nvidia-smi报错排查和解决
概述
排查一个 nvidia-docker 的问题。
官方issue
从 nvidia-docker 的官方 issue 中检索,大概发现了如下这些 issue ,大概的意思是目前 nvidia-docker 依靠 runc hook 在 containerd 背后进行 GPU 设备注入(这是现有nvidia-container-runtime的基本/架构缺陷),并且是所有这些问题的根本原因。
k8s-device-plugin的启动参数
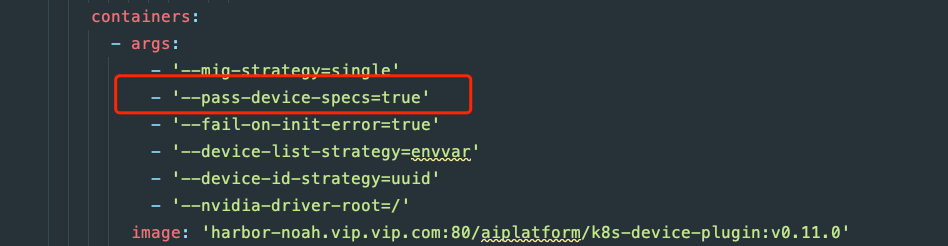
从代码上看,pass-device-specs 会把具体的设备和权限配置好。
