概述
OpenVINO™ Model Server is a scalable, high-performance solution for serving machine learning models optimized for Intel® architectures.
OpenVINO 是 Intel 推出的用于推理服务的 CPU 加速器,如果你用过 NVIDIA TensorRT,那么对这个概念应该不会太陌生。OpenVINO 支持多种深度学习的计算框架,简而言之,他就是让你更快!其实就是让你的推理服务响应更快,和吞吐更高。

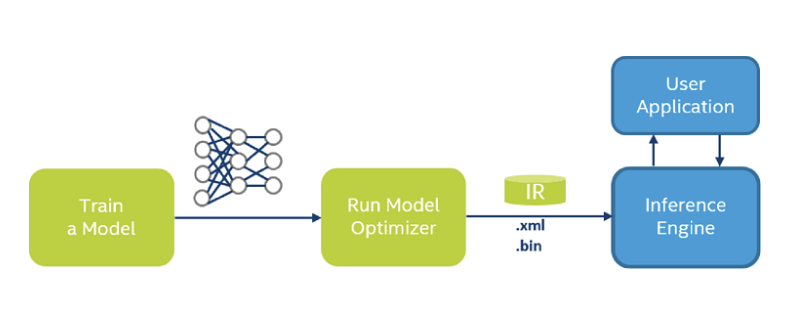
如果你有一个训练好的模型(多种框架),那么可以按照下面几步来使用 OpenVINO 来部署模型。
- 安装OpenVINO 的工具集
- 使用
Model Optimizer将你的模型转换为Intermediate Representation格式,简称IR
- 通过
Inference Engine部署模型到你的环境(bare metal/container)
目前在 Kubernetes 上部署推理服务的很多用户,而且很多业务都是部署到 CPU 上就够了,用上 OpenVINO 之后,性能可能会有一定的提升,所以关注模型推理性能和服务吞吐的同学,可以尝试一下。
实战
演示主要分为两部分,一是 OpenVINO on Docker,就是使用 Docker 来部署一个模型,二是 Kubernetes 集群上通过 Workload 来部署。
实战主要包括几个流程。
- 下载模型AlexNet,并通过Model Optimizer将模型转为IR
- 部署推理服务
- 找一张图片做预测
- 通过客户端测试Inference结果
OpenVINO on Docker
首先,我们需要按照步骤,把模型从 pb 文件,转化为 IR 格式。从一个深度学习模型宝藏库可以下载到这些模型。
简单来说,就是这里收集了很多业界流行的模型,并且提供了工具可以把模型转化为 openVINO 需要的格式。
下载模型AlexNet
下面这个例子里,只下载 AlexNet 模型。
1
2
3
4
5
6
7
8
9
10
11
12
13
|
# cd downloader/
[/open_model_zoo/tools/downloader]# ./downloader.py --name alexnet
################|| Downloading models ||################
========== Downloading /data/tencent/open_model_zoo/tools/downloader/public/alexnet/alexnet.prototxt
... 100%, 3 KB, 21075 KB/s, 0 seconds passed
========== Downloading /data/tencent/open_model_zoo/tools/downloader/public/alexnet/alexnet.caffemodel
... 100%, 238146 KB, 14398 KB/s, 16 seconds passed
################|| Post-processing ||################
========== Replacing text in /data/tencent/open_model_zoo/tools/downloader/public/alexnet/alexnet.prototxt
|
下载下来的模型文件是下面这样的。
1
2
3
4
5
6
7
8
9
10
11
12
13
|
# tree
.
