running 0 2d2h
rook-discover-d652s 0/1 UnexpectedAdmissionError 0 16m
rook-discover-dk6wz 1/1 Running 0 2d2h
rook-discover-g4wvl 1/1 Running 0 2d2h
rook-discover-kr5s8 0/1 ContainerCreating 0 46h
rook-discover-kxqnp 1/1 Running 0 2d2h
rook-discover-rrfxf 0/1 ContainerCreating 0 2d2h
rook-discover-t5dpn 1/1 Running 0 2d2h
rook-discover-x52s9 1/1 Running 0 2d2h
|
关于无法创建osd Pod
Rook 创建 Operator 后,会经过几个过程,而在创建 osd Pod 之前,需要先通过 osd-prepare Job 的过程,主要是会检查所有节点的情况。
1
2
3
|
job.batch/rook-ceph-osd-prepare-10.50.146.222 1/1 4s 87m
job.batch/rook-ceph-osd-prepare-10.50.146.223 1/1 4s 87m
job.batch/rook-ceph-osd-prepare-10.50.86.213 1/1 4s 87m
|
比如说会检查所有磁盘的所有分区,如果磁盘有分区且已经格式化文件系统,那么这个设备 device 会被 skip 掉。osd 是作为一个 DaemonSet 存在的,他会做很多检查。
Ceph 查找数据的物理位置
Ceph Rook Quota 的配置
Ceph Rook 压测
https://my.oschina.net/u/1169457/blog/740819
1
2
3
4
|
ceph status
ceph osd status
ceph df
rados df
|
Rook
目前 Ceph 官方也推荐 Rook 作为 Kubernetes 部署 Ceph 集群的方案。几个关键问题,必须提前调研清楚。
- 滚动更新
- 扩缩容
- 数据迁移
- 清理逻辑Clean guide
关于部署,需要上架 DBA 的机型,因为要确保有多一块磁盘,可以参考 Rook 安装的 prerequisites。
- Raw devices (no partitions or formatted filesystems)
- Raw partitions (no formatted filesystem)
- PVs available from a storage class in block mode
先 umount 挂载点,再清除分区。
对于已经分过区的,可以通过下面的命令干掉文件系统。
1
|
dd if=/dev/zero of=/dev/fioa bs=512K count=1
|
关于 Ceph Cluster CRD,竟然还可以不通过裸设备来搞的?
- Specify host paths and raw devices
- Specify the storage class Rook should use to consume storage via PVCs
清理工作。
1
2
3
4
5
|
kubectl delete cm -n rook-ceph --all
kubectl delete all -n rook-ceph --all --force --grace-period 0
kubectl delete -f common.yaml
kubectl delete cephclusters.ceph.rook.io -n rook-ceph --all
rm -rf /var/lib/rock
|
kubectl patch crd objectbucketclaims.objectbucket.io -p ‘{“metadata”:{“finalizers”: null}}’
kubectl patch crd objectbuckets.objectbucket.io -p ‘{“metadata”:{“finalizers”: null}}’
创建工作。
1
2
3
4
|
kubectl create -f common.yaml
kubectl create -f operator.yaml
kubectl create -f cluster-test.yaml
kubectl create -f pvc-based-cluster.yaml
|
mon可以9.51.8.102
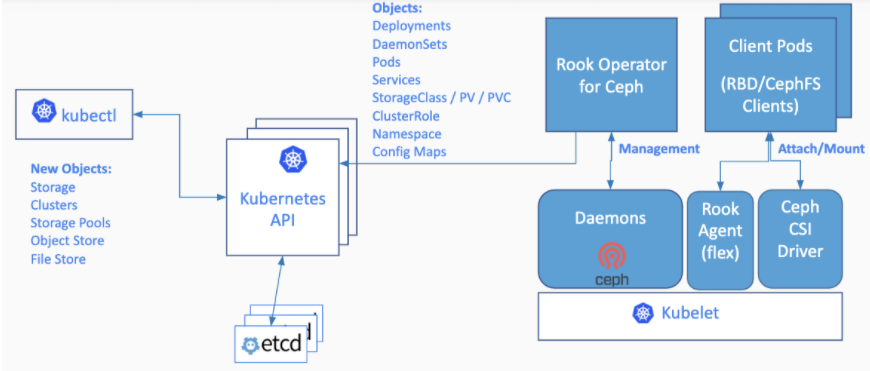
Rook 是一个存储相关的 Operator。
Rook turns distributed storage systems into self-managing, self-scaling, self-healing storage services. It automates the tasks of a storage administrator: deployment, bootstrapping, configuration, provisioning, scaling, upgrading, migration, disaster recovery, monitoring, and resource management.