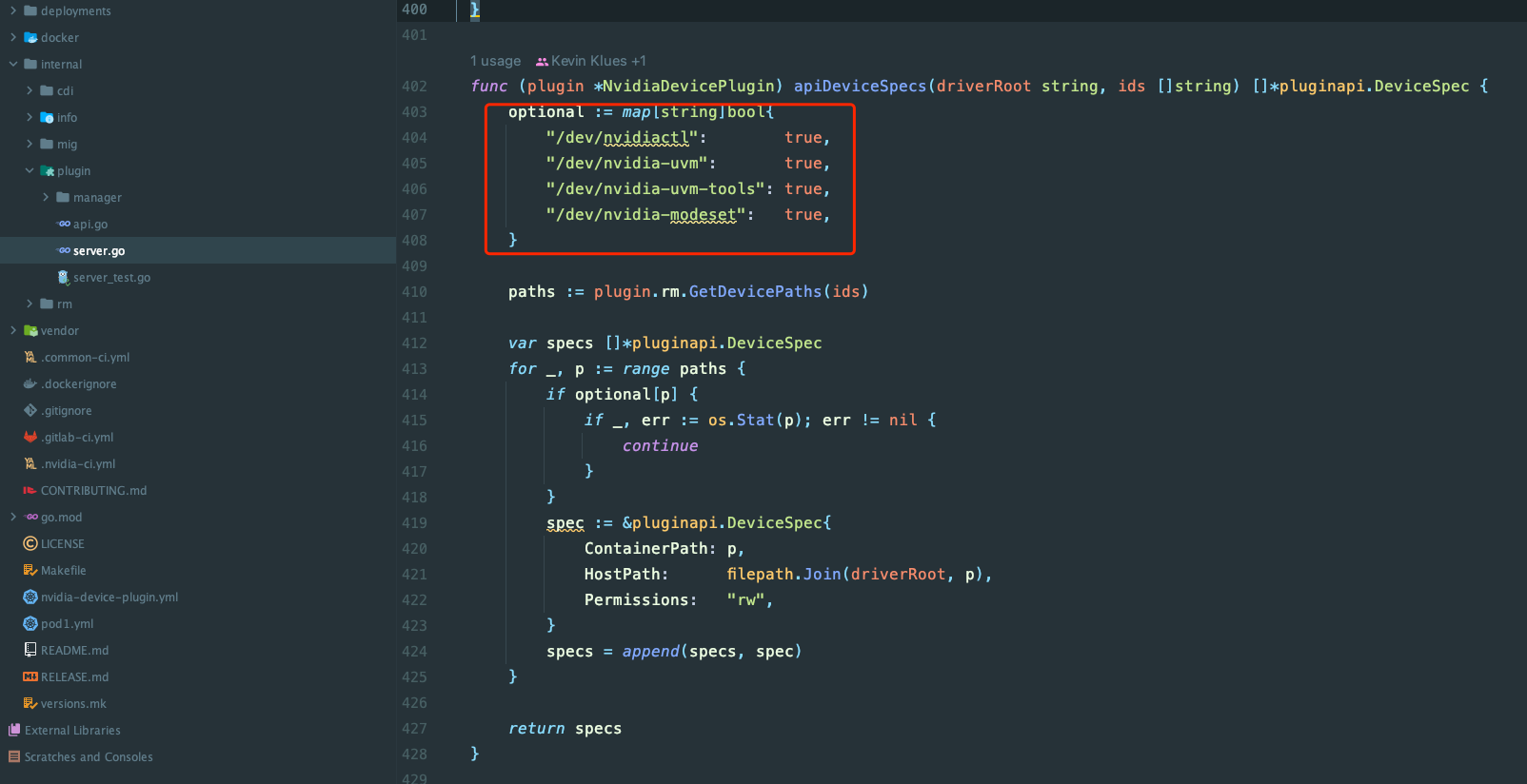
从我们的集群中部署的 k8s-device-plugin 中可以看到 pass-device-specs 给的是默认的 false。
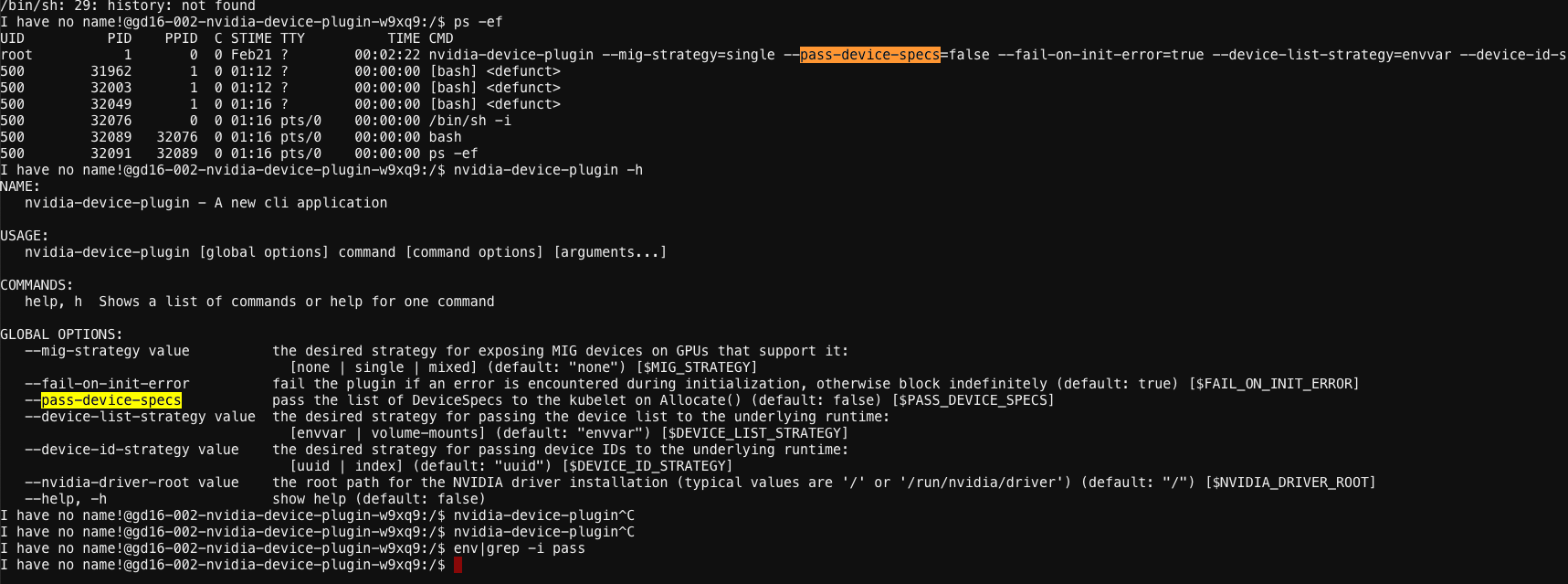
确认问题
通过堡垒机登录宿主机查看一下具体环境,通过 nsenter 进入容器的命令空间通过 strace 来查看一下执行 nvidia-smi 报错的原因。
|
|
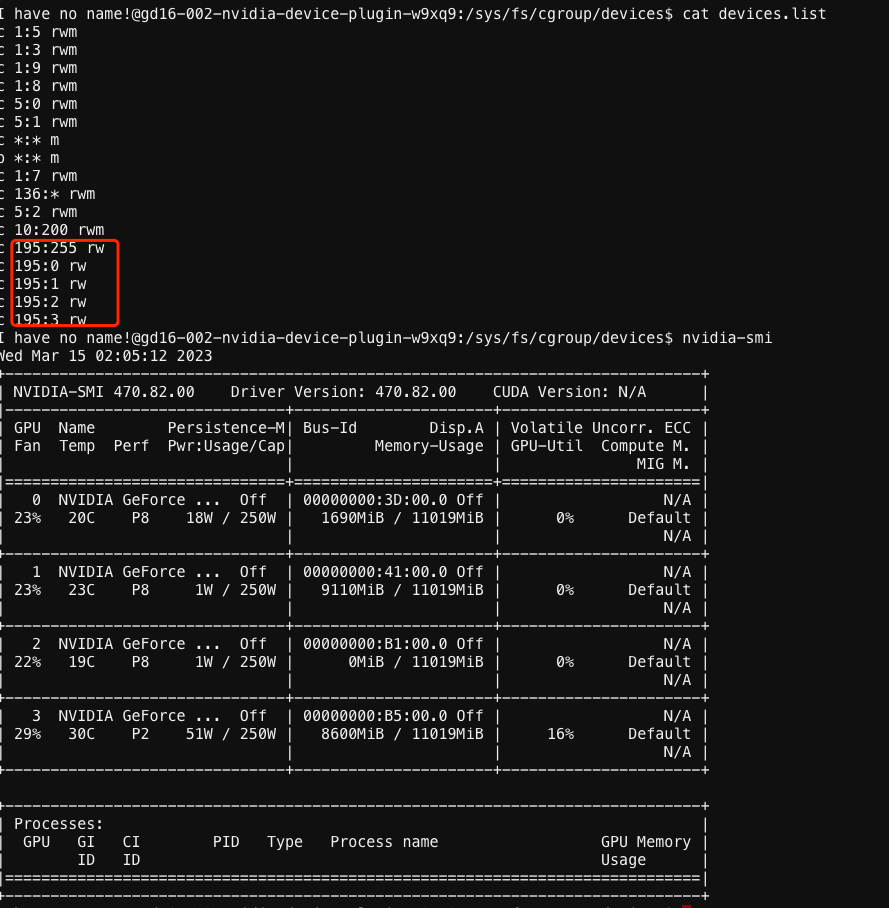
