概述
NVIDIA TensorRT Inference Server 是 NVIDIA 推出的,经过优化的,可以在 NVIDIA GPUs 使用的推理引擎,TensorRT 有下面几个特点。
- 支持多种框架模型,包括TensorFlow GraphDef, TensorFlow SavedModel, ONNX, PyTorch和Cadde2 NetDef等模型格式
- 支持多个模型的并发请求
- 支持Batching批量请求
- 模型仓库支持本地文件系统,或者Google Cloud Storage以及S3
更多内容可以参考 TensorRT 官方文档。
TenC 弹性计算平台支持通过 Workload 部署 TensorRT,通过 GPU 的场景化调度,以及 S3 模型仓库,可以让用户轻松地部署模型的推理服务。
TensorRT Inference Server,下面简称 TIS,除了可以跑在 GPU 环境,还可以跑在 non-GPU 环境,这是需要注意的,因此在启动了 TIS 后,最好看一下日志,是否有出现 GPU 设备的信息。
前提
下面是通过 nvidia-docker 运行起来的 TensorRT 容器,这里关注几个关键参数。进程通过 trtserver 命令启动,--model-repository 指定模型仓库的地址。
1
|
nvidia-docker run --rm --shm-size=1g --ulimit memlock=-1 --ulimit stack=67108864 -p8000:8000 -p8001:8001 -p8002:8002 -v/path/to/model/repository:/models <tensorrtserver image name> trtserver --model-repository=/models
|
工作负载配置
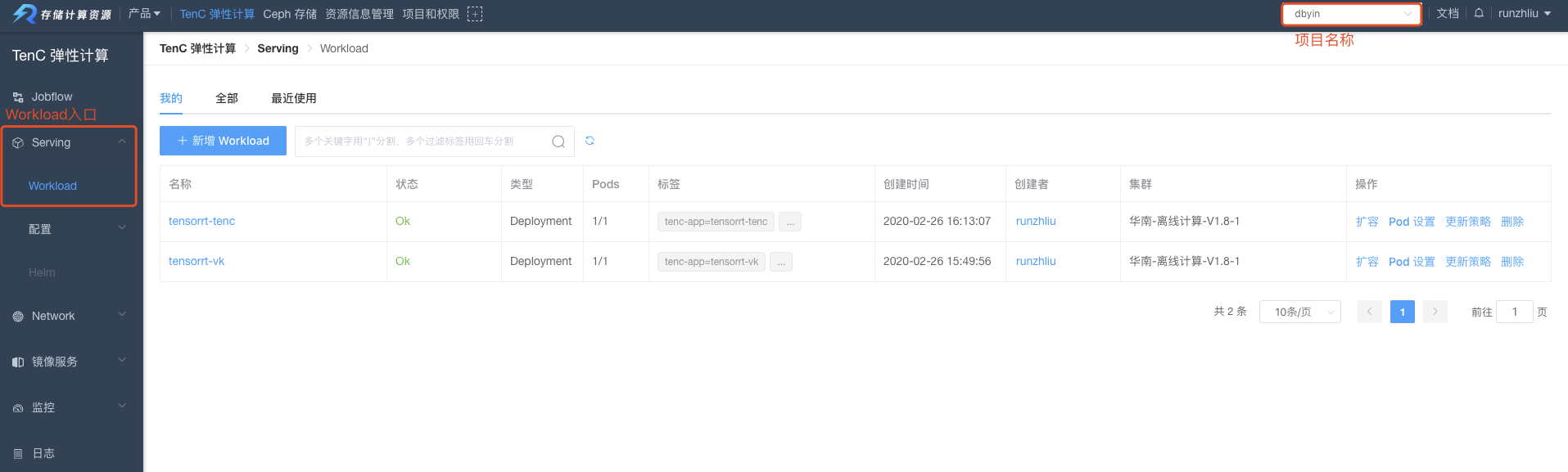
创建工作负载
在 Serving 模块找到 Workload。

Pod设置
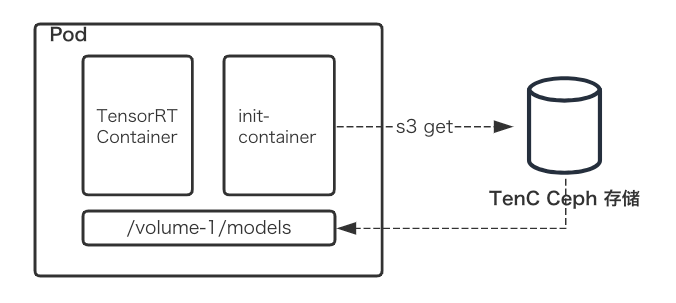
下面是在 Workload 部署 TensorRT 的一个示意图,流程如下。
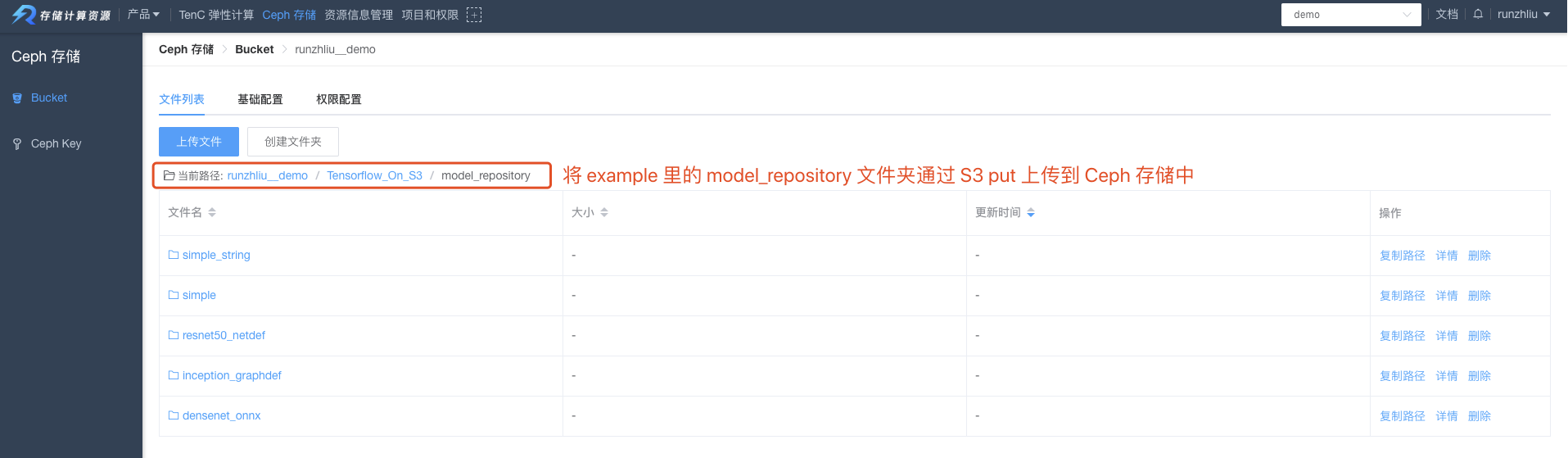
- 通过S3 put上传模型仓库的文件
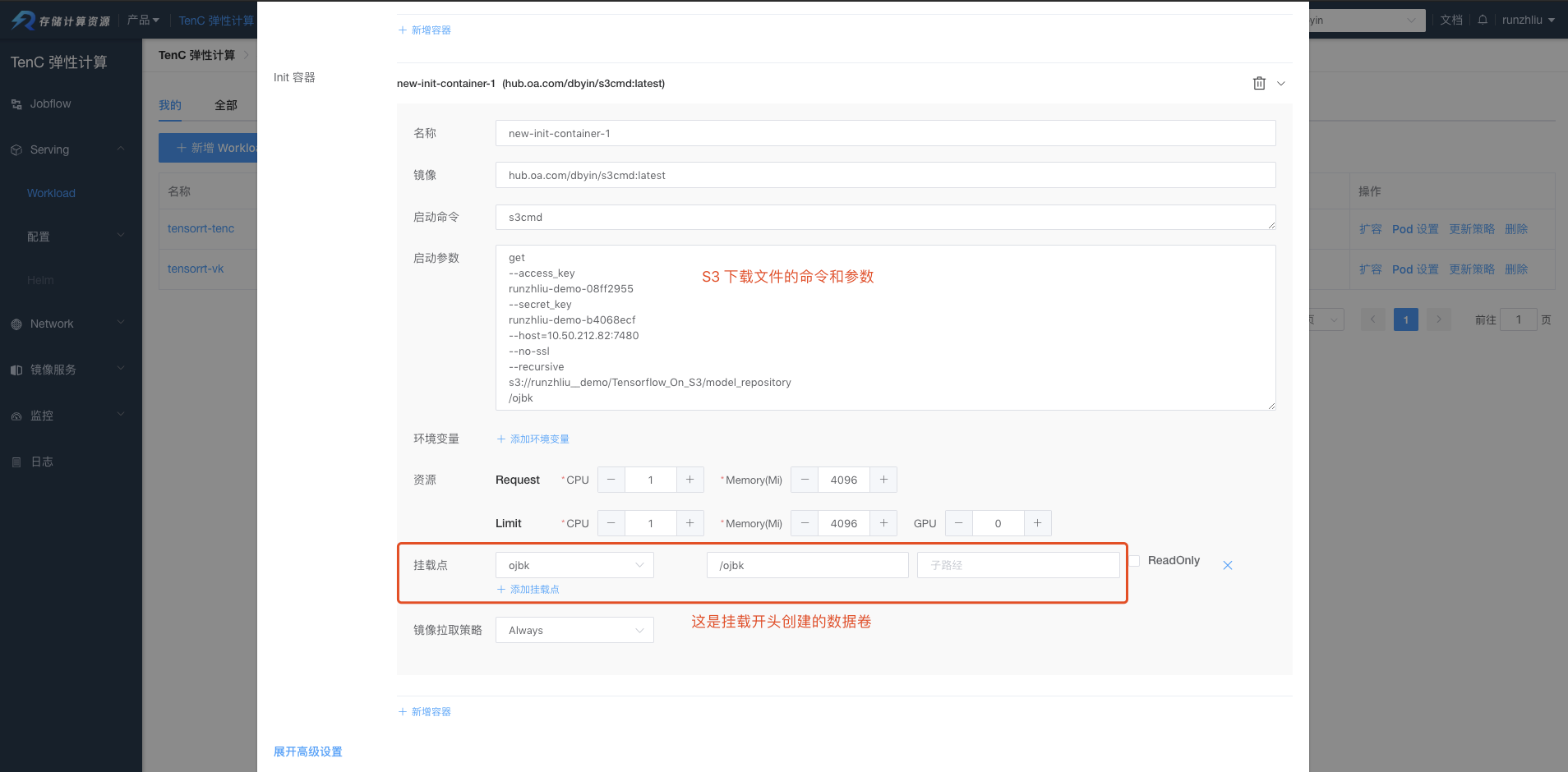
- Workload指定init-container拉取模型文件,并且下载到挂载的目录
/volume-1/models/
- TensorRT容器挂载上述目录,启动