├── alexnet.caffemodel
├── alexnet.prototxt
├── alexnet.prototxt.orig
├── FP16
│ ├── alexnet.bin
│ ├── alexnet.mapping
│ └── alexnet.xml
└── FP32
├── alexnet.bin
├── alexnet.mapping
└── alexnet.xml
|
模型转换
利用 converter.py 将下载的模型进行转换,转换成 Inference Engine 能接受的格式 xml/bin 文件等。建议看一下 -h 选项的信息,有个关键的 -mo 选项。
关键是在 --mo 因为要指定 OpenVINO 项目里的 Model Optimizer,顾名思义,这是一个模型优化器,可以对模型进行一些裁剪等优化的操作,我的转换过程是这样的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
|
[/open_model_zoo/tools/downloader]# ./converter.py --name alexnet --mo /opt/intel/openvino/deployment_tools/model_optimizer/mo.py
========= Converting alexnet to IR (FP16)
Conversion command: /root/anaconda3/bin/python3 -- /opt/intel/openvino/deployment_tools/model_optimizer/mo.py --framework=caffe --data_type=FP16 --output_dir=/data/tencent/open_model_zoo/tools/downloader/public/alexnet/FP16 --model_name=alexnet '--input_shape=[1,3,227,227]' --input=data '--mean_values=data[104.0,117.0,123.0]' --output=prob --input_model=/data/tencent/open_model_zoo/tools/downloader/public/alexnet/alexnet.caffemodel --input_proto=/data/tencent/open_model_zoo/tools/downloader/public/alexnet/alexnet.prototxt
Model Optimizer arguments:
Common parameters:
- Path to the Input Model: /data/tencent/open_model_zoo/tools/downloader/public/alexnet/alexnet.caffemodel
- Path for generated IR: /data/tencent/open_model_zoo/tools/downloader/public/alexnet/FP16
- IR output name: alexnet
- Log level: ERROR
- Batch: Not specified, inherited from the model
- Input layers: data
- Output layers: prob
- Input shapes: [1,3,227,227]
- Mean values: data[104.0,117.0,123.0]
- Scale values: Not specified
- Scale factor: Not specified
- Precision of IR: FP16
- Enable fusing: True
- Enable grouped convolutions fusing: True
- Move mean values to preprocess section: False
- Reverse input channels: False
Caffe specific parameters:
- Path to Python Caffe* parser generated from caffe.proto: /opt/intel/openvino/deployment_tools/model_optimizer/mo/front/caffe/proto
- Enable resnet optimization: True
- Path to the Input prototxt: /data/tencent/open_model_zoo/tools/downloader/public/alexnet/alexnet.prototxt
- Path to CustomLayersMapping.xml: Default
- Path to a mean file: Not specified
- Offsets for a mean file: Not specified
Model Optimizer version: 2019.3.0-408-gac8584cb7
[ WARNING ]
Detected not satisfied dependencies:
protobuf: installed: 3.11.2, required: 3.6.1
Please install required versions of components or use install_prerequisites script
/opt/intel/openvino_2019.3.376/deployment_tools/model_optimizer/install_prerequisites/install_prerequisites_caffe.sh
