概述
弹性计算提供 PySpark 类型的计算任务,用户提交 Python 的业务代码即可使用 PySpark 计算。
Python版本问题
因为 Python2 在2020年会停止更新,所以建议大家选用 Python3。但是我们默认提供的镜像是按照社区提供的 Dockerfile 来构建的,所以依然是 Python2。
用户自定义镜像
很多情况下,默认镜像不能满足用户的需求,此时用户可以使用平台提供的镜像重新构建,参考下面这个例子。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
ARG base_img
FROM $base_img
WORKDIR /
# Reset to root to run installation tasks
USER 0
RUN mkdir ${SPARK_HOME}/python
# TODO: Investigate running both pip and pip3 via virtualenvs
RUN apt install -y python python-pip && \
apt install -y python3 python3-pip && \
# We remove ensurepip since it adds no functionality since pip is
# installed on the image and it just takes up 1.6MB on the image
rm -r /usr/lib/python*/ensurepip && \
pip install --upgrade pip setuptools && \
# You may install with python3 packages by using pip3.6
# Removed the .cache to save space
rm -r /root/.cache && rm -rf /var/cache/apt/*
COPY python/pyspark ${SPARK_HOME}/python/pyspark
COPY python/lib ${SPARK_HOME}/python/lib
WORKDIR /opt/spark/work-dir
ENTRYPOINT [ "/opt/entrypoint.sh" ]
# Specify the User that the actual main process will run as
ARG spark_uid=185
USER ${spark_uid}
|
基础镜像默认安装了 python2/python3,所以如果需要使用 Python3 的话需要去配置几个环境变量。如果不指定,会默认使用 Python2。
1
2
3
4
5
6
|
# 2.7.13 是镜像里 Python 的版本
ENV PYTHON_VERSION 2.7.13
# python 是启动命令,如果镜像安装了 python3,可以使用 python3
ENV PYSPARK_PYTHON python