检查了两个挂载了 GPU 的容器,一个容器是可以正常执行 nvidia-smi 另一个则会报错。下面是宿主机下看到的设备。

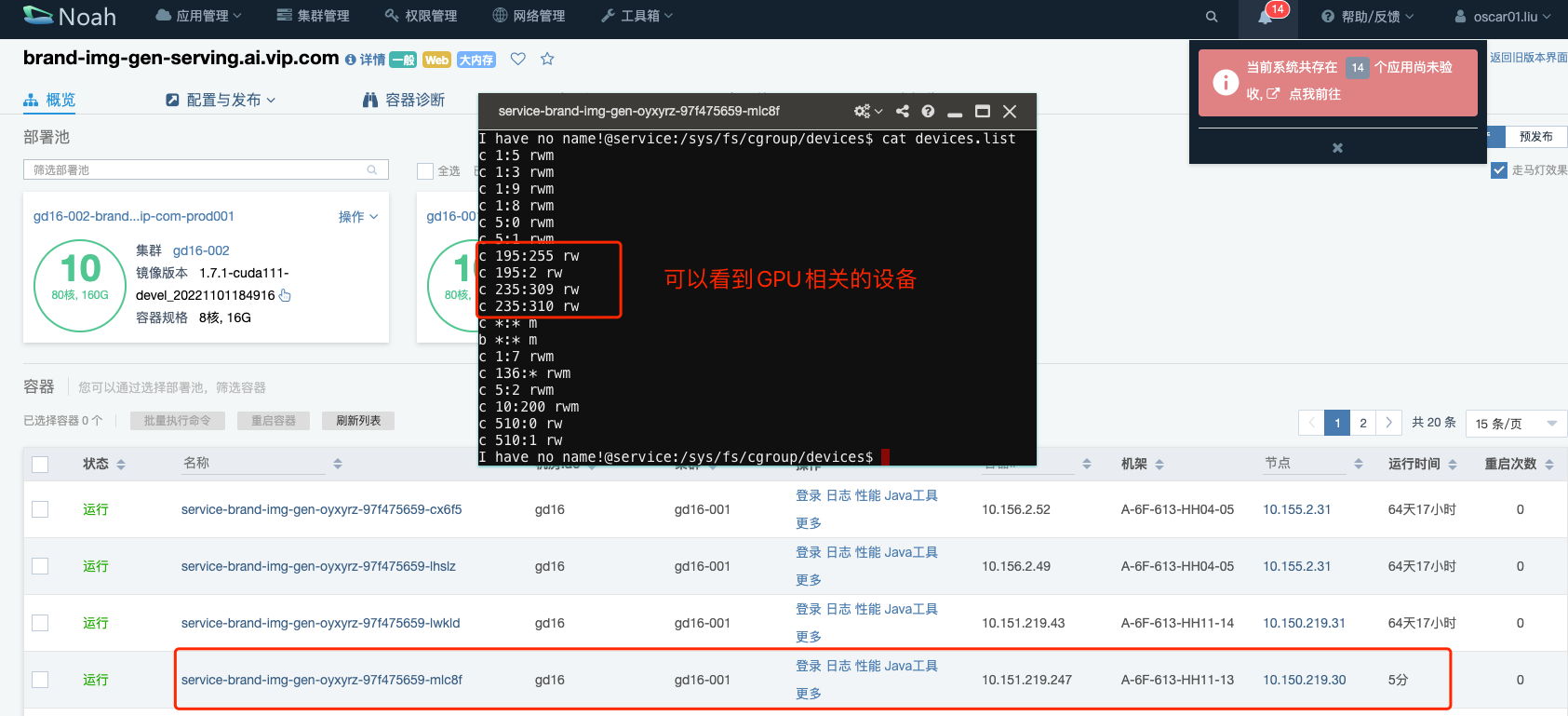
异常容器的 device.list 已经看不到 GPU 的设备了。
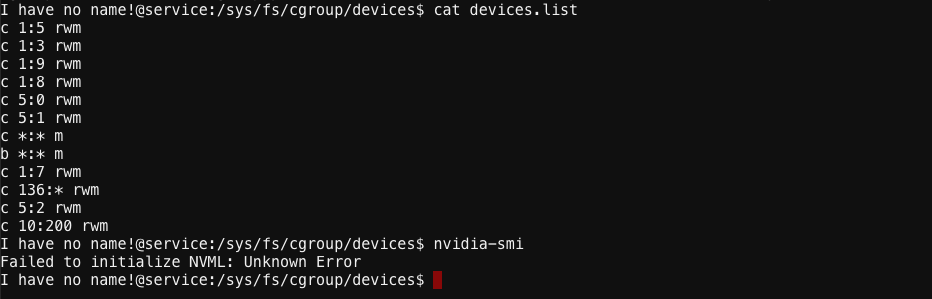
而正常容器是可以看到的。
从 strace 的结果上看,异常容器是没有权限使用 /dev/nvidiactl 的,所以执行结果就报错了。

解决的方案
我们的情况跟 issue 从 device 的结果来说是一样的,虽然原因不一样,比如说我们没有使用 static cpu 以及没有执行过 systemctl reload 之类的操作。
