概述
iSCSI 是比较常见的网络存储协议,很多容器的存储方案都有使用 iSCSI,Longhorn 就是基于 iSCSI 构建的块存储方案,下面会分别从 iSCSI 和 Longhorn 的角度相互解释一下原理。
名词解释
- iSCSI: Internet Small Computer System Interface
- SAN: Storage Area Network
- iSCSI target: 提供存储的服务器
- iSCSI initiator: 需要存储的服务器,也是客户端,initiator翻译成发起人/客户端
- NAS和SAN的区别: 前者给的文件系统,后者给的是存储设备
- Open-iSCSI: 其中一种iSCSI的软件实现
- TGT: 是用户态实现的iSCSI target,所有目标处理都在用户空间进行,Longhorn Target就是基于TGT的实现
Open-iSCSI
Open-iSCSI 包括两个守护进程 iscsid 和 iscsi,其中 iscsid 是主进程,iscsi 进程则主要负责根据配置在系统启动时进行发起端(Initiator)到服务端(target)的登录,建立发起端与服务端的会话,使主机在启动后即可使用通过 iSCSI 提供服务的存储设备。
iscsid 进程实现 iSCSI 协议的控制路径以及相关管理功能。例如守护进程(iscsid)可配置为在系统启动时基于持久化的 iSCSI 数据库内容,自动重新开始发现(discovery)目标设备。
Open-iSCSI 是通过以下 iSCSI 数据库文件来实现永久配置的:
- Discovery:
/var/lib/iscsi/send_targets目录下包含iSCSI portals的配置信息,每个portal对应一个文件,文件名为iSCSI portal IP,端口号(例如172.29.88.61,3260)
- Node:
/var/lib/iscsi/nodes目录下生成一个或多个以iSCSI存储服务器上的Target名命名的文件夹如iqn.2000-01.com.synology:themain-3rd.ittest,在该文件夹下有一个文件名为iSCSI portal IP,端口号,编号(例如172.29.88.62,3260,0)的配置参数文件default,该文件中是initiator登录target时要使用的参数,这些参数的设置是从/etc/iscsi/iscsi.conf中的参数设置继承而来的,可以通过iscsiadm对某一个参数文件进行更改(需要先注销到target的登录)
iscsiadm 是用来管理(更新、删除、插入、查询)iSCSI 配置数据库文件的命令行工具,用户能够用它对 iSCSI nodes、sessions、connections 和 discovery records 进行一系列的操作。
iSCSI node 是一个在网络上可用的 SCSI 设备标识符,在 Open-iSCSI 中利用术语 node 表示目标(target)上的门户(portal)。一个 target 可以有多个 portal,portal 由 IP 地址和端口构成。
iSCSI常见命令
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
chkconfig --list | grep iscsi
# 查看服务端配置文件
cat /etc/iscsi/initiatorname.iscsi
# 查看客户端配置文件
cat /etc/iscsi/iscsid.conf
# 通过sendtargets的方式发现iqn iscsi qualified name
iscsiadm -m discovery -t sendtargets -p 192.168.183.129
# 发现目标后,可以登录到相应的节点,使用目标设备提供的存储空间
iscsiadm -m node -T iqn.2001-04.com.example:storage.lun1 -p 192.168.183.129:3260 --login
# 登录节点成功后就建立了initiator和target之间的session
iscsiadm -m session
iscsiadm -m session -P 3
iscsiadm -m node -T iqn.2001-04.com.example:storage.lun2 -p 192.168.183.129:3260 --op update -n node.startup
iscsiadm -m session --rescan
ls -l /dev/disk/by-path/
# 列出所有target
iscsiadm -m node
# 连接所有target
iscsiadm -m node -L all
