PyTorch相关
概述
PyTorch的发展历史
- 1.0版本(2018年1月): PyTorch第一个稳定版本的发布,具有自动微分、动态图、支持numpy的张量运算等功能。
- 1.1版本(2019年5月): PyTorch的第一个维护版本,包括增强的ONNX导出、CUDA10.0支持、DistributedDataParallel API的改进等功能。
- 1.2版本(2019年7月): 增加对C++前端的支持、对TensorBoard的支持、对TensorFlow的Eager模式的支持等。
- 1.3版本(2019年10月): 增加动态图的新功能(包括torch.jit.script和torch.jit.trace)以及对CUDA10.1和cuDNN7.5的支持。
- 1.4版本(2020年1月): 引入了TorchScript,支持以一种静态图形式运行PyTorch程序,包括TensorFlow的Eager模式、TensorFlow 2.0和ONNX1. 运行时。此外,还增加了混合精度训练和自适应优化器等新功能。
- 1.5版本(2020年5月): 增加了C++ API的新功能、自动混合精度优化、可调试的分布式调试等。
- 1.6版本(2020年8月): 增加了自动量化功能、支持TensorBoard的新功能、XLA支持等。
- 1.7版本(2020年10月): 增加了针对Windows的Native AMP API支持、针对CUDA11的Tensor Core加速、对FAIRSeq、HuggingFace 1. Transformers和Kaldi等库的集成支持等。
- 1.8版本(2021年3月): 增加了对新硬件的支持、对自适应梯度剪枝的改进、对深度嵌套网络的支持等。
- 1.9版本(2021年6月): 增加了对NVIDIA A100、对Intel CPU的支持、对TorchScript的改进等。
- 1.10版本(2021年10月): 增加了针对CUDA 11.3的原生AMP API、新的优化器等功能。
AI平台现状
训练
AI 平台会提供 Pytorch 的离线训练的类型,但是是用 MPI Operator 的方式来运行,而实际的用户也主要用于跑数,而不是在做真正的训练等等。
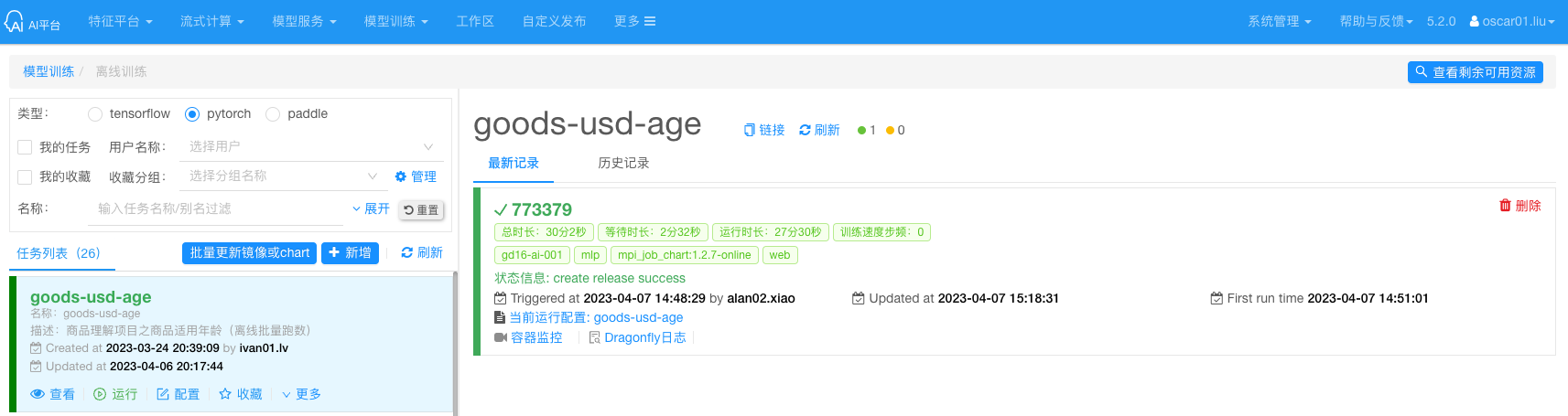
服务
AI 平台的 Serving 的部分也有提供 Pytorch 模型的服务。
