概述
搭建一个测试的 Kubernetes 集群,将节点的 Mellanox 网卡通过虚拟化的方式创建出 PF/VF,通过 k8s-rdma-shared-dev-plugin 插件提供给 Kubernetes 集群作为资源管理,集群可以通过 http://10.199.100.32:8900/ 在办公网内访问(测试集群下线了的话就无效了)。

节点准备
一般来说,要想让容器使用 SR-IOV 网卡,需要以下步骤:
- 在主机上安装相应的SR-IOV驱动,使其能够识别物理网卡上的虚拟网卡
- 在主机上创建SR-IOV VF(Virtual Function),并将其绑定到容器所在的网络命名空间中。这里可以使用CNI插件来创建VF
- 在容器中配置网络,使用SR-IOV VF作为容器的网络接口
| 节点 |
角色 |
内核 |
| 10.199.100.32 |
control-plane |
4.18.0-240.el8.x86_64 |
| 10.199.100.34 |
worker |
4.18.0-193.14.2.el8_2.x86_64 |
| 10.199.100.35 |
worker |
4.18.0-240.el8.x86_64 |
下面是安装 OFED 驱动的过程。操作目录在节点的 /root/runzhliu/MLNX_OFED_LINUX-4.9-5.1.0.0-rhel8.0-x86_64,这个过程后面可以封装到一个节点的初始化脚本里执行,测试过程中,主要目的是测试跨节点的容器的 RDMA 的测试工具 ib_write_bw,所以每个 worker 都需要安装,实际 controlplane 也安装了。
1
2
3
4
5
|
# 安装驱动需要的依赖软件
yum install -y tk gcc-gfortran tcsh
yum install -y rpm-build kernel-rpm-macros
# 正式编译和安装驱动
./mlnxofedinstall --skip-distro-check --add-kernel-support --skip-repo
|
创建 VF 的方法可以参考之前的文档 RDMA-基础调试。
创建集群
因为按照公司内部集群的安装方式会有一些行为和组件与社区有一些差别,比如使用 Multus 多网卡的组件的时候需要通过 KUBERNETES_HOST 这个 Service IP 以 in-cluster 的方式访问 kube-apiserver,会对实验过程产生一些不可预知的问题,为了减少干扰,所以通过社区的其他方式来创建 Kubernetes 集群,具体可以参考文档 DoK Docs,当然也可以用其他方式来创建集群。
1
2
|
# 配置了10.199.100.32对其他节点的免密
chmod +x dok && cp dok /usr/bin && dok createCluster -m 10.199.100.32 -w 10.199.100.34,10.199.100.35 -p /root/dok-release-without-app-image.gz --noCheck
|
下面是创建的集群的信息,部署的 Kubernetes 版本是 v1.24.8,且移除了 Docker 的依赖。
1
2
3
4
5
|
# k get node -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
gd15-rdma-test-005 Ready control-plane 105m v1.24.8 10.199.100.32 CentOS Linux 8 4.18.0-240.el8.x86_64 containerd://1.5.5
gd15-rdma-test-007 Ready <none> 99m v1.24.8 10.199.100.34 CentOS Linux 8 4.18.0-193.14.2.el8_2.x86_64 containerd://1.5.5
gd15-rdma-test-008 Ready <none> 71m v1.24.8 10.199.100.35 CentOS Linux 8 4.18.0-240.el8.x86_64 containerd://1.5.5
|
k8s-rdma-shared-dev-plugin
RDMA 设备需要通过 k8s-rdma-shared-dev-plugin 来管理,为了快速验证和测试,部分参数可能有些问题,但是不会影响最终的测试结果。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
|
apiVersion: v1
kind: ConfigMap
metadata:
name: rdma-devices
namespace: kube-system
data:
config.json: |
{
"periodicUpdateInterval": 300,
"configList": [
{
"resourceName": "hca_shared_devices_a",
"rdmaHcaMax": 4,