# 连接指定target
iscsiadm -m node -T iqn.... -p 172.29.88.62 --login
# 使用如下命令可以查看配置信息
iscsiadm -m node -o show -T iqn.2000-01.com.synology:rackstation.exservice-bak
# 查看目前iSCSI target连接状态
iscsiadm -m session
iscsiadm: No active sessions. # 目前没有已连接的iSCSI target
# 断开所有target
iscsiadm -m node -U all
# 断开指定target
iscsiadm -m node -T iqn... -p 172.29.88.62 --logout
iscsiadm -m node -T iqn.2022-06.com.xsky:xedp-szglbd-cluster-01.iscsi.3.144a5c3fee265f94 -p 10.9.19.132 --logout
# 删除所有node信息
iscsiadm -m node --op delete
# 删除指定节点(/var/lib/iscsi/nodes目录下,先断开session)
iscsiadm -m node -o delete -name iqn.2022-06.com.xsky:xedp-szglbd-cluster-01.iscsi.3.144a5c3fee265f94
# 删除一个目标(/var/lib/iscsi/send_targets目录下)
iscsiadm --mode discovery -o delete -p 172.29.88.62:3260
|
Longhorn组件分析
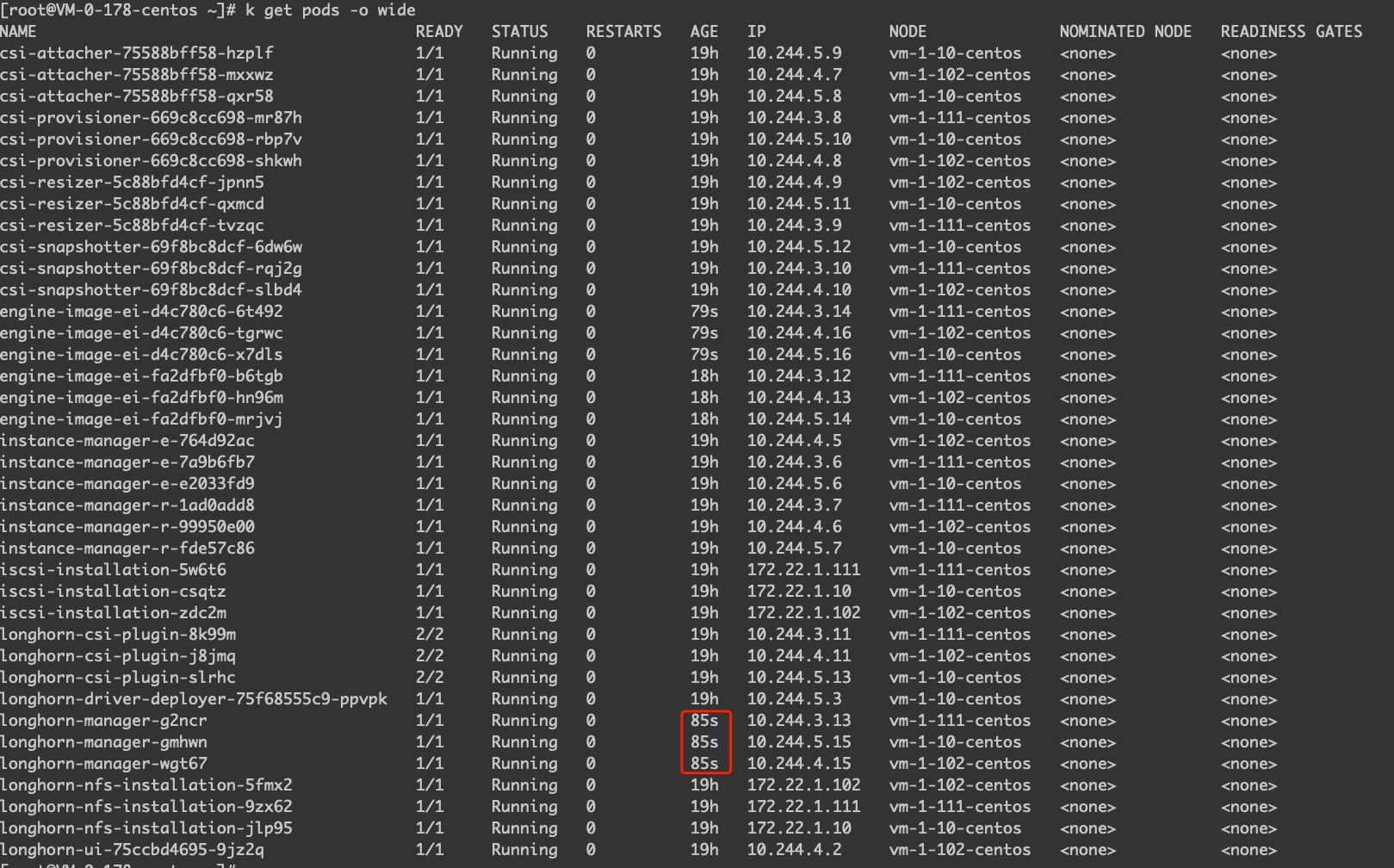
Longhorn 的原理本身可能没有很复杂,但是很多人看起来会觉得很难看懂,这就不得不说 Longhorn 糟糕的组件命名了…Longhorn 部署完之后主要关注两种类型的工作负载,分别是 Deployment 和 DaemonSet。其中 Deployment 中的 csi 开头的工作负载大部分都是 CSI 插件必须安装的组件,跟 CSI 类型关系不大,主要就是 DaemonSet 中的 longhorn-csi-plugin 和 longhorn-manager。
1
2
3
4
5
6
7
8
9
10
11
12
13
|
# k get deployment
NAME READY UP-TO-DATE AVAILABLE AGE
csi-attacher 3/3 3 3 18h
csi-provisioner 3/3 3 3 18h
csi-resizer 3/3 3 3 18h
csi-snapshotter 3/3 3 3 18h
longhorn-driver-deployer 1/1 1 1 18h
longhorn-ui 1/1 1 1 18h
# k get ds
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
engine-image-ei-fa2dfbf0 3 3 3 3 3 <none> 17h
longhorn-csi-plugin 3 3 3 3 3 <none> 18h
longhorn-manager 3 3 3 3 3 <none> 18h
|
Longhorn Manager
Longhorn Manager 这个组件是 Longhorn 的核心组件,里面包含大部分的控制器 controller 逻辑,并且还会提供 metrics 指标的接口,包括以下:
- backing_image_controller.go
- backing_image_data_source_controller.go
- backing_image_manager_controller.go
- backup_controller.go
- backup_target_controller.go
- backup_volume_controller.go
- base_controller.go
- controller_manager.go
- engine_controller.go
- engine_image_controller.go
- instance_manager_controller.go
- kubernetes_configmap_controller.go
- kubernetes_node_controller.go
- kubernetes_pod_controller.go
- kubernetes_pv_controller.go
- kubernetes_pv_controller_test.go
- kubernetes_secret_controller.go
