Rancher监控告警体系
概述
以 Rancher 2.4 为例,告警体系主要分为两个 Scope。
- Cluster Level
- Project Level
基于这两个 Scope,在 Rancher UI 上的配置是略有不同的,也正如 Scope 的名称,Cluster Level 的是用于整个集群的告警的配置,主要针对节点的物理资源或者是 ETCD 这样的公共组件,而 Project Level 自然就是项目维度的了,比如统一给项目匹配一些服务可用性之类的指标,就可以统一配置了。
配置了告警,当然就是需要通过某种机制把告警通知出来了,在 Rancher 这个概念叫做 notifier。notifier 的配置目前只能是 Cluster Level 的,即使是 Project Owner 也只能调整告警的规则,而不能直接修改 notifier 的通知配置。
https://rancher.com/docs/rancher/v2.0-v2.4/en/cluster-admin/tools/cluster-monitoring/
全局监控
全局监控是全局告警的基础,在 Rancher 2.4 的版本中,是有全局监控支持的,全局监控的实现是基于 Thanos。
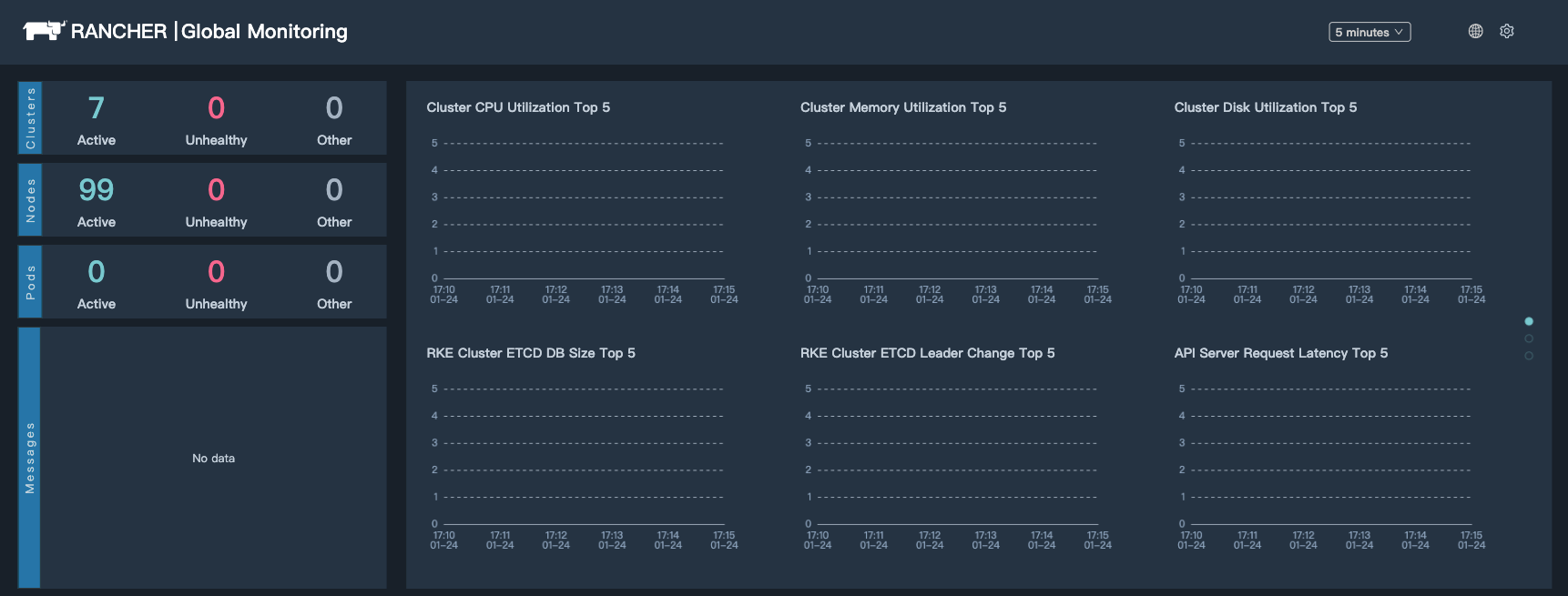
尽管有全局监控,但是 Rancher 并没有提供全局告警的配置给用户进行配置,这里可以理解,是因为每个集群的告警,其实都是 Rancher 通过给每个集群单独去配置告警组来实现的,如下图:
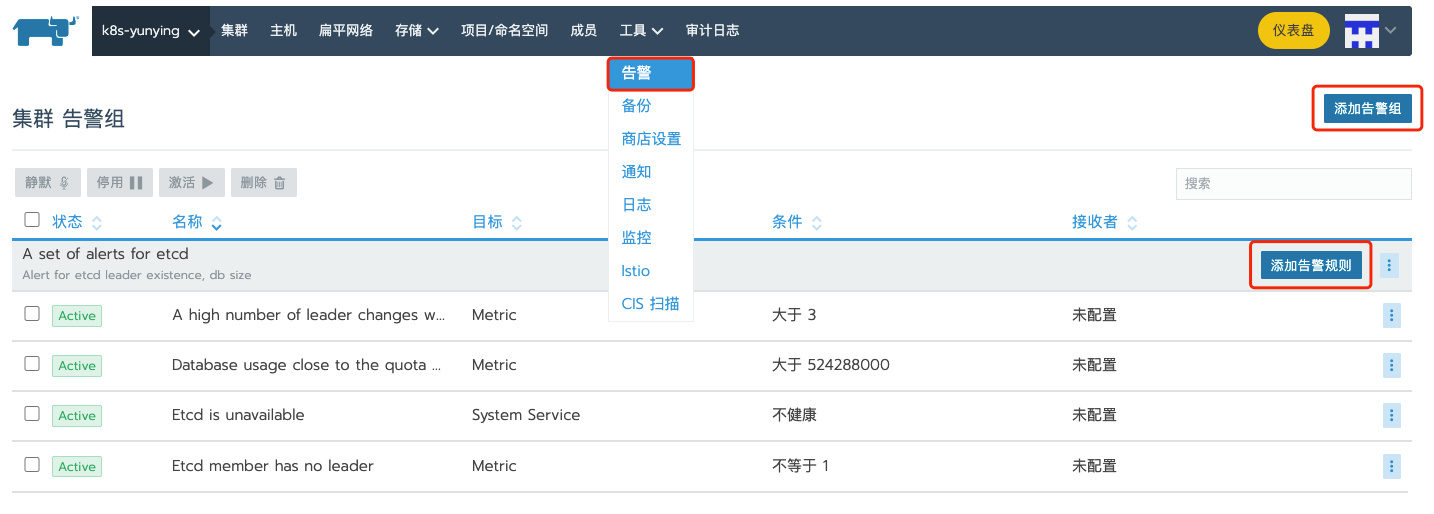
关于2.4
团队最近在使用 2.6 发现 Rancher 已经没有全局和项目监控的概念了,基本上完全转向了 Prometheus Operator 的骚操作了。如果是基于 2.6 版本来开发一个全局告警平台,大概的思路就是去管理所有集群(全局)的 PrometheusRule,这样可以让各个集群自己的 AlertManager 决定是否发出告警。UI 可以参考 2.4 版本的。
代码部分
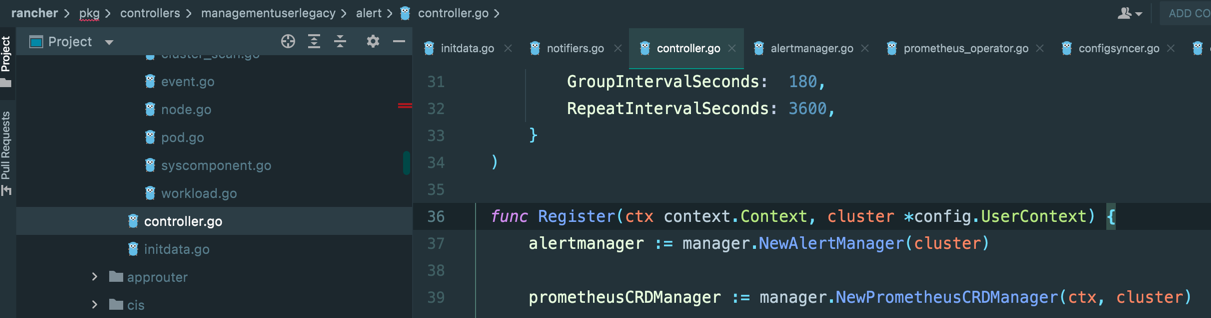
整个模块的入口在下图的地方。通过 Register 函数,把告警规则和配置的 Controller 注册到主程序。
最关键的方法入口是这个 sync()。看注解也知道,这个方法是负责同步关于 AM 和 rules 的方法。

sync: update the secret which store the configuration of alertmanager given the latest configured notifiers and alerts rules. For each alert, it will generate a route and a receiver in the alertmanager’s configuration file, for metric rules it will update operator crd also.