"devices": ["ens6f0v0", "ens6f0v1", "ens6f0v2", "ens6f0v3", "eth0.1000", "ens5f0v0", "ens5f0v1", "ens5f0v2", "ens5f0v3"]
},
{
"resourceName": "hca_shared_devices_b",
"rdmaHcaMax": 1,
"selectors": {
"ifNames": ["bond0", "eth0"]
}
}
]
}
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: rdma-shared-dp-ds
namespace: kube-system
spec:
selector:
matchLabels:
name: rdma-shared-dp-ds
template:
metadata:
labels:
name: rdma-shared-dp-ds
spec:
hostNetwork: true
priorityClassName: system-node-critical
tolerations:
- effect: NoSchedule
operator: Exists
containers:
- image: docker.xxx.com/public/k8s-rdma-shared-dev-plugin:latest
name: k8s-rdma-shared-dp-ds
imagePullPolicy: IfNotPresent
securityContext:
privileged: true
volumeMounts:
- name: device-plugin
mountPath: /var/lib/kubelet/
- name: config
mountPath: /k8s-rdma-shared-dev-plugin
- name: devs
mountPath: /dev/
volumes:
- name: device-plugin
hostPath:
path: /var/lib/kubelet/
- name: config
configMap:
name: rdma-devices
items:
- key: config.json
path: config.json
- name: devs
hostPath:
path: /dev/
|
部署的结果如下。
1
2
3
4
5
|
# k get pods
NAME READY STATUS RESTARTS AGE IP NODE
rdma-shared-dp-ds-64972 1/1 Running 0 5h33m 10.199.100.34 gd15-rdma-test-007
rdma-shared-dp-ds-96fc5 1/1 Running 0 5h33m 10.199.100.32 gd15-rdma-test-005
rdma-shared-dp-ds-v7ph2 1/1 Running 0 5h33m 10.244.3.1 gd15-rdma-test-008
|
通过日志可以看到设备能够正常被 k8s-rdma-shared-dev-plugin 发现。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
2023/03/02 10:06:18 discovering host network devices
2023/03/02 10:06:18 DiscoverHostDevices(): device found: 0000:06:00.0 02 Mellanox Technolo... MT27710 Family [ConnectX-4 Lx]
2023/03/02 10:06:18 DiscoverHostDevices(): device found: 0000:06:00.1 02 Mellanox Technolo... MT27710 Family [ConnectX-4 Lx]
2023/03/02 10:06:18 DiscoverHostDevices(): device found: 0000:06:00.2 02 Mellanox Technolo... MT27710 Family [ConnectX-4 Lx Virtual...
2023/03/02 10:06:18 DiscoverHostDevices(): device found: 0000:06:00.3 02 Mellanox Technolo... MT27710 Family [ConnectX-4 Lx Virtual...
2023/03/02 10:06:18 DiscoverHostDevices(): device found: 0000:06:00.4 02 Mellanox Technolo... MT27710 Family [ConnectX-4 Lx Virtual...
2023/03/02 10:06:18 DiscoverHostDevices(): device found: 0000:06:00.5 02 Mellanox Technolo... MT27710 Family [ConnectX-4 Lx Virtual...