- node_controller.go
- orphan_controller.go
- recurring_job_controller.go
- replica_controller.go
- setting_controller.go
- share_manager_controller.go
- snapshot_controller.go
- uninstall_controller.go
- volume_controller.go
- websocket_controller.go
为什么会说 Longhorn 是基于微服务做的存储呢,个人是这样理解的,比如 instance-manager 在 Longhorn 的角色是一个存储引擎以及副本的控制器,为什么叫控制器?因为 instance-manager 会决定客户端连接的是哪一个存储副本,当连接的副本出现问题的时候,instance-manager 又会帮助客户端 failedover 到另一个副本,所以这样理解成控制器就没什么毛病了。
针对每一个节点,Longhorn Manager 都会创建出两个组件,分别是 instance-manager-e 和 instance-manager-r,一个是存储引擎/控制器 一个是管理独立副本的服务,下面是部署结果。
1
2
3
4
5
6
|
instance-manager-e-0e09acc9 1/1 Running 9h 10.244.5.4 vm-1-169-centos
instance-manager-e-3aabe1ed 1/1 Running 9h 10.244.4.4 vm-0-141-centos
instance-manager-e-8286ca60 1/1 Running 9h 10.244.3.5 vm-0-99-centos
instance-manager-r-899af4e4 1/1 Running 9h 10.244.5.6 vm-1-169-centos
instance-manager-r-d589a65f 1/1 Running 9h 10.244.4.5 vm-0-141-centos
instance-manager-r-e049b2b7 1/1 Running 9h 10.244.3.6 vm-0-99-centos
|
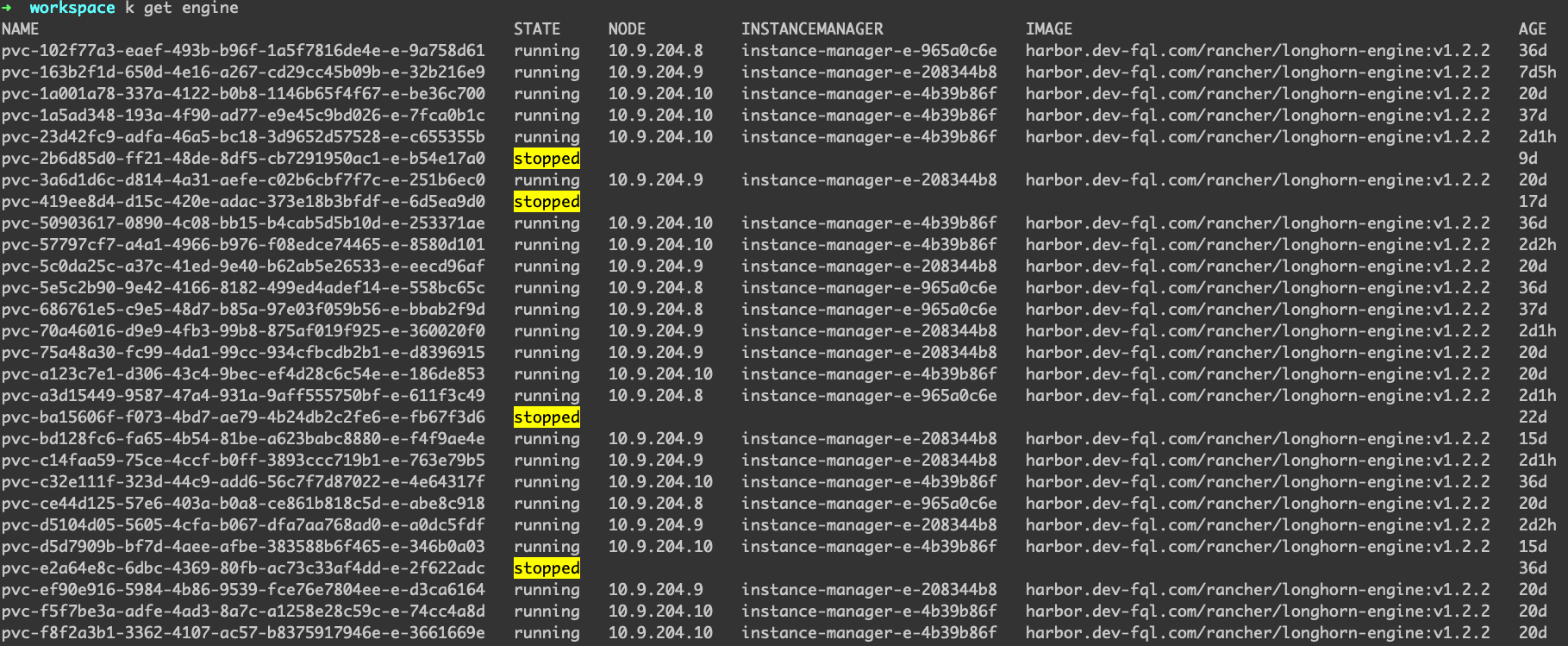
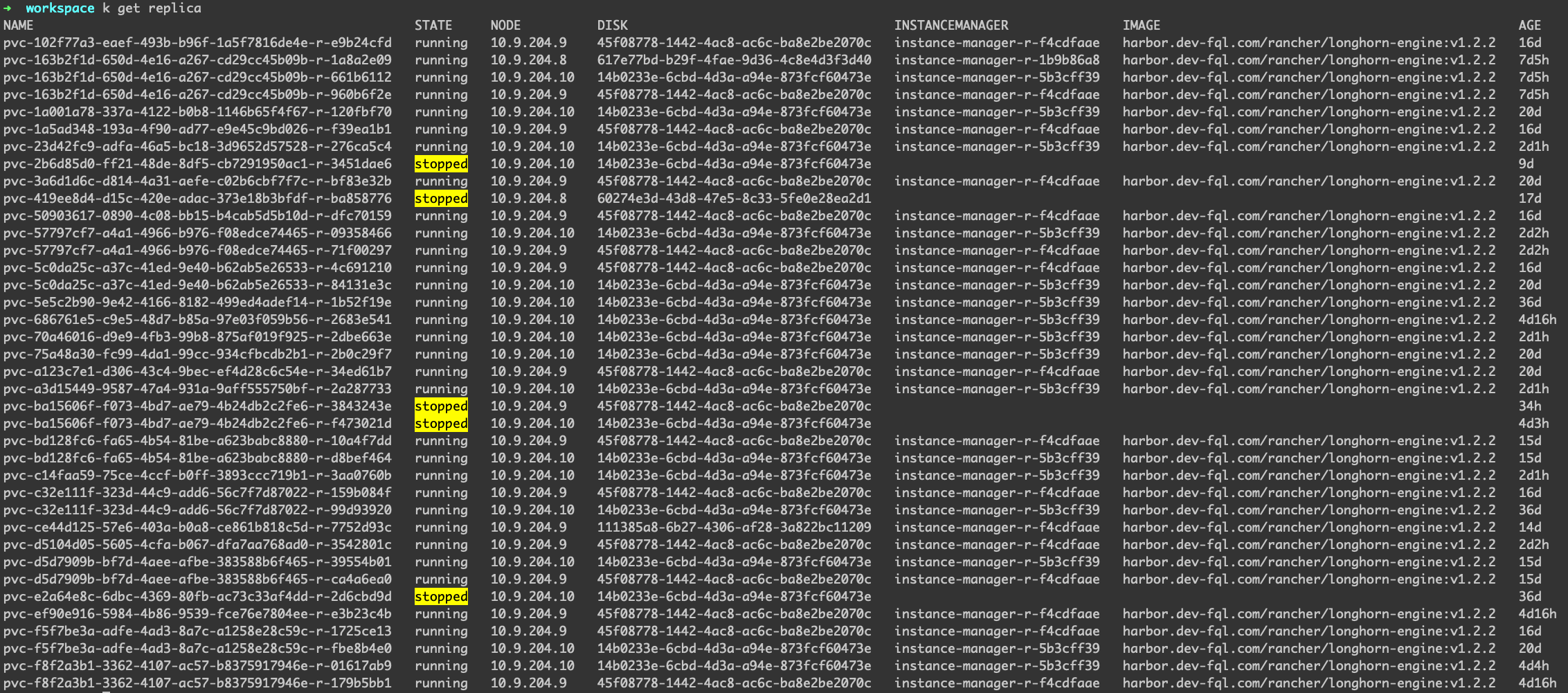
举个例子,为什么engine会有stopped的状态呢,可以理解成Volume处于detach的状态,因此不需要engine一直处于运行的状态

replica的数目肯定是大于等于engine的数量的,对于engine已经stopped的replica,其状态一定是stopped
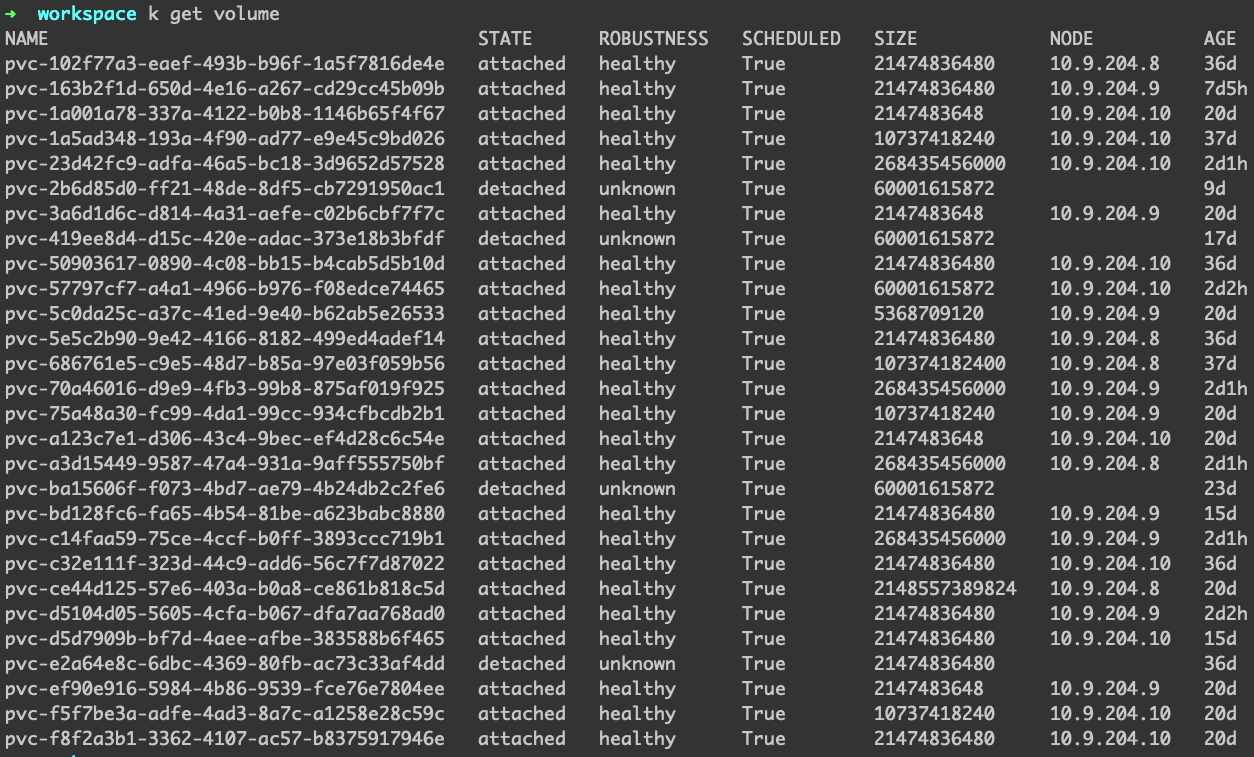
下面是正常volume的状态
命名的规则是这样的,假设创建出来的 PV 叫做 pvc-f5f7be3a-adfe-4ad3-8a7c-a1258e28c59c,那么 Volume 也是叫做 pvc-f5f7be3a-adfe-4ad3-8a7c-a1258e28c59c,然后管理这个 Volume 的 Engine 叫做 pvc-f5f7be3a-adfe-4ad3-8a7c-a1258e28c59c-e-xxxxxx,对应这个 Volume 的 Replica 叫做 pvc-f5f7be3a-adfe-4ad3-8a7c-a1258e28c59c-r-xxxxxx。
下面是 Longhorn 创建的一些自定义资源。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
backingimagedatasources.longhorn.io 2022-08-09T05:56:29Z
backingimagemanagers.longhorn.io 2022-08-09T05:56:29Z
backingimages.longhorn.io 2022-08-09T05:56:29Z
backups.longhorn.io 2022-08-09T05:56:29Z
backuptargets.longhorn.io 2022-08-09T05:56:29Z
backupvolumes.longhorn.io 2022-08-09T05:56:29Z
engineimages.longhorn.io 2022-08-09T05:56:29Z
engines.longhorn.io 2022-08-09T05:56:29Z
instancemanagers.longhorn.io 2022-08-09T05:56:29Z
nodes.longhorn.io 2022-08-09T05:56:29Z