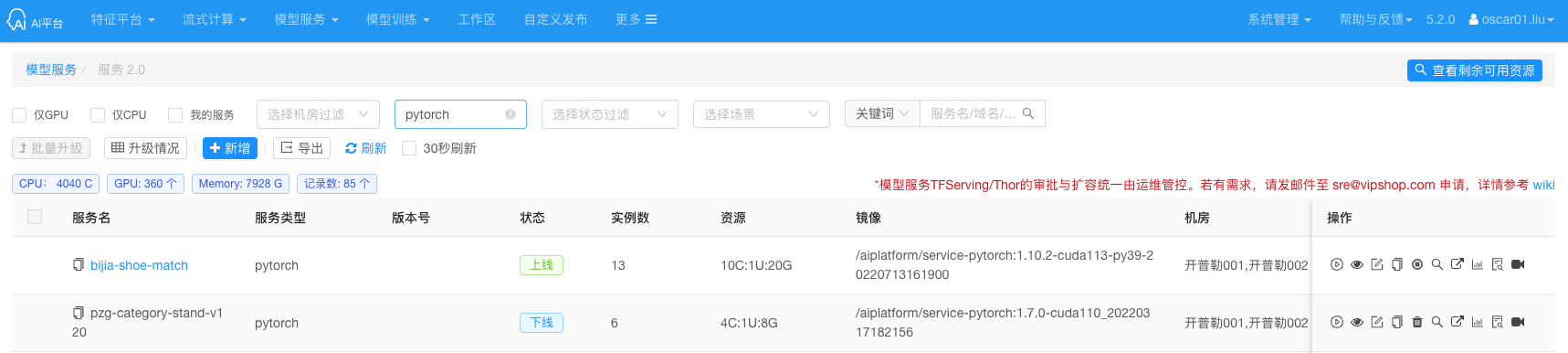
分析一下脚本可镜像,应该是用 Flask 来提供服务的。

模型管理
模型管理的部分偏弱,基本是没有的。
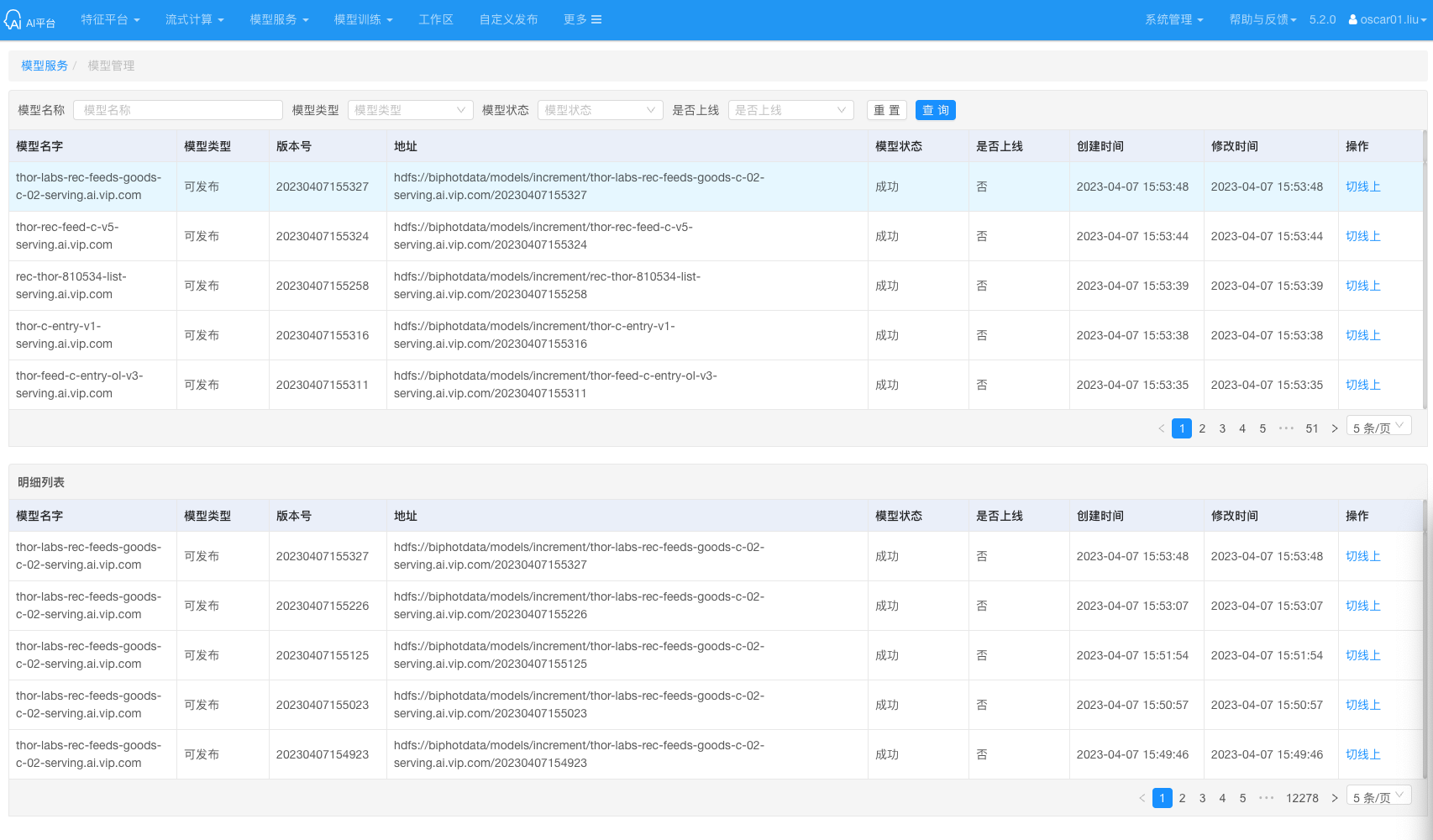
缺少DAG
用户是需要跑数的,没有 DAG 很难安排计算任务。
Troubleshooting
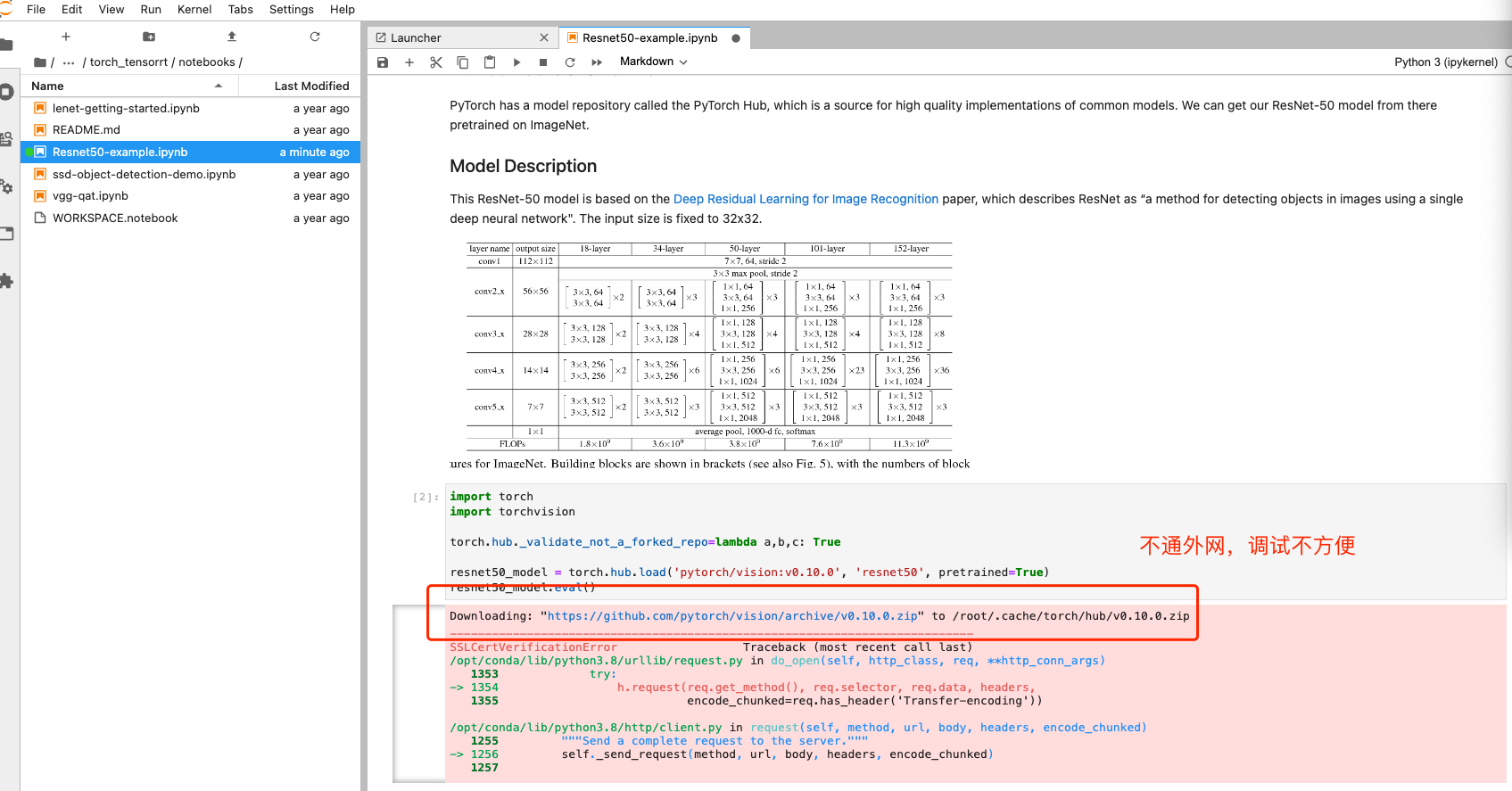
RuntimeError: CUDA error: no kernel image is available for execution on the device (2020-12-16)
提示报错: Tesla K40m with CUDA capability sm_35 is not compatible with the current PyTorch installation. The current PyTorch install supports CUDA capabilities sm_37 sm_50 sm_60 sm_61 sm_70 sm_75 compute_37.