Note that install_prerequisites scripts may install additional components.
[ SUCCESS ] Generated IR model.
[ SUCCESS ] XML file: /data/tencent/open_model_zoo/tools/downloader/public/alexnet/FP16/alexnet.xml
[ SUCCESS ] BIN file: /data/tencent/open_model_zoo/tools/downloader/public/alexnet/FP16/alexnet.bin
[ SUCCESS ] Total execution time: 27.12 seconds.
|
可以看到 IR 格式模型的地址,已经两个文件 alexnet.xml 和 alexnet.bin。
然后我们按照官方例子要求的格式,重新构建文件夹的结构。
1
2
3
4
5
6
7
|
# tree
.
└── model1 // 模型的名字 name
└── 1 // 模型的版本 version
├── alexnet.bin
├── alexnet.mapping
└── alexnet.xml
|
OpenVINO镜像和部署
为了部署模型,我们需要 OpenVINO 的镜像。
1
|
docker pull intelaipg/openvino-model-server
|
下面几个参数的作用分别如下。
-v挂载本地/tmp/models/ 目录到容器/opt/ml目录ie_serving是镜像里OpenVINO的启动进程--model_path是模型地址,这里指容器内的模型所在的目录--model_name上文提到过,模型的名字port是grpc服务的端口rest_port是http服务的端口
1
2
3
4
5
6
7
8
9
10
11
|
docker run \
--rm -d \
-v /tmp/models/:/opt/ml:ro \
-p 9001:9001 \
-p 8001:8001 \
intelaipg/openvino-model-server:latest \
/ie-serving-py/start_server.sh ie_serving model \
--model_path /opt/ml/model1 \
--model_name my_model \
--port 9001 \
--rest_port 8001
|
可以看到 OpenVINO 的容器已经处于 RUNNING 状态了。
1
2
3
|
# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
afd6fffb4144 intelaipg/openvino-model-server:latest "/ie-serving-py/star…" 3 days ago Up 3 days 0.0.0.0:8001->8001/tcp, 0.0.0.0:9001->9001/tcp stoic_nash
|
查看容器的日志如下。
然后通过官方的 example_client.py 来测试一下服务的响应,一切正常。
1
2
|
# python rest_get_model_status.py --rest_port 8001 --model_name my_model
{'model_version_status': [{'version': '1', 'state': 'AVAILABLE', 'status': {'error_code': 'OK', 'error_message': ''}}]}
|
找一张图片
随便 Google 一张 car 的照片。
Inference测试
OpenVINO 的官方仓库,非常贴心的给出了很多客户端请求的例子,各位参考官方文档 example_client 即可。参考 Image Classification Python* Sample,执行下面这个脚本。
1
2
3
|
# pwd
/opt/intel/openvino/deployment_tools/inference_engine/samples/python_samples/classification_sample
python classification_sample.py -m /opt/intel/openvino/deployment_tools/model_optimizer/alexnet.xml -i /tmp/car.jpeg
|
最后分类 label 可以参考这里。
OpenVINO on Kubernetes
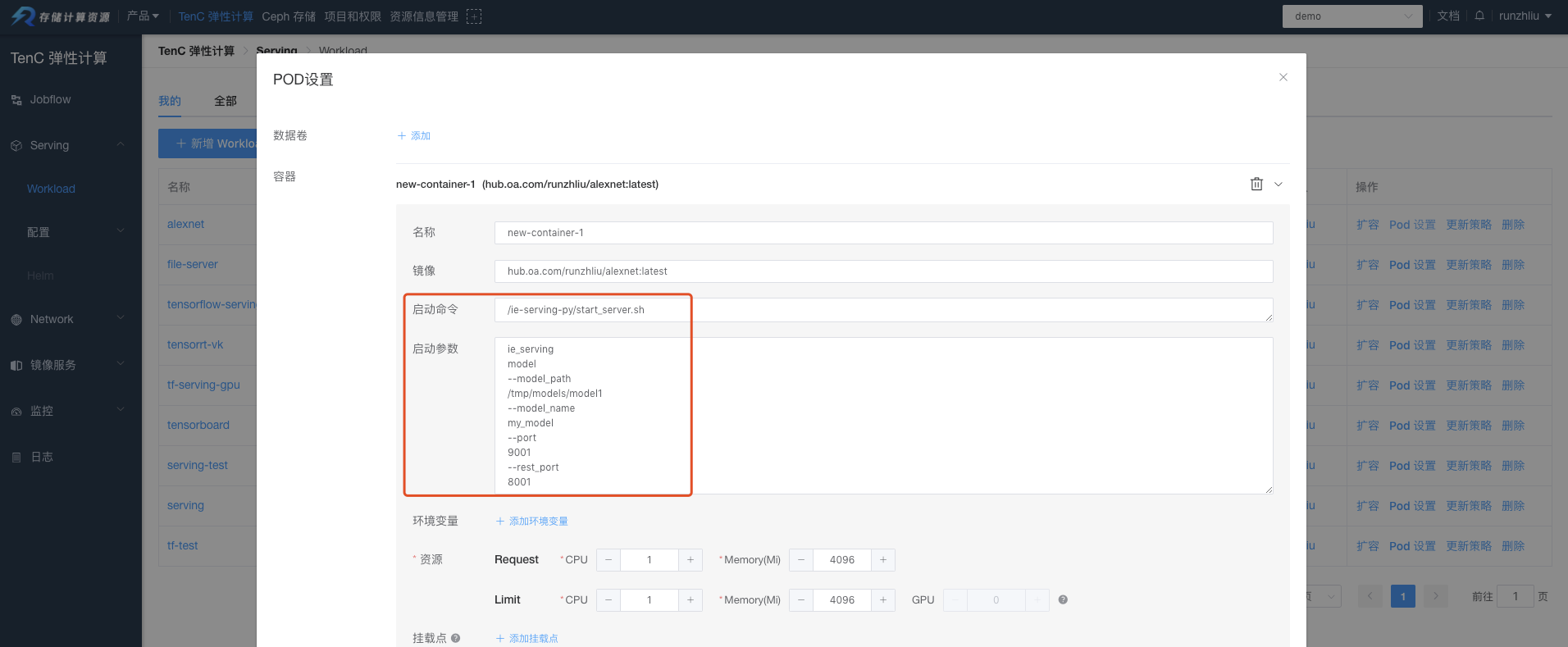
前面花了很大篇幅在讲如何通过 Docker 来运行起来一个 OpenVINO 的推理服务,下面需要讲下怎么在 Kubernetes Workload 下部署一个了。在 Workload 下部署一个推理服务,关键是要把模型文件上传到存储。为了简化 Demo 的流程,我把模型放入新的镜像,用 intelaipg/openvino-model-server:latest 作为基础镜像重新构建。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
# ls
alexnet.bin alexnet.mapping alexnet.xml Dockerfile
# cat Dockerfile
FROM intelaipg/openvino-model-server:latest
COPY * /tmp/models/model1/1/
# 构建
docker build -t runzhliu/alexnet:latest .