2023/03/02 10:06:18 DiscoverHostDevices(): device found: 0000:31:00.0 02 Intel Corporation Ethernet Connection X722 for 10GbE SFP+
2023/03/02 10:06:18 DiscoverHostDevices(): device found: 0000:31:00.1 02 Intel Corporation Ethernet Connection X722 for 10GbE SFP+
# 这里说明发现了RDMA设备
2023/03/02 10:06:18 no changes to devices for "rdma/hca_shared_devices_a"
2023/03/02 10:06:18 exposing "4" devices
# 这里说明发现了RDMA设备
2023/03/02 10:06:18 no changes to devices for "rdma/hca_shared_devices_b"
2023/03/02 10:06:18 exposing "1" devices
|
查看节点的资源,已经有对应的资源关联上了,下面是 Device Plugin 上报的资源。
1
2
3
4
5
6
7
8
9
10
11
12
|
Addresses:
InternalIP: 10.244.3.1
Hostname: gd15-rdma-test-008
Capacity:
cpu: 48
ephemeral-storage: 927152828Ki
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 263394612Ki
pods: 110
rdma/hca_shared_devices_a: 4
rdma/hca_shared_devices_b: 1
|
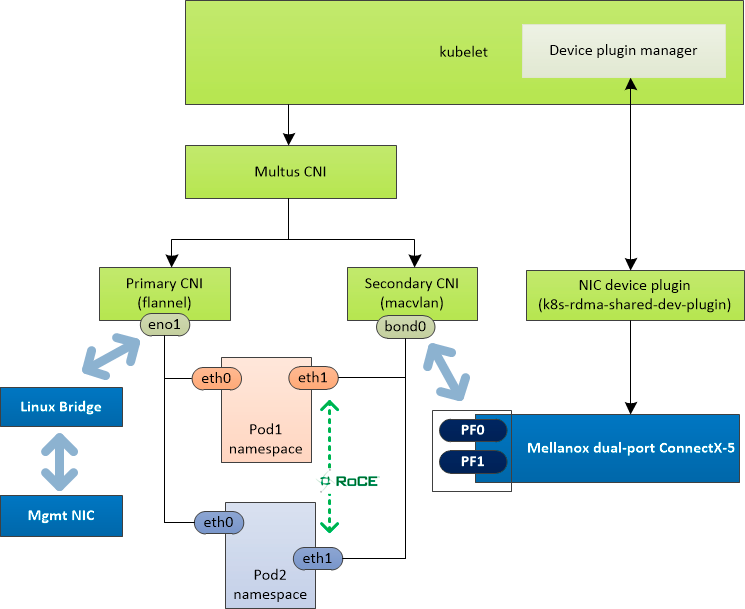
Multus
部署 Multus 是为了给 Pod 设置第二个网络平面,按照默认的部署方式,集群内网络是以 Flannel 为基础网络的,如果希望 Pod 可以有另外的数据网络,可以通过 Multus 来给容器创建第二个网络接口,下面的例子中,是通过 SRIOV 插件,并且分配一个 10.199.100.0/24 子网内的一个可用的 IP 来实现通信的。
Multus 的部署文件比较长,不在本文列出了,按照官方文档的指示,只需要修改一下镜像名为公司镜像仓库的地址即可。
1
2
3
4
5
|
k get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE
kube-multus-ds-4d6lx 1/1 Running 0 6h40m 10.244.3.1 gd15-rdma-test-008
kube-multus-ds-6l8ft 1/1 Running 0 53m 10.244.2.1 gd15-rdma-test-007