trtserver
上传模型文件。
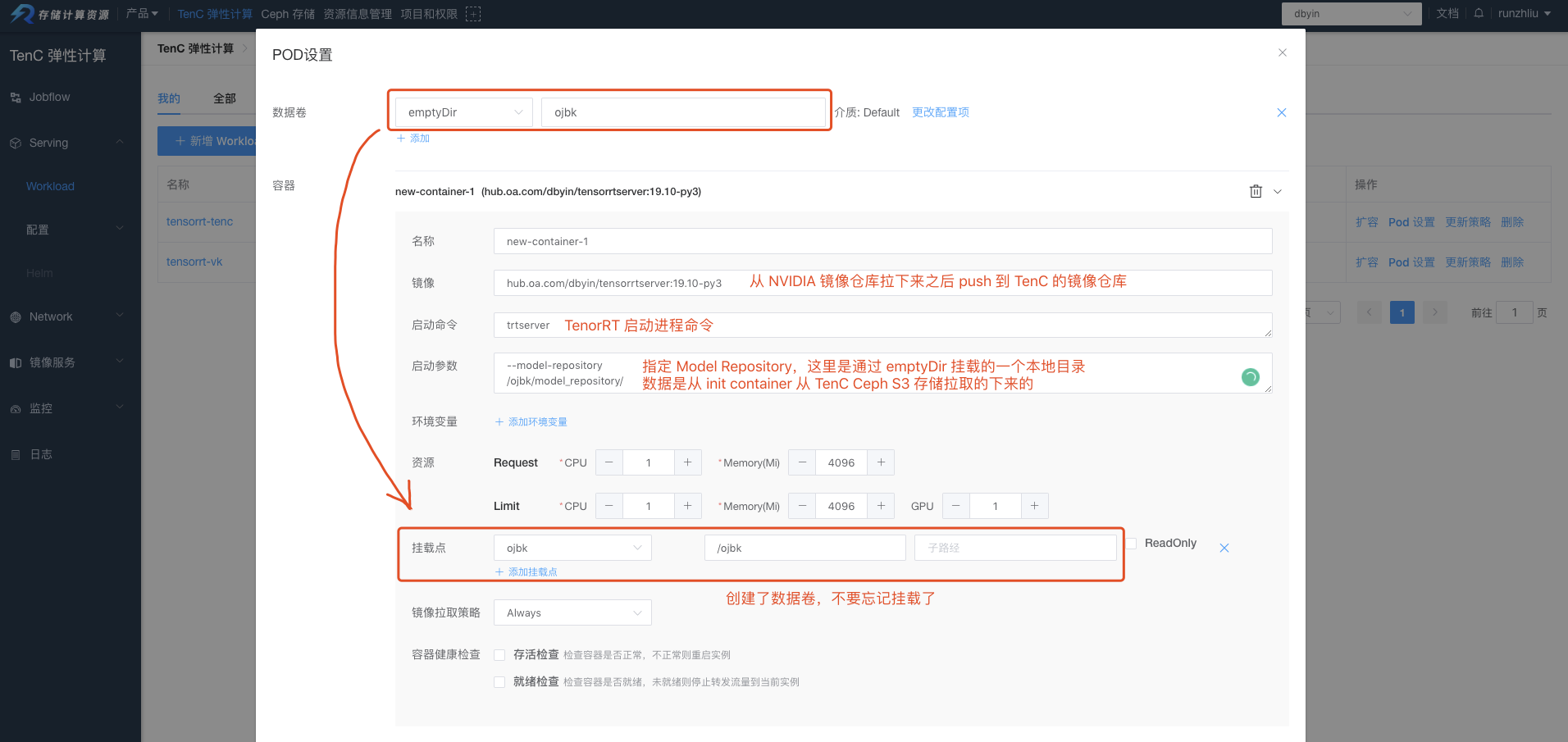
配置数据卷和 container。
配置 init-container,并且指定挂载的数据卷。
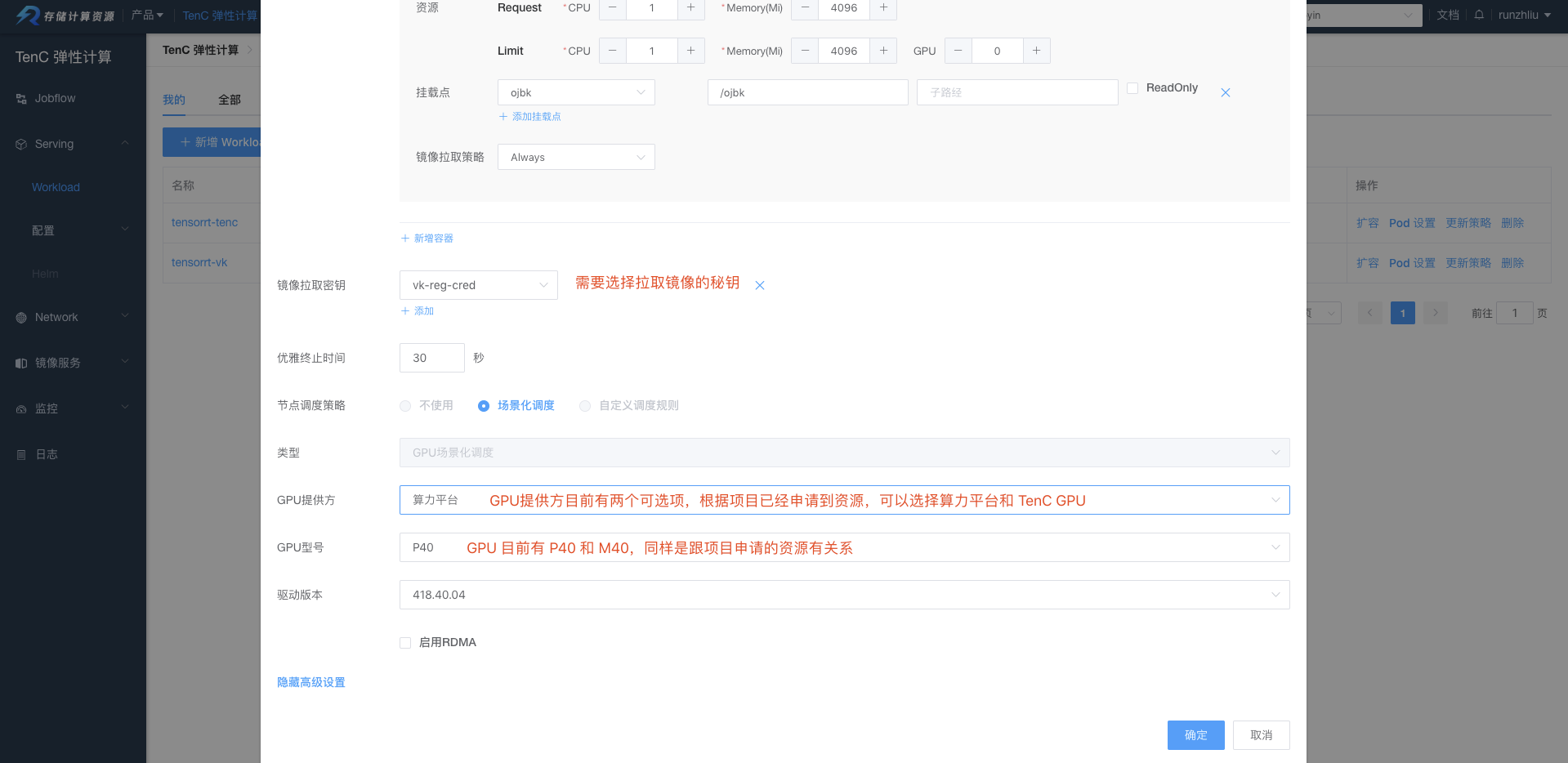
选择使用的 GPUs,需要注意的是,这里的 GPU 资源需要提前给项目申请。目前支持算力平台以及 TenC 提供的 GPUs。如果选择算力平台,还需要指定镜像拉取的秘钥。
验证
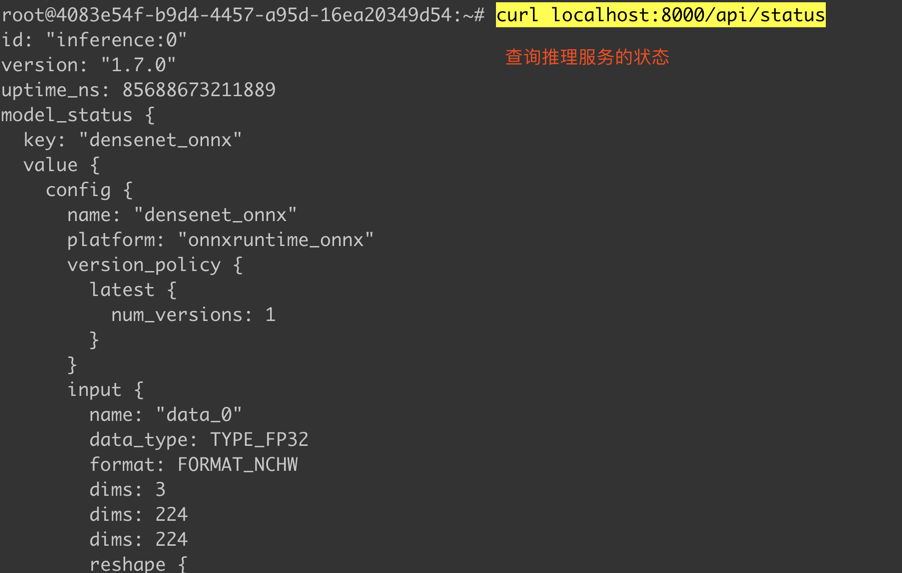
首先验证推理服务的状态,看服务是否正常运行。
进入容器后,请求运行 curl localhost:8000/api/status。可以看到返回一些模型的状态和推理服务版本的一些信息。
为了验证,从 NVIDIA 的镜像仓库找一个安装好客户端的镜像 tensorrtserver:19.10-py3-clientsdk,并且在客户端容器中请求 TensorRT 的推理服务。
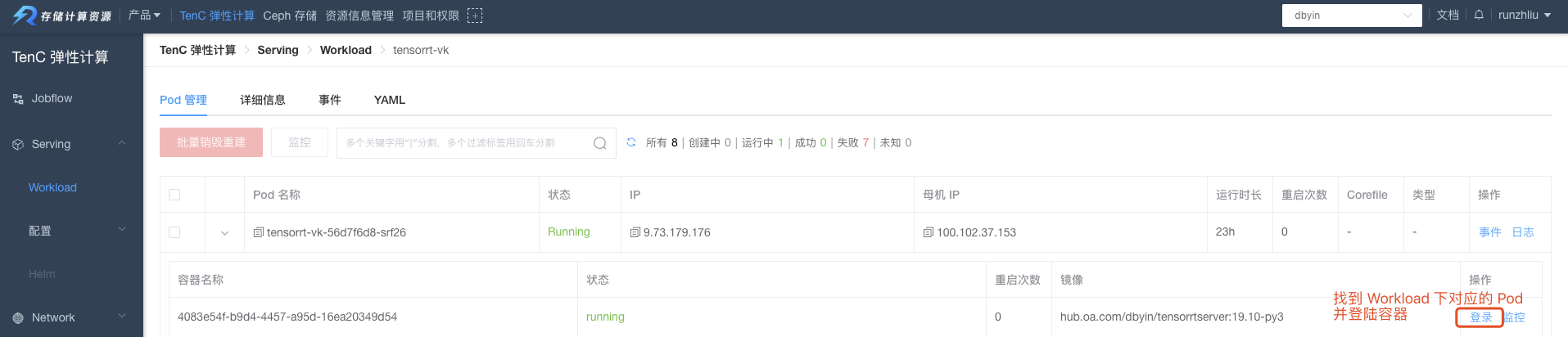
验证的过程,可以通过部署一个 Jobflow 通用计算任务,然后进入容器,对目标推理服务进行预测请求。
进入容器,通过下面的命令来进行推理。