recurringjobs.longhorn.io 2022-08-09T05:56:29Z
replicas.longhorn.io 2022-08-09T05:56:29Z
settings.longhorn.io 2022-08-09T05:56:29Z
sharemanagers.longhorn.io 2022-08-09T05:56:29Z
volumes.longhorn.io 2022-08-09T05:56:29Z
|
Longhorn Manager 会以 DaemonSet 部署,是一个集很多控制器在一身的服务。下面是启动的命令,可以看到需要在命令中指定 engine-image,instance-manager-image 等镜像,因此 engine/replica 实际上可以单独升级,主要更新镜像即可。下面是 Longhorn Manager 的 DaemonSet 部署的时候的命令和参数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
|
# k get ds longhorn-manager -o yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: longhorn-manager
spec:
template:
spec:
containers:
- command:
# 从启动的命令行参数可以看到很多关于镜像的设置
- longhorn-manager
- -d
- daemon
- --engine-image
- longhornio/longhorn-engine:v1.2.2
- --instance-manager-image
- longhornio/longhorn-instance-manager:v1_20210731
- --share-manager-image
- longhornio/longhorn-share-manager:v1_20210914
- --backing-image-manager-image
- longhornio/backing-image-manager:v2_20210820
- --manager-image
- longhornio/longhorn-manager:v1.2.2
- --service-account
- longhorn-service-account
env:
- name: DEFAULT_SETTING_PATH
value: /var/lib/longhorn-setting/default-setting.yaml
image: longhornio/longhorn-manager:v1.2.2
name: longhorn-manager
ports:
- containerPort: 9500
name: manager
protocol: TCP
volumeMounts:
- mountPath: /host/dev/
name: dev
- mountPath: /host/proc/
name: proc
- mountPath: /var/lib/longhorn/
mountPropagation: Bidirectional
name: longhorn
- mountPath: /var/lib/longhorn-setting/
name: longhorn-default-setting
volumes:
- hostPath:
path: /dev/
type: ""
name: dev
- hostPath:
path: /proc/
type: ""
name: proc
- hostPath:
path: /var/lib/longhorn/
type: ""
name: longhorn
- configMap:
defaultMode: 420
name: longhorn-default-setting
name: longhorn-default-setting
|
可以想象,如果单纯重启 Longhorn Manager 的 Pod,是不会引起 engine/replica 的重启的,因为 Longhorn Manager 只是管理 engine/replica 组件的控制器,只会 Sync/Reconcile 他们的状态,以确保他们突然没有了,可以重新拉起,下面是测试的例子:
Longhorn Engine
Longhorn Engine implements a lightweight block device storage controller capable of storing the data in a number of replicas. It functions like a network RAID controller.