kube-multus-ds-gg226 1/1 Running 1 (6h11m ago) 6h40m 10.199.100.32 gd15-rdma-test-005
|
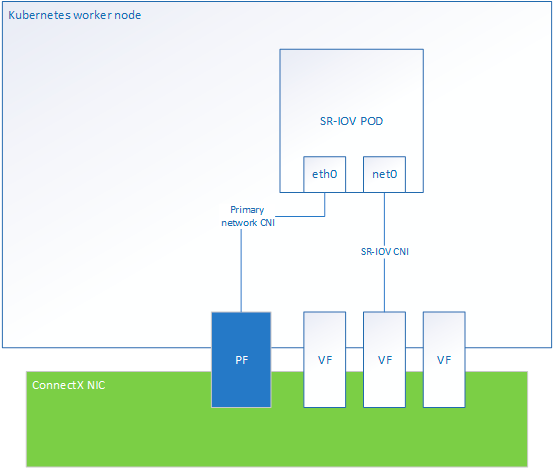
下面是在工作节点上,看到的物理网卡、虚拟网卡,以及 Pod 的网络接口的示意图,从这个图可以看到,默认的 eth0 网卡实际上是会桥接到 PF,然后 SRIOV 创建的网络接口会桥接到 VF。
创建测试Pod
通过指定的 Macvlan 子网的 IP,Pod 的 nodeSelector,分别将在三个节点上都部署一个 Pod,IP 分别是 10.199.100.247/10.199.100.250/10.199.100.251,下面是其中一个 Pod 的配置方法。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
|
---
apiVersion: "k8s.cni.cncf.io/v1"
kind: NetworkAttachmentDefinition
metadata:
name: macvlan-cx5-bond-conf-2
spec:
config: '{
"cniVersion": "0.3.1",
"type": "macvlan",
"master": "bond0.1000",
"ipam": {
"type": "host-local",
"subnet": "10.199.100.0/24",
"rangeStart": "10.199.100.251",
"rangeEnd": "10.199.100.251",
"routes": [
{ "dst": "0.0.0.0/0" }
],
"gateway": "10.199.100.1"
}
}'
---
apiVersion: v1
kind: Pod
metadata:
name: mofed-test-pod-1
annotations:
k8s.v1.cni.cncf.io/networks: default/macvlan-cx5-bond-conf-2
spec:
restartPolicy: OnFailure
nodeSelector:
kubernetes.io/hostname: "gd15-rdma-test-007"
containers:
- image: docker.xxx.com/public/mofed421_docker:latest
name: mofed-test-ctr
securityContext:
capabilities:
add: [ "IPC_LOCK" ]
resources:
limits:
rdma/hca_shared_devices_a: 1
command:
- sh
- -c
- |
ls -l /dev/infiniband /sys/class/infiniband /sys/class/net