Rook uses the power of the Kubernetes platform to deliver its services via a Kubernetes Operator for each storage provider.
Rook 中的 Ceph 已经进入 Stable V1 的版本了。
组件
- common.yaml 主要是部署 crd 对象
- operator.yaml 这个是真正干活的东西,用来控制 ceph 集群
- cluster.yaml 这个是部署安装集群的
1
2
3
4
|
# 可用的 docker 机器
9.51.8.102
9.25.138.240
9.4.160.132
|
打上 label。
1
2
3
4
5
6
7
8
9
10
|
kubectl label nodes 9.51.8.102 ceph-mon=enabled
kubectl label nodes 9.25.138.240 ceph-mon=enabled
kubectl label nodes 9.4.160.132 ceph-mon=enabled
kubectl label nodes 9.51.8.102 ceph-osd=enabled
kubectl label nodes 9.25.138.240 ceph-osd=enabled
kubectl label nodes 9.4.160.132 ceph-osd=enabled
kubectl label nodes 9.4.160.132 ceph-mgr=enabled
kubectl label nodes 10.50.146.222 ceph-osd=enabled
kubectl label nodes 10.50.146.223 ceph-osd=enabled
kubectl label nodes 9.25.138.240 ceph-mon=enabled
|
1
2
3
4
5
6
7
8
9
|
# kubectl get node --show-labels | grep -iv "windows" | grep -iv "Disabled" | grep -iv "NotReady" | grep -iv "v1.12" | awk '{print $1}'
NAME
10.50.146.222
10.50.146.223
10.50.86.213
9.140.129.41
9.23.151.180
9.25.138.240
9.51.8.102
|
取消 Label。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
kubectl label nodes 9.140.129.33 ceph-mon-
kubectl label nodes 9.140.129.33 ceph-mgr-
kubectl label nodes 9.140.129.33 ceph-osd-
kubectl label nodes 9.4.160.132 ceph-mon-
kubectl label nodes 9.4.160.132 ceph-mgr-
kubectl label nodes 9.4.160.132 ceph-osd-
kubectl label nodes 9.23.151.180 ceph-mon-
kubectl label nodes 9.23.151.180 ceph-mgr-
kubectl label nodes 9.23.151.180 ceph-osd-
kubectl label nodes 9.25.138.240 ceph-mon-
kubectl label nodes 9.25.138.240 ceph-mgr-
kubectl label nodes 9.25.138.240 ceph-osd-
kubectl label nodes 9.140.129.41 ceph-osd-
kubectl label nodes 9.140.129.41 ceph-mon-
kubectl label nodes 9.51.8.102 ceph-osd-
kubectl label nodes 9.51.8.102 ceph-mon-
kubectl label nodes 9.140.129.41 ceph-mgr-
|
disable掉其他机器,只留下来4台机器。
1
2
3
4
5
6
7
8
9
10
11
12
13
|
kubectl cordon 10.54.209.3
kubectl cordon 100.117.129.168
kubectl cordon 100.119.241.3
kubectl cordon 9.107.6.116
kubectl cordon 9.114.5.181
kubectl cordon 9.140.129.33
kubectl taint node 10.54.209.3
kubectl taint node 100.117.129.168
kubectl taint node 100.119.241.3
kubectl taint node 9.107.6.116
kubectl taint node 9.114.5.181
kubectl taint node 9.140.129.33
|
一些调度的标签。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
mon:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: ceph-mon
operator: In
values:
- enabled
osd:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: ceph-osd
operator: In
values:
- enabled
mgr:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: ceph-mgr
operator: In
values:
- enabled
|