Longhorn Engine 说的也很清楚,他就是实际管理存储的,可以说是 Longhorn 数据存储里最核心的组件。在 Longhorn 的部署架构中,会以单个 Pod instance-manager-e 出现。
下面看一下 instance-manager-e 这种类型的 Pod 的定义。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
|
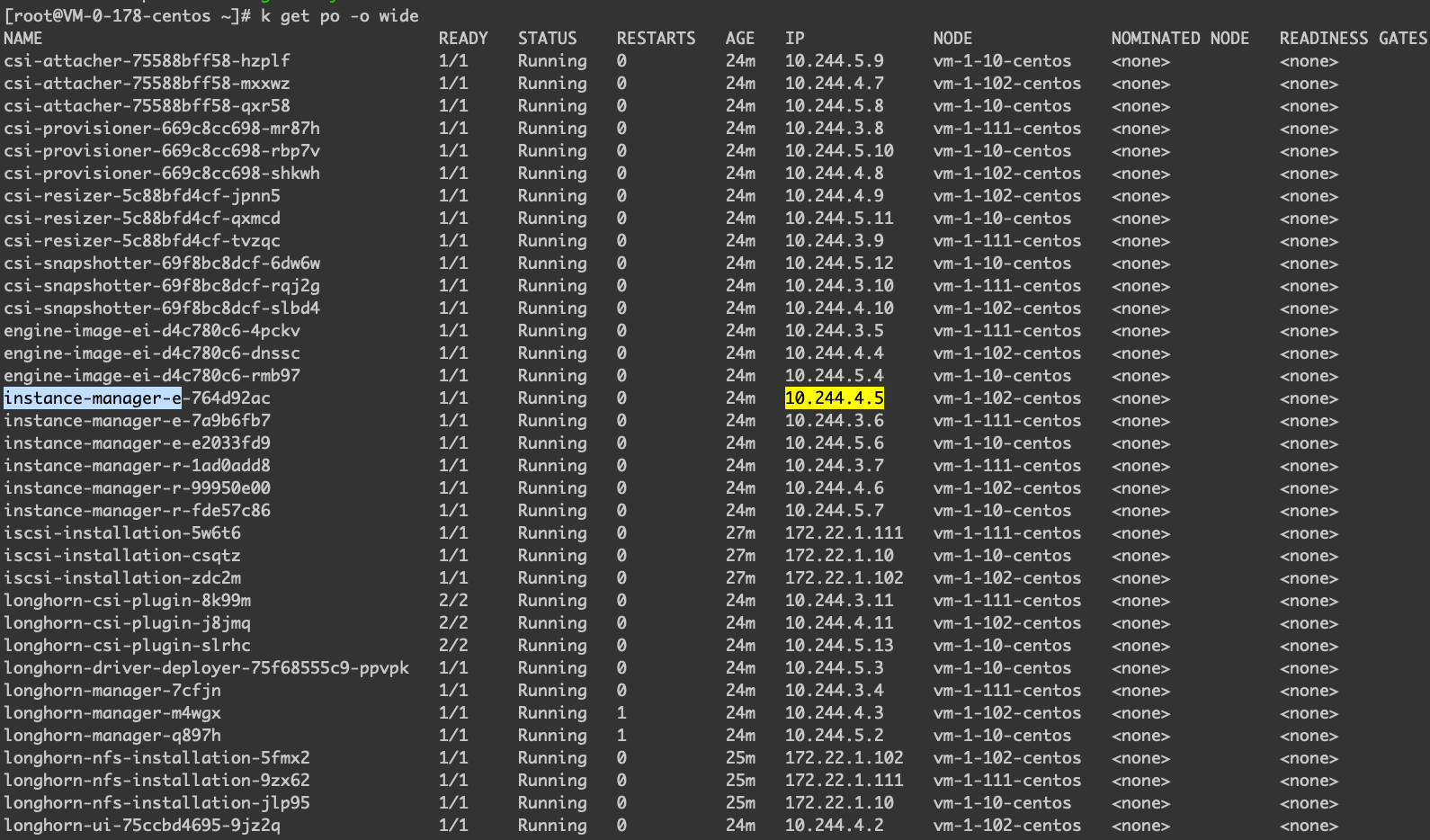
# k get pods instance-manager-e-764d92ac -o yaml
# 删除了一些不重要的字段
apiVersion: v1
kind: Pod
metadata:
labels:
longhorn.io/component: instance-manager
longhorn.io/instance-manager-image: imi-95c270a2
longhorn.io/instance-manager-type: engine
# 从这里可以看出这个Pod是由longhorn-manager管理的
longhorn.io/managed-by: longhorn-manager
longhorn.io/node: vm-1-102-centos
name: instance-manager-e-764d92ac
namespace: longhorn-system
ownerReferences:
- apiVersion: longhorn.io/v1beta1
blockOwnerDeletion: true
controller: true
kind: InstanceManager
name: instance-manager-e-764d92ac
spec:
containers:
- args:
- engine-manager
- --debug
- daemon
- --listen
- 0.0.0.0:8500
image: longhornio/longhorn-instance-manager:v1_20210731
name: engine-manager
volumeMounts:
- mountPath: /host/dev
name: dev
- mountPath: /host/proc
name: proc
- mountPath: /engine-binaries/
mountPropagation: HostToContainer
name: engine-binaries
restartPolicy: Never
volumes:
# 挂载了很多母机上的中重要目录
- hostPath:
path: /dev
type: ""
name: dev
- hostPath:
path: /proc
type: ""
name: proc
- hostPath:
path: /var/lib/longhorn/engine-binaries/
type: ""
name: engine-binaries
|
instance-manager-e 内部有 TGT 进程,是拿了做 target 使用的,一个 engine 一个 TGT 进程,代表一个设备,后面会跟 --replica 代表的是副本服务的地址,这里就体现出了 Longhorn 微服务的设计思想。
1
2
3
4
5
6
|
# engine发起的命令,连接这两个副本
/engine-binaries/longhornio-longhorn-engine-v1.2.2/longhorn controller pvc-b26d4575-2e1f-4d2c-a3f7-95a9383ad7b9 \
--frontend tgt-blockdev \
--replica tcp://10.244.3.8:10015 \
--replica tcp://10.244.5.8:10030 \
--listen 0.0.0.0:10000
|
Longhorn Instance Manager
Longhorn Instance Manager manages the engine and replica instances on the node.