原因是 pytorch 的版本和显卡的计算能力不匹配。组里服务器上的显卡太旧了,还是 Tesla K40m,虽然 CUDA Version: 10.2,如果按照 pytorch 官网的指令:
|
|
安装的是 pytorch 的1.7.1的版本,但是 从pytorch 1.3.0以后,就不支持 Tesla K40m 了,这是硬件层面的不支持,没什么特别好的方法
解决方法: 在Tesla K40m上,安装pytorch 1.2.0的版本就行了。
|
|
所以家里的 GPU 就不够用了,后面更换一下 GPU 换成 M40 测试一下。
GPU M40实测
分布式后端
Gloo后端
到目前为止,Gloo 后端 已经得到了广泛使用。它作为开发平台非常方便,因为它包含在预编译的 PyTorch 二进制文件中,并且适用于 Linux(自 0.2 起)和 macOS(自 1.3 起)。它支持 CPU 上的所有点对点和集合操作,以及 GPU 上的所有集合操作。但是其针对 CUDA 张量集合运算的实现不如 NCCL 后端所优化的那么好。
您肯定已经注意到,如果您的模型使用 GPU ,我们的分布式 SGD 示例将不起作用。为了使用多个GPU,我们也做如下修改:
|
|
通过上述修改,我们的模型现在可以在两个 GPU 上进行训练,您可以使用 watch nvidia-smi 来监控使用情况。
MPI后端
消息传递接口 (MPI) 是来自高性能计算领域的标准化工具。它允许进行点对点和集体通信,并且是 torch.distributed 的主要灵感来源。目前存在多种 MPI 实现(例如 Open-MPI、 MVAPICH2、Intel MPI),每一种都针对不同目的进行了优化。使用 MPI 后端的优势在于 MPI 在大型计算机集群上的广泛可用性和高度优化。最近的一些实现还能够利用 CUDA IPC 和 GPU Direct 技术,这样可以避免通过 CPU 进行内存复制。
不幸的是,PyTorch 的二进制文件不能包含 MPI 实现,我们必须手动重新编译它。幸运的是,这个过程相当简单,因为在编译时,PyTorch 会自行 寻找可用的 MPI 实现。以下步骤通过从源码安装 PyTorch来安装 MPI 后端。
创建并激活您的 Anaconda 环境,依据 the guide 安装所有继先决需求,但不运行python setup.py install。
选择并安装您最喜欢的 MPI 实现。请注意,启用 CUDA-aware MPI 可能需要一些额外的步骤。在我们的例子中,我们将使用没有GPU 支持的Open-MPI : conda install -c conda-forge openmpi。
现在,转到您克隆的 PyTorch 存储库并执行 .python setup.py install。为了测试我们新安装的后端,需要进行一些修改。
把if name == ‘main’: 替换为init_process(0, 0, run, backend=‘mpi’)
运行 mpirun -n 4 python myscript.py
这些更改的原因是 MPI 需要在生成进程之前创建自己的环境。MPI 还将产生自己的进程并执行初始化方法中描述的握手操作,从而使init_process_group的rank和size 参数变得多余。这实际上非常强大,因为您可以传递额外的参数来mpirun为每个进程定制计算资源(例如每个进程的核心数、将机器手动分配到特定rank等等)。这样做,您应该获得与其他通信后端相同的熟悉输出。
NCCL后端
该 NCCL 后端提供了一个优化的,针对对 CUDA 张量实现的集合操作。如果您仅将 CUDA 张量用于集合操作,请考虑使用此后端以获得最佳性能。NCCL 后端包含在具有 CUDA 支持的预构建二进制文件中。
NCCL 的全称为 Nvidia 聚合通信库(NVIDIA Collective Communications Library),是一个可以实现多个 GPU、多个结点间聚合通信的库,在 PCIe、Nvlink、InfiniBand 上可以实现较高的通信速度。