从 issue 看,我们的 runc 版本是比 1.3 低的,可以在不动 runc 的情况下,通过比较简单的 workaround 来尝试解决,可以参考这个 comment,更新一下 k8s-device-plugin 的启动参数 pass-device-specs=true,然后再验证一下问题是否会复现。
cgroup和device
cgroupv1 和 cgroupv2 在对待 device(包括GPU)方面有所不同。
在 cgroupv1 中,设备控制是通过子系统的控制文件来实现的,其中包括 devices.allow 和 devices.deny 文件。可以使用 major:minor rwm 格式的条目来定义允许或拒绝访问某个设备。但是,这种方法不够灵活,无法实现细粒度的设备控制。
相比之下,cgroupv2 引入了一个名为 Devices 的新控制器,允许更细粒度地控制设备访问。使用 cgroupv2,您可以创建称为 slice 的层次结构,每个slice 都可以分配一组设备(包括GPU)。可以使用 cgroupv2 的 devices.allow 和 devices.deny 文件来定义哪些设备可以访问。还可以使用cgroupv2 的 cgroup.event_control 文件来实现在容器内运行的应用程序与设备之间的绑定。
需要注意的是,cgroupv2 不完全兼容 cgroupv1,并且在实践中,许多 Linux 发行版仍然默认使用 cgroupv1。因此,在使用 GPU 时,需要确保在选择 cgroup 版本时考虑到设备控制的差异。因为目前公司环境主要还是 cgroupv1,短期应该不会有大规模的升级。
修复和验证
更新了 gd16-001 集群的 k8s-device-plugin DaemonSet,具体的修改如下。
然后重启 gd16-001 中的其中一个 Pod。
执行 nvdia-smi 查看结果,容器启动 1h 之后,都没有问题,再持续观察一下。
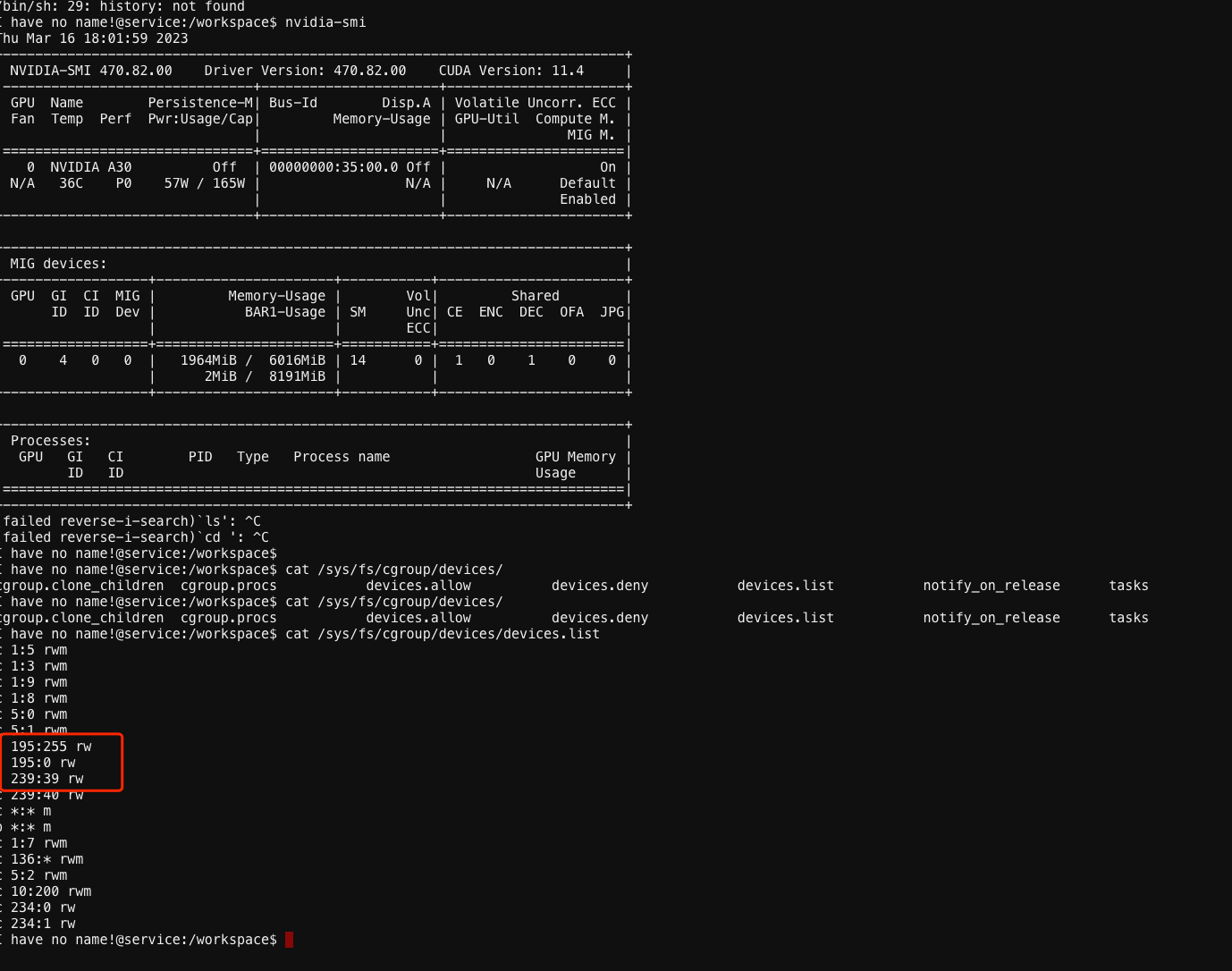
