CNN和Yolo结合的流水线
Table of contents:
概述
图片分成 patient 和 nonpatient,前者是病人的真实图片,后者可以理解成一个影像学的模型。
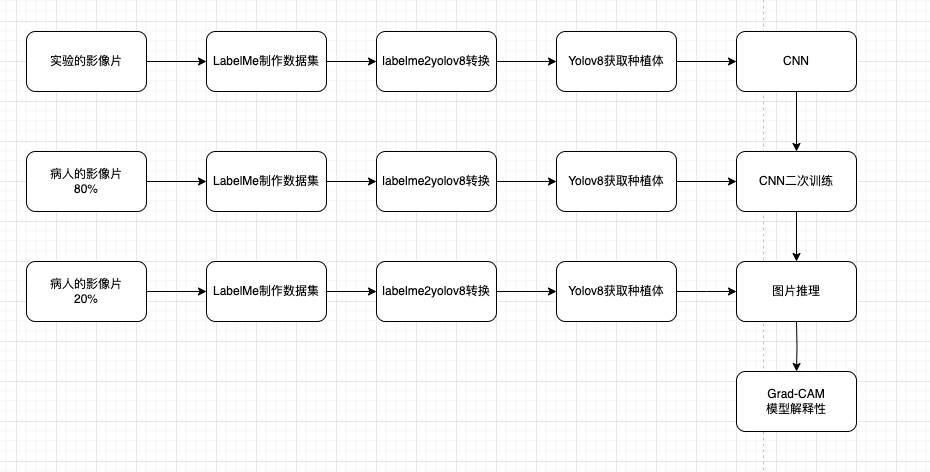
训练模型图片来源可以分为两种,通过 yolo 自动语义分割的图片以及用 labelme 人工标注的图片。前者的优点是通过少量的标注图片训练出来的 yolo 模型可以大量分割图片,省一点人工,缺点是 yolo 模型会有误差,不一定能分割很好。后者的优点是人工标注比较准确,缺点是相对耗时耗力。
| 图片来源 | 优点 | 缺点 |
|---|---|---|
| yolo分割 | 快速大量 | 有误差,需要人工筛选 |
| 人工labelme | 准确 | 耗费人力 |
数据格式协议
数据格式协议分为两部分,1是科研人员准备的原始数据,2是技术人员针对原始数据做的预处理和训练结果的目录格式和文件类型协议。这个协议目的是定义好数据进出的目录结构和格式。
数据读取的格式
除了下面标明的目录和格式以外,不要包含其他备份数据等,需要严格按照数据格式协议准备数据,否则有可能会出现不如预期的结果。
dataset
├── patient // 病人真实图片
├── loose // 相当于图片的分类
└── 1.png // 放原图即可,jpg/png/jpeg皆可,需要保证所有图片一个格式
└── 1.json // Labelme处理的结果,json文件名需要与图片文件名一致
└── 2.png
└── 2.json
└── tight
└── 1.png
└── 1.json
└── 2.png
└── 2.json
├── model // 影像模型图片
├── loose // 相当于图片的分类
└── 1.png // 放原图即可,jpg/png/jpeg皆可,需要保证所有图片一个格式
└── 1.json // Labelme处理的结果
└── 2.png
└── 2.json
└── tight
└── 1.png
└── 1.json
└── 2.png
└── 2.json
结果输出格式
结果输出的格式可以帮助大家理解机器学习过程中和结束之后的一些具体指标和图表,主要是技术人员关注,科研人员相对查看例如 grad-cam 这样的目录即可。
dataset // 结果数据和训练数据都会放在dataset目录的同一层
├── YOLOv8Dataset // 用于yolo模型的训练
├── train // train/val的比例为0.8/0.2
├── images
└── labels
└── val
├── images
└── labels
├── loose_annotated // yolo模型训练出来之后,用yolo模型在原始loose病人图片上做标记
├── loose_seg // yolo模型训练出来之后,用yolo模型在原始loose病人图片上做语义分割,可以用于后面fine-tuned训练
├── tight_annotated // yolo模型训练出来之后,用yolo模型在原始tight病人图片上做标记
├── tight_seg // yolo模型训练出来之后,用yolo模型在原始tight病人图片上做语义分割,可以用于后面fine-tuned训练
├── fine-tuned-dataset // 用于fine-tuned模型的训练
├── loose // 病人loose预处理之后的图片
├── tight // 病人tight预处理之后的图片
├── train // train/test/val是按照0.7/0.15/0.15的比例来随机生成的
├── loose
└── tight
├── test
├── loose
└── tight
└── val
├── loose
└── tight
├── grad-cam // grad-cam的结果,跟CNN可读性有关
├── loose
└── tight
├── nonpatient-dataset // 用于raw模型的训练,raw模型是根据影像模型的图片训练的CNN模型
├── loose // 影像模型loose预处理之后的图片
├── tight // 影像模型tight预处理之后的图片
├── train // train/test/val是按照0.7/0.15/0.15的比例来随机生成的
├── loose
└── tight
├── test
├── loose
└── tight
└── val
├── loose
└── tight
├── grad-cam
├── loose
└── tight
Step1 Yolo阶段
整理图片
所有图片整理成如下的结构,当前目录 $PWD 就是 RAW_JSONS_DIR。
dataset
├── loose // 相当于图片的分类
└── 1.png // 放原图即可,jpg/png/jpeg皆可,需要保证所有图片一个格式
└── 1.json // Labelme处理的结果
└── 2.png
└── 2.json
└── tight
└── 1.png
└── 1.json
└── 2.png
└── 2.json
labelme2yolov8处理图片
python -m labelme2yolov8 --json_dir ${RAW_JSONS_DIR} --val_size 0.2 --test_size 0
转换完后,目录结构如下,为了尽可能多收集语义分割的训练图片,这里不会区分 loose/tight。
dataset
├── loose // 相当于图片的分类
└── 1.png // 放原图即可,jpg/png/jpeg皆可,需要保证所有图片一个格式
└── 1.json // Labelme处理的结果
└── 2.png
└── 2.json
└── tight
└── 1.png
└── 1.json
└── 2.png
└── 2.json
└── YOLOv8Dataset // labelme2yolov8的结果
├── dataset.yaml
├── train
│ ├── images
│ └── labels
└── val
├── images
└── labels
YoloV8语义分割模型训练
YoloV8 做语义分割训练。
python 00-yolo-seg.py
分割病人种植体
通过上面的部署,得到语义分割模型,可以在病人的影像资料,分割出牙齿的位置。
python 01-patient-seg.py
Step2 CNN阶段
准备图片
.
├── cnn-dataset
├── loose
├── tight
├── dataset
├── loose
├── tight
│ └── YOLOv8Dataset
│ ├── train
│ │ ├── images
│ │ └── labels
│ └── val
│ ├── images
│ └── labels
├── train
│ ├── loose
│ └── tight
├── val
│ ├── loose
│ └── tight
└── YOLOv8Dataset
├── train
│ ├── images
│ └── labels
└── val
├── images
└── labels
python 03-nonpatient-crop.py
python 03-nonpatient-seg.py
训练初始化CNN模型
python 04-nonpatient-raw-cnn.py
Fine-tuned最终CNN型
python 05-fine-tuned-cnn.py
模型解释性
python 06-grad-cam.py