# python 是启动命令,如果镜像安装了 python3,可以使用 python3
ENV PYSPARK_DRIVER_PYTHON python
|
docker build 完之后,可以通过下面的例子,验证一下,留意输出的 Python Version 的信息。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
# docker run -it hub.oa.com/gameai/pyspark-2-2-executor:latest /opt/spark/bin/pyspark
++ id -u
+ myuid=0
...
...
+ /sbin/tini -s -- /opt/spark/bin/pyspark
Python 2.7.16 (default, May 6 2019, 19:35:26)
[GCC 8.3.0] on linux2
Type "help", "copyright", "credits" or "license" for more information.
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
2019-10-16 09:01:13 WARN NativeCodeLoader:62 - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 2.2.0-k8s-0.5.0
/_/
Using Python version 2.7.16 (default, May 6 2019 19:35:26)
SparkSession available as 'spark'.
|
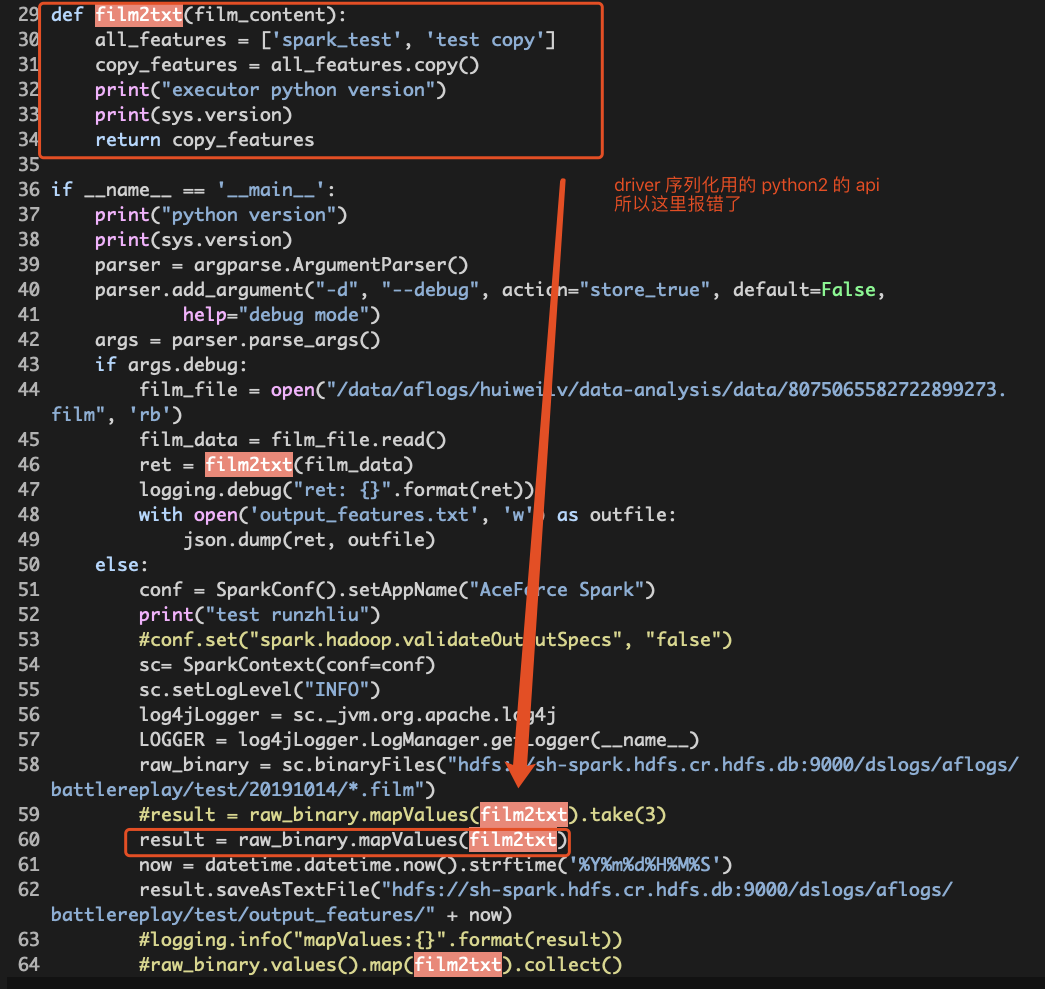
Driver和Executor的镜像Python版本不一致怎么办
比较典型的情况是用户需要使用 Python3,然后更新了 Executor 镜像的 Python 版本,忘记更新 Driver 的了,然后就任务就在 Driver 报错了。
这里举个例子。

原因: film2txt() 方法中用到的 List 的 copy() 方法属于 Python3 的方法。如果 Driver 镜像里使用 Python2,程序运行到 map() 的时候需要序列化 film2txt() 方法,这时候就会报错。
解决方法: 可以选用或者重新构建新的镜像,保证 Driver/Executor 镜像的 Python 版本和业务代码的 Python 版本一致。
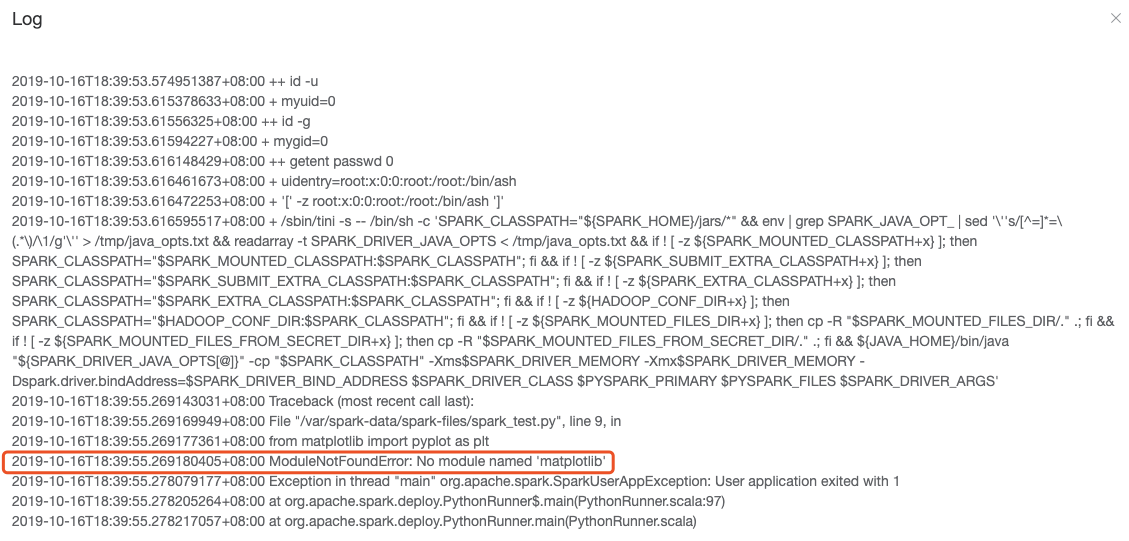
Driver出错了,错误信息显示某个包没有安装
原因: 因为默认提供的 Driver 镜像可能没有安装用户需要的包。
解决方法: 用户有需要,可以自定义镜像,并且在任务选项中选用自定义的镜像,确保镜像中有用户需要使用的包。
一些PySpark有用的文档
- Running Spark on Kubernetes的文档
警告
本文最后更新于 2017年2月1日,文中内容可能已过时,请谨慎参考。