另外就是 gd16-002 的 Pod 即使重启也无法运行 nvidia-smi 这也是个比较奇怪的点,这难道就是一直都用不上 GPU 的原因?
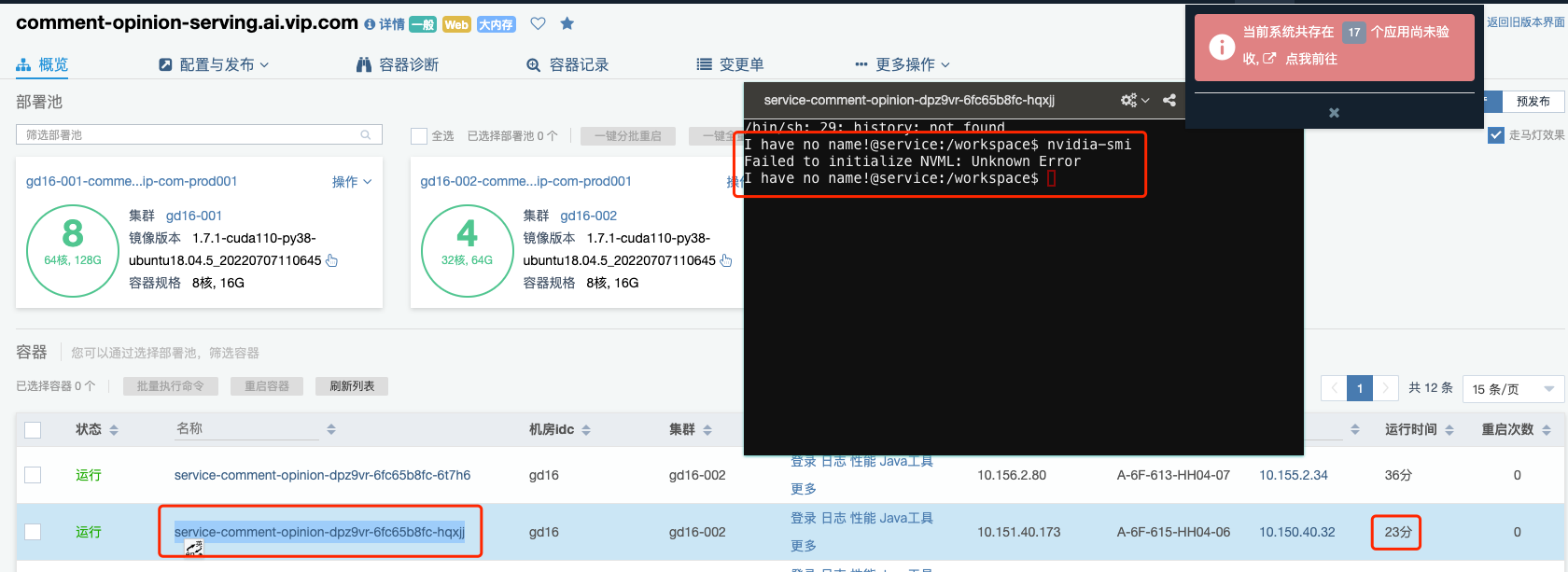
另外还有其他域是有类似的问题的,brand-img-gen-serving.ai.vip.com,comment-opinion-serving.ai.vip.com,再去验证一下。其中 gd16-001 中的 k8s-device-plugin 已经更新过了,但是 GPU 容器没有更新,因此上面说到的 GPU 设备以及 nvidia-smi 等命令的执行都是有问题的。
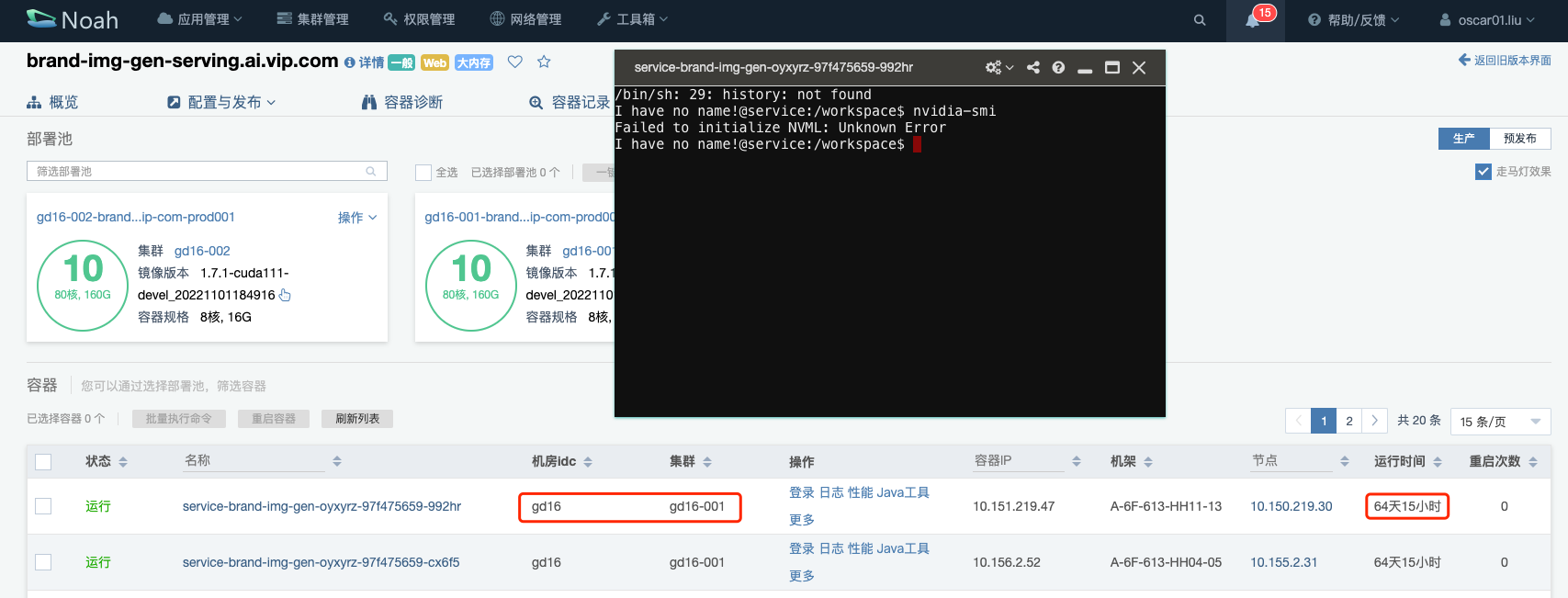