NCCL 高度优化和兼容了 MPI,并且可以感知 GPU 的拓扑,促进多 GPU 多节点的加速,最大化 GPU 内的带宽利用率,所以深度学习框架的研究员可以利用 NCCL 的这个优势,在多个结点内或者跨界点间可以充分利用所有可利用的 GPU。NCCL 对 CPU 和 GPU 均有较好支持,且 torch.distributed 对其也提供了原生支持。
对于每台主机均使用多进程的情况,使用 NCCL 可以获得最大化的性能。每个进程内,不许对其使用的 GPUs 具有独占权。若进程之间共享 GPUs 资源,则可能导致 deadlocks。
验证GPU上运行Pytorch
这是一段在 GPU 上进行 numpy 操作的代码。
|
|
Conda环境
腾讯云GPU环境
|
|
Minio前端
|
|
用Flask部署模型
目前算法同学主要是通过 Flask 来部署模型,该方式虽然性能一般,但是比较容易理解和简单的方法,也就是服务和推理是分开两个过程的,Flask 负责接受 http 请求,然后转发到 Python 的推理后端。
用TorchServe部署模型
PyTorch模型转TorchScript
转 TS 是为了使用 C++,推理可以上 Trition。
PyTorch模型通过Torch-TRT转TensorRT
pytorch转tensorRT步骤:
使用pytorch训练得到pt文件; 将pt文件转换为onnx中间件; 使用onnxsim.simplify对转换后的onnx进行简化; 解析onnx文件构建trt推理引擎; 加载引擎执行推理,为引擎输入、输出、模型分配空间; 将待推理的数据(预处理后的img数据)赋值给inputs(引擎输入); 执行推理,拿到outputs; 对outputs后处理,根据构建引擎时的格式取出输出,reshape到指定格式(和torch推理后的格式一样); 然后知道该怎么做了吧。
部署整体流程:
导出网络定义以及相关权重; 解析网络定义以及相关权重; 根据显卡算子构造出最优执行计划; 将执行计划序列化存储; 反序列化执行计划; 进行推理
pytorch 模型转化为 TensorRT 有两种路径
- 把pytorch的pt模型转化为onnx,然后再转化为TensorRT
- 把pytorch的pt模型转成TensorRT
分布式PyTorch会用Horovod吗
事实上,Horovod 不仅支持 PyTorch,还支持 TensorFlow、Mxnet 等多种框架。相较原生的分布式训练方式,在 TensorFlow 里 Horovod 分布式训练的应用更广泛,而在 PyTorch 里面,由于应用性方面的考虑及代码侵入等问题的存在,大多数用户还是更倾向选择原生的 DDP 方式。
Triton
|
|
参考资料
- Pytorch随笔记
- 宿主机分区和标签组管理 - 内含GPU标签
- VIP - PyTorch-需求收集
- 云原生的弹性AI训练系列之二: PyTorch 1.9.0弹性分布式训练的设计与实现 - 对分布式训练讲的比较清晰
- PyTorch Serving - Kubeflow里面使用PTS
- PyTorch单机训练 - 阿里云的官方文档
- PyTorch指定单GPU和多GPU训练及保存-加载模型(含CPU)的总结 - 有完整代码参考
- 通过带Flask的REST API在Python中部署PyTorch
- Use TorchServe and Flask to Deploy your Model as a Web App - 主要是讲如何用Flask来提供服务的
- PyTorch分布式训练原来可以更高效 - 提到几种分布式的训练方式以及模型服务的方案
- PyTorch Distributed with MPI - 看起来是非常简单的测试程序
- PyTorch分布式(1)——历史和概述 - 深度好文建议反复阅读
- 使用TensorRT部署Pytorch模型 - 有代码示例进行转换
- PYTORCH TO ONNX