image_client客户端-u默认是localhost:8000-m指定模型
1
|
image_client -u 6.19.120.17:8000 -m resnet50_netdef -s INCEPTION images/mug.jpg
|
更多关于 Serving 的使用,可以参考相关 wiki。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
|
spec:
containers:
- args:
- --model-repository
- /ojbk/model_repository/
command:
- /opt/tensorrtserver/bin/trtserver
env:
- name: PATH
value: /opt/tensorrtserver/bin:/usr/local/nvidia/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
- name: LD_LIBRARY_PATH
value: /opt/tensorrtserver/lib:/usr/local/nvidia/lib:/usr/local/nvidia/lib64
- name: LIBRARY_PATH
value: '/usr/local/cuda/lib64/stubs:'
image: hub.oa.com/runzhliu/tensorrtserver:19.10-py3
imagePullPolicy: Always
name: new-container-1
resources:
limits:
alpha.kubernetes.io/nvidia-gpu: "1"
cpu: "1"
memory: 4Gi
requests:
alpha.kubernetes.io/nvidia-gpu: "1"
cpu: "1"
memory: 4Gi
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /ojbk
name: ojbk
- mountPath: /usr/local/nvidia
name: nvidia-driver
- mountPath: /var/run/secrets/kubernetes.io/serviceaccount
name: default-token-4dkll
readOnly: true
dnsPolicy: ClusterFirst
nodeName: 100.119.242.53
nodeSelector:
alpha.kubernetes.io/nvidia-gpu-driver: 418.87.01
alpha.kubernetes.io/nvidia-gpu-name: P40
tencent.cr/resource-provider: tenc
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
serviceAccount: default
serviceAccountName: default
terminationGracePeriodSeconds: 30
volumes:
- emptyDir: {}
name: ojbk
- hostPath:
path: /var/lib/nvidia-docker/volumes/nvidia_driver/latest
type: ""
name: nvidia-driver
- name: default-token-4dkll
secret:
defaultMode: 420
secretName: default-token-4dkll
|
参考资料
- NVIDIA TensorRT QuickStart
- NVIDIA 镜像仓库
- Workload 使用指引
警告
本文最后更新于 2017年2月1日,文中内容可能已过时,请谨慎参考。