Sending build context to Docker daemon 122MB
Step 1/2 : FROM intelaipg/openvino-model-server:latest
---> 0fbcc7efb1cd
Step 2/2 : COPY * /tmp/models/model1/1/
---> Using cache
---> c6ea4413aaae
Successfully built c6ea4413aaae
Successfully tagged runzhliu/alexnet:latest
# 推到镜像仓库
docker push runzhliu/alexnet:latest
|
运行主要是通过下面这个命令,将这个命令放到 Workload 即可。
1
2
3
4
5
|
./start_server.sh ie_serving model \
--model_path /tmp/models/model1 \
--model_name my_model \
--port 9001 \
--rest_port 8001
|
当然了,TenC 有 Ceph 存储服务作为存储资源的方式,而且 OpenVINO 是支持通过 S3 来读取模型数据的。
1
2
3
4
5
6
7
|
docker run --rm -d -p 9001:9001 ie-serving-py:latest \
-e AWS_ACCESS_KEY_ID="${AWS_ACCESS_KEY_ID}" \
-e AWS_SECRET_ACCESS_KEY="${AWS_SECRET_ACCESS_KEY}" \
-e AWS_REGION="${AWS_REGION}" \
-e S3_ENDPOINT="${S3_ENDPOINT}" \
/ie-serving-py/start_server.sh ie_serving model --model_path
s3://bucket/model_path --model_name my_model --port 9001 --batch_size auto --model_version_policy '{"all": {}}'
|
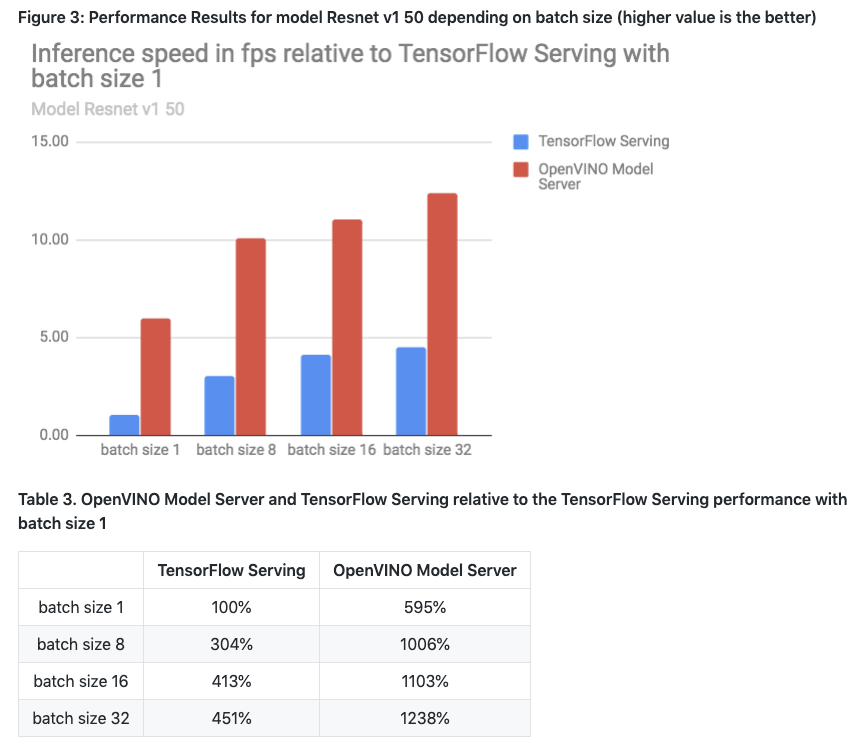
关于性能的 Benchmark,可以参考官方的报告 Performance Results。提升可以说是非常明显的。
另外,我们也可以在容器平台上自己跑一次 Benchmark 测试来验证一下。
参考资料
- OpenVINO ToolKit
- Install the Intel® Distribution of OpenVINO™ Toolkit Core Components
- Introduction to Intel® Deep Learning Deployment Toolkit
- Using OpenVINO™ Model Server in a Docker Container
警告
本文最后更新于 2017年2月1日,文中内容可能已过时,请谨慎参考。