部署成功案例
节点列表
打标签
10.50.146.222
10.50.146.223
10.50.86.213
运行ceph-mon的节点打上:ceph-mon=enabled
kubectl label nodes 10.50.146.222 ceph-mon=enabled
kubectl label nodes 10.50.146.223 ceph-mon=enabled
kubectl label nodes 10.50.86.213 ceph-mon=enabled
运行ceph-osd的节点,也就是存储节点,打上:ceph-osd=enabled
kubectl label nodes 10.50.146.222 ceph-osd=enabled
kubectl label nodes 10.50.146.223 ceph-osd=enabled
kubectl label nodes 10.50.86.213 ceph-osd=enabled
运行ceph-mgr的节点,打上:ceph-mgr=enabled,mgr只能支持一个节点运行,这是ceph跑k8s里的局限
kubectl label nodes 10.50.86.213 ceph-mgr=enabled
osd pod
1
2
3
4
5
6
7
8
9
|
# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 836.6G 0 disk
|-sda1 8:1 0 20G 0 part /
|-sda2 8:2 0 2G 0 part
|-sda3 8:3 0 20G 0 part /usr/local
`-sda4 8:4 0 794.6G 0 part /data
fioa 248:0 0 1.1T 0 disk
`-ceph--c76fcff4--d87c--455a--8e5f--3b531fa65e83-osd--data--14497056--f586--4723--9e2c--38f5ff3e0e53 249:0 0 1.1T 0 lvm
|
错误总结
because it contains a filesystem “xfs”
安装 lvm2,yum install -y lvm2。
碰到 namespace 一直在 Terminating
https://juejin.im/post/5dada0bc5188253b2f003eff
kubectl get ns rook-ceph -o json > rook-ceph.json
curl -k -H “Content-Type:application/json” -X PUT –data-binary @rook-ceph.json http://localhost:8080/api/v1/namespaces/rook-ceph/finalize
需要通过 HTTP 的方式,可以强制删除。
no valid nodes available to run osds on nodes in namespace rook-ceph
在部署 host-based 的集群的时候,由于 node 只有一块磁盘,所以没有合适的设备作为 osd 的磁盘。
博客的命令
https://blog.csdn.net/chenleiking/article/details/88844164
kubectl get nodes -o wide
cluster-test
本地资源有限。所以部署一个 cluster-test.yaml 来看一下。
创建对象存储服务
感觉 Rook 配置很多,而且有很多是代码里直接运行的 yaml 文件,所以不容易看熟练。
s3cmd ls之迷惑
习惯了文件系统的我们一直都觉得 ls 命令应该会把文件全部 list 出来,对于 s3cmd ls 我一开始也是这么理解的。
直到有一天,同事通过 s3cmd delete 删除了一个文件,执行 s3cmd ls 竟然返回200,但是 s3cmd get 却返回404,这就很奇怪了,用户明明已经删了对象,为何 ls 得到呢,这不合理,当然 get 不到,那才是合理的,那么 get 不应该 ls 得到啊。
具体的情况如下。
1
2
3
4
5
|
# s3cmd ls s3://game/1586744327001/sample/allblueapp/80121/ap_80121_14_20200515115522_216.txt
2020-05-15 03:58 1606 s3://game/1586744327001/sample/allblueapp/80121/ap_80121_14_20200515115522_216.txt
# s3cmd get s3://game/1586744327001/sample/allblueapp/80121/ap_80121_14_20200515115522_216.txt .
download: 's3://game/1586744327001/sample/allblueapp/80121/ap_80121_14_20200515115522_216.txt' -> './ap_80121_14_20200515115522_216.txt' [1 of 1]
ERROR: S3 error: 404 (NoSuchKey)
|
于是加一下加一下 -d 选项来 debug 一下。发现依然是返回200,且也看不出有什么问题。于是去看了下 s3cmd 的源码,发现 s3cmd ls 只要 bucket 存在,就一定会返回200,不管要 ls 的 object 存不存在,于是做了个实验,去 ls 一个从来不存在的 object 发现,竟然也是200,OK,Fine。
感兴趣的话,可以去看下这块代码,确认一下。
https://github.com/s3tools/s3cmd/blob/master/S3/S3.py#L324
参考资料
- Kubernetes部署云原生分布式存储Rook
- NGINX Performance Metrics with Prometheus
警告
本文最后更新于 2017年2月1日,文中内容可能已过时,请谨慎参考。