Longhorn Instance Manager 说的很清楚了,他是负责管理 engine/replica 实例的组件,他实际是一个 cli 工具。在 Longhorn 的部署中,会以单个 Pod 出现 instance-manager-r。下面看一下 instance-manager-r 这种类型的 Pod 的定义。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
# # k get pods instance-manager-r-99950e00 -o yaml
apiVersion: v1
kind: Pod
metadata:
labels:
longhorn.io/component: instance-manager
longhorn.io/instance-manager-image: imi-95c270a2
longhorn.io/instance-manager-type: replica
longhorn.io/managed-by: longhorn-manager
longhorn.io/node: vm-1-102-centos
name: instance-manager-r-99950e00
namespace: longhorn-system
ownerReferences:
- apiVersion: longhorn.io/v1beta1
blockOwnerDeletion: true
controller: true
kind: InstanceManager
name: instance-manager-r-99950e00
spec:
containers:
- args:
- longhorn-instance-manager
- --debug
- daemon
- --listen
- 0.0.0.0:8500
image: longhornio/longhorn-instance-manager:v1_20210731
name: replica-manager
volumeMounts:
- mountPath: /host
mountPropagation: HostToContainer
name: host
restartPolicy: Never
volumes:
- hostPath:
path: /
type: ""
name: host
|
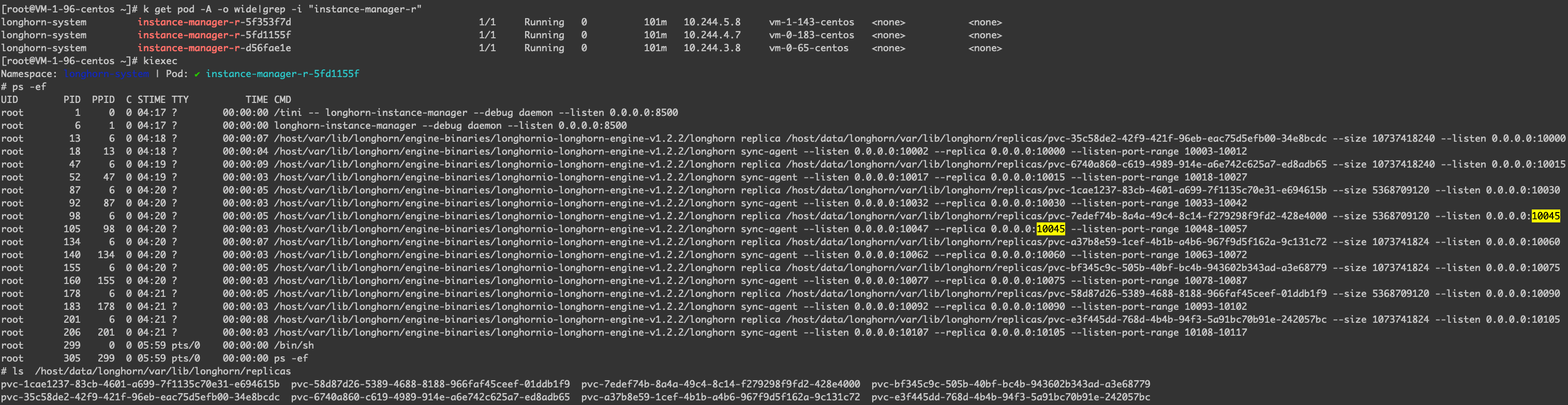