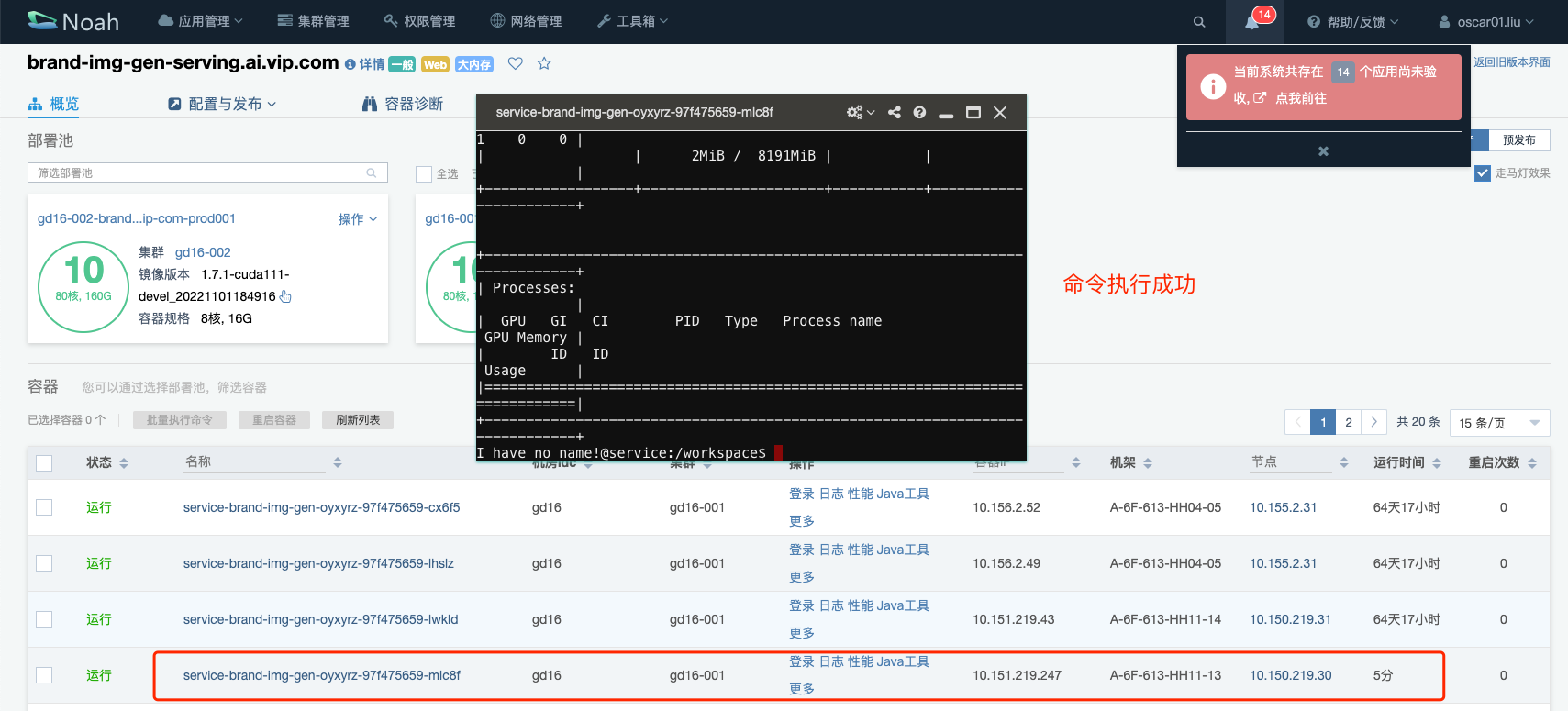
之后通过重启 GPU 容器,让容器重新挂载宿主机的这些设备,再验证效果,测试的结果显示,这个域的 GPU 容器可以正确读取到 GPU 设备,基本就完成了这个问题的验证了,至于为什么会出现这种原因,后面在另外的集群 gd16-002 再去调查,先把大部分集群的问题修复好。
参考资料
- 记NVIDIA显卡A100在K8S POD中Failed to initialize NVML: Unknown Error问题解决
- Nvidia Container与Kubelet CPU Manager的格格不入