sleep 1000000
|
三个 Pod 的部署和分布情况如下。
1
2
3
4
5
|
# k get po -o wide
NAME READY STATUS RESTARTS AGE IP NODE
mofed-test-pod-1 1/1 Running 0 61m 10.244.2.118 gd15-rdma-test-007
mofed-test-pod-2 1/1 Running 0 6h55m 10.244.3.52 gd15-rdma-test-008
mofed-test-pod-3 1/1 Running 0 5h15m 10.244.0.4 gd15-rdma-test-005
|
验证ib_write_bw
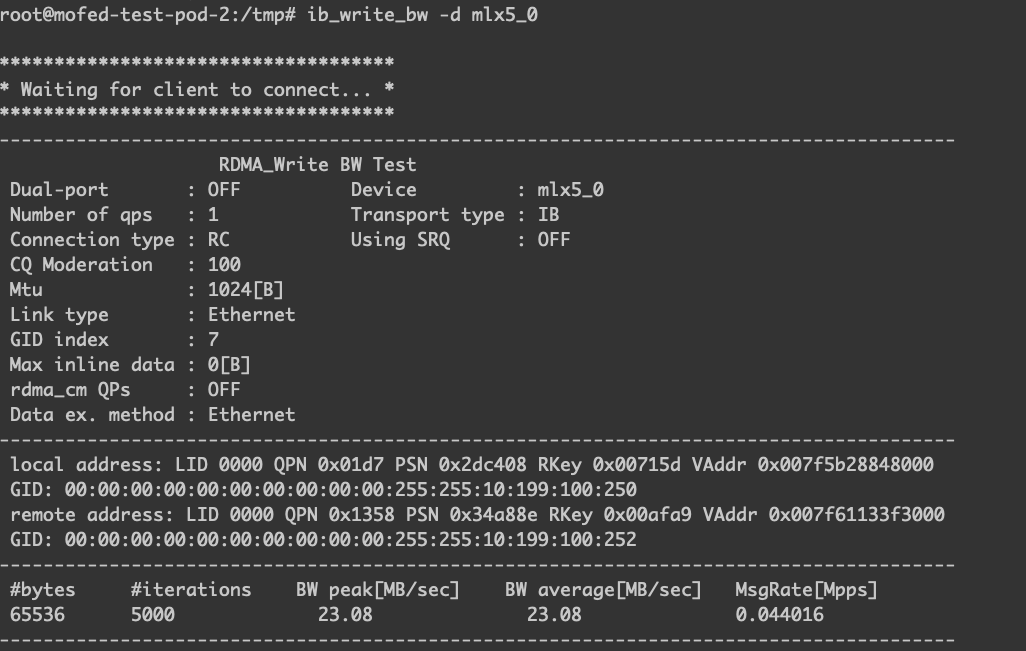
名为 mofed-test-pod-2 IP 为 10.199.100.250 的 Pod 是运行在节点 10.199.100.35 中的,作为测试过程中的服务端,如下图。
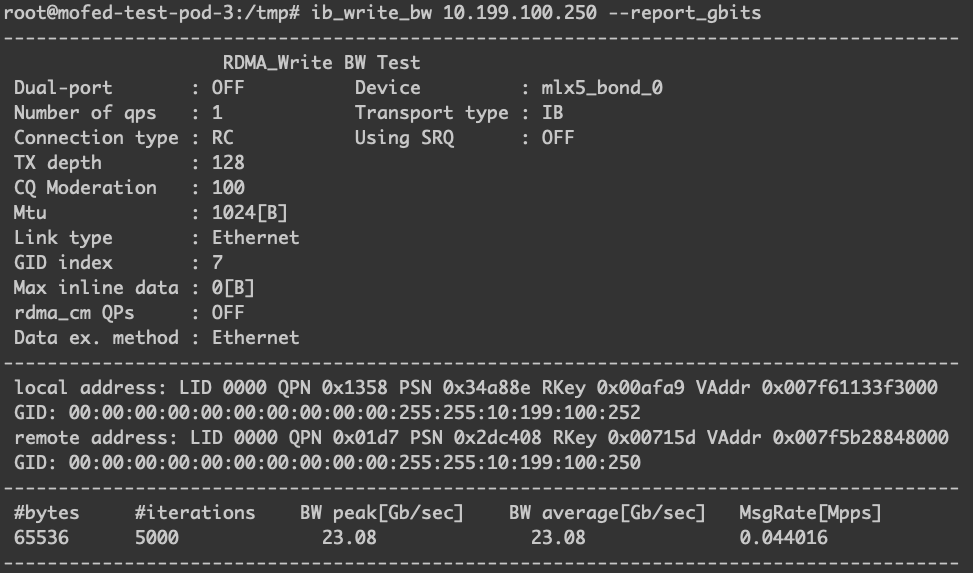
名为 mofed-test-pod-3 IP 为 10.199.100.252 的 Pod 是运行在 10.199.100.32 中的,作为测试过程中的客户端,如下图。
从结果看,两边的 RDMA 设备都是可以正常通信的。
IP管理
测试集群的 IP 都是通过 IPAM 人工指定的,这在一定规模的集群的时候肯定无法支持,关于 IP 的分配方式还需要看采用的 CNI 插件,小规模集群应用的时候可以通过 whereabouts 来做统一的 IP 分配,当然这里还需要跟网络组和运维组的同事沟通。
总结
测试过程中,遇到不少问题,首先是集群的方式,将原来的 RDMA 设备加到 QA 集群的时候,netplugin 的一些特殊配置,比如缺少 Service,会导致一些开源的组件在部署的时候会遇到一些问题。另外就是节点 10.199.100.0/24 上部署的普通容器,即使拿到 netmaster 分配的 IP 也无法直接通信,这里可能是上层路由和一些网络策略导致的,所以后面才会考虑直接从 10.199.100.0/24 拿出三个节点来单独部署集群。另外就是上面的 ib_write_bw 验证过车中,偶尔会报下面的问题,这个问题很好复现,但是还没有具体找到原因,等后面再花时间研究。
1
2
3
4
|
Completion with error at client
Failed status 12: wr_id 0 syndrom 0x81
scnt=128, ccnt=0
Failed to complete run_iter_bw function successfully
|
参考资料
- HPC-RDMA网络性能测试
- RDMA网络简介
- RDMA统计
- NVIDIA MLNX_OFED Documentation Rev 5.3-1.0.0.1驱动说明
警告
本文最后更新于 2023年4月9日,文中内容可能已过时,请谨慎参考。