instance-manager-r 的 Pod 中主要有副本和副本同步的进程,可以想象,如果卷只有一个副本,那么就不会有同步的那个进程,并且可以预计到,这个 instance-manager-r Pod 会挂载到宿主机的文件目录,也就是 /host/data/longhorn/var/lib/longhorn/replicas,这里面可以读到该节点管理的卷的副本的块文件。
1
2
3
4
5
6
7
8
9
10
11
|
# 代表一个副本服务
/host/var/lib/longhorn/engine-binaries/longhornio-longhorn-engine-v1.2.2/longhorn replica \
/host/data/longhorn/var/lib/longhorn/replicas/pvc-7edef74b-8a4a-49c4-8c14-f279298f9fd2-428e4000 \
--size 5368709120 \
--listen 0.0.0.0:10045
# 代表副本服务之间数据同步的服务
/host/var/lib/longhorn/engine-binaries/longhornio-longhorn-engine-v1.2.2/longhorn sync-agent \
--listen 0.0.0.0:10047 \
--replica 0.0.0.0:10045 \
--listen-port-range 10048-10057
|
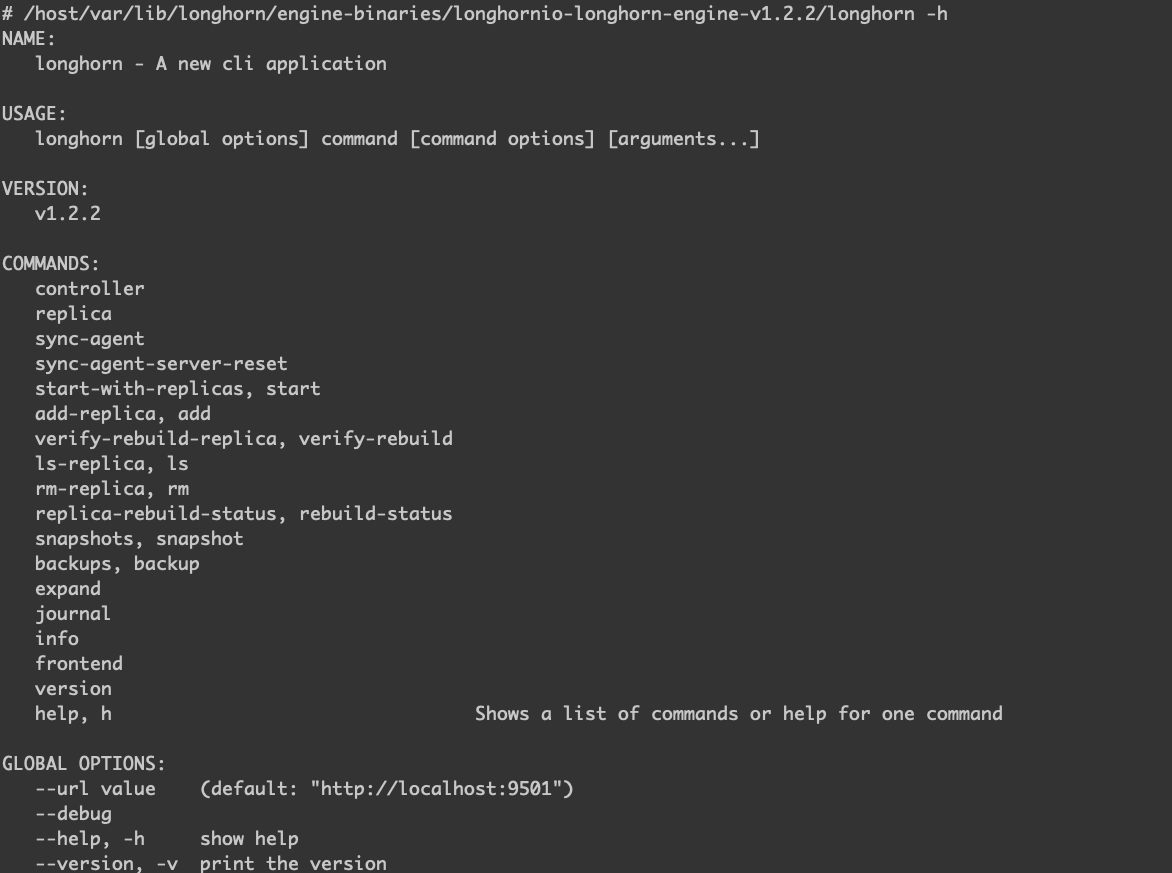
进一步看看 /host/var/lib/longhorn/engine-binaries/longhornio-longhorn-engine-v1.2.2/longhorn 这个 cli 能做些什么。
都是由 Longhorn Manager 负责管理,简单比较一下 instance-manager-e 和 instance-manager-r 的区别。
go-iscsi-helper
这个库也是由 Longhorn 团队提供的,可以理解成 Longhorn 要使用 iSCSI 主要是调用的这个库,这个库封装的就是系统的 iscsiadm 相关的命令,所以如果你要使用 Longhorn 的卷,是不是一定要通过 Longhorn 呢?其实也不一定,如果你对这个库以及对 iSCSI 比较熟悉,手动就可以挂载。下面是具体的例子:
Longhorn测试
创建一个 Pod,并且根据 iSCSI 以及 Longhorn 的原理查看一下这些软件会在主机上怎么创建以及部署。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: task-pv-claim
spec:
storageClassName: longhorn
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
---
apiVersion: v1
kind: Pod
metadata:
name: task-pv-pod
spec:
volumes:
- name: task-pv-storage
persistentVolumeClaim:
claimName: task-pv-claim
containers:
- name: task-pv-container
image: nginx
ports:
- containerPort: 80
name: "http-server"
volumeMounts:
- mountPath: "/usr/share/nginx/html"
name: task-pv-storage
EOF
|
创建 Pod 在以下的节点。
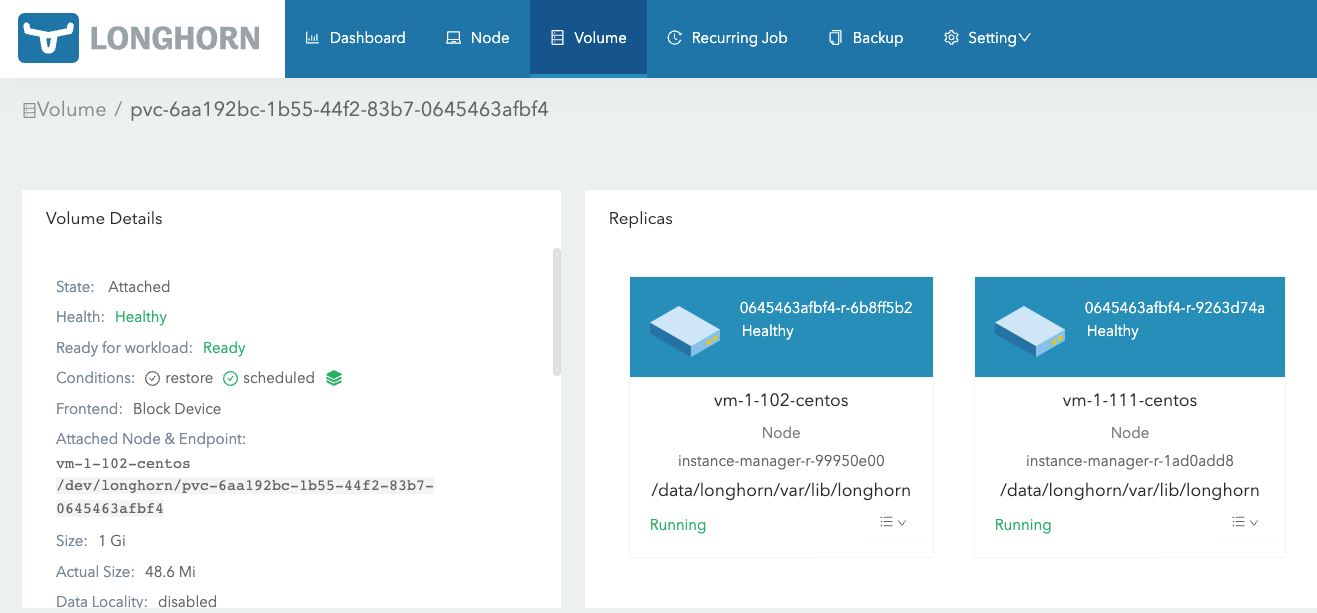
创建出的存储在 Longhorn 上的卷的显示。
两个副本所在节点的文件目录和内容。
查看 /var/lib/iscsi 目录。
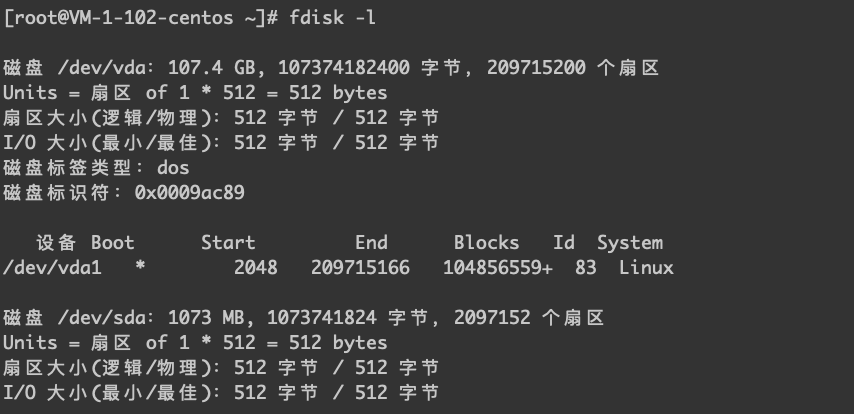
通过 fdsik -l 查看设备。
可见 Pod 目前是调度在 vm-1-102-centos 这台机器上,从这台机器的几个命令确认,卷是 mount 到这个节点。
进入目录可以看到初始化后的文件系统的内容。
可以知道目前这个 Pod 所使用的副本就是该 Pod 所在节点上的存储空间。通过 iscsiadm 命令验证如下。
为什么上图会显示这个10.244.4.5这个 IP 呢,那是因为 instance-manager-e 运行在该节点,且其 Pod IP 是10.244.4.5。
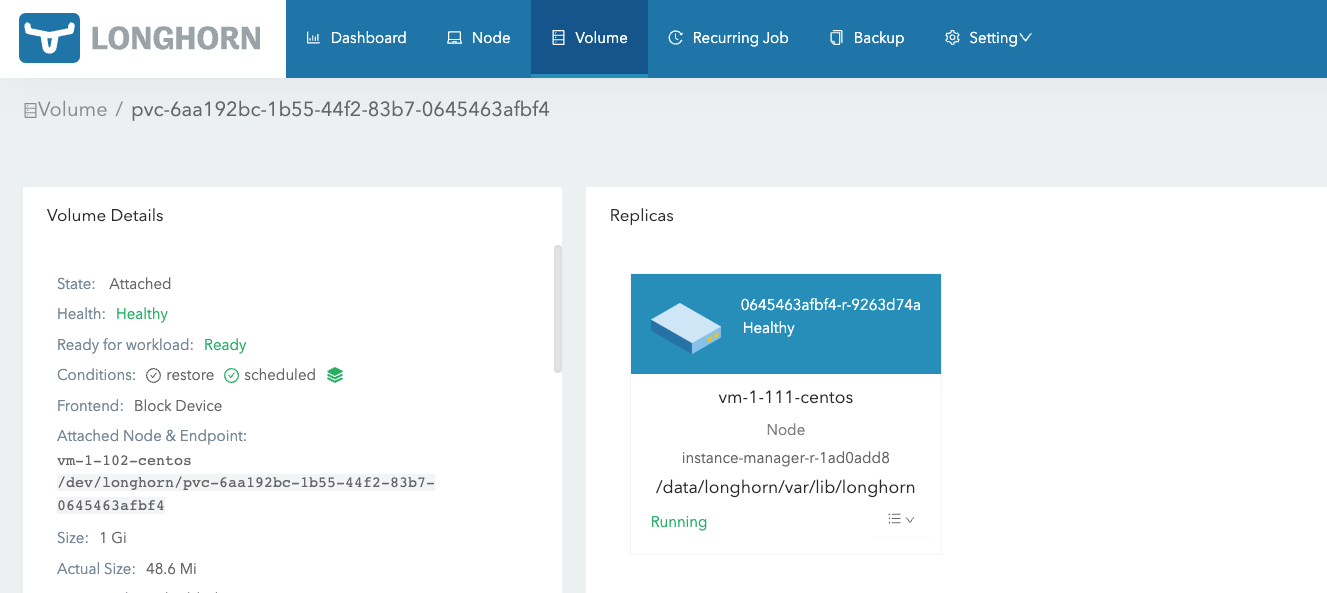
两个副本会在 instance-manager-r 的 Pod 里有体现,如下图,可以看到这个 Pod 里的进程除了有一个 replica 的进程,还会有一个 sync 的进程,负责两个 replica 之间的数据同步。
再查看 vm-1-111-centos 这个节点上的 instance-manager-e 和 instance-manager-r 内的进程。因为当前存储设备挂载到,所以可以明显看到 vm-1-111-centos 的 instance-manager-e 里的进程比 vm-1-102-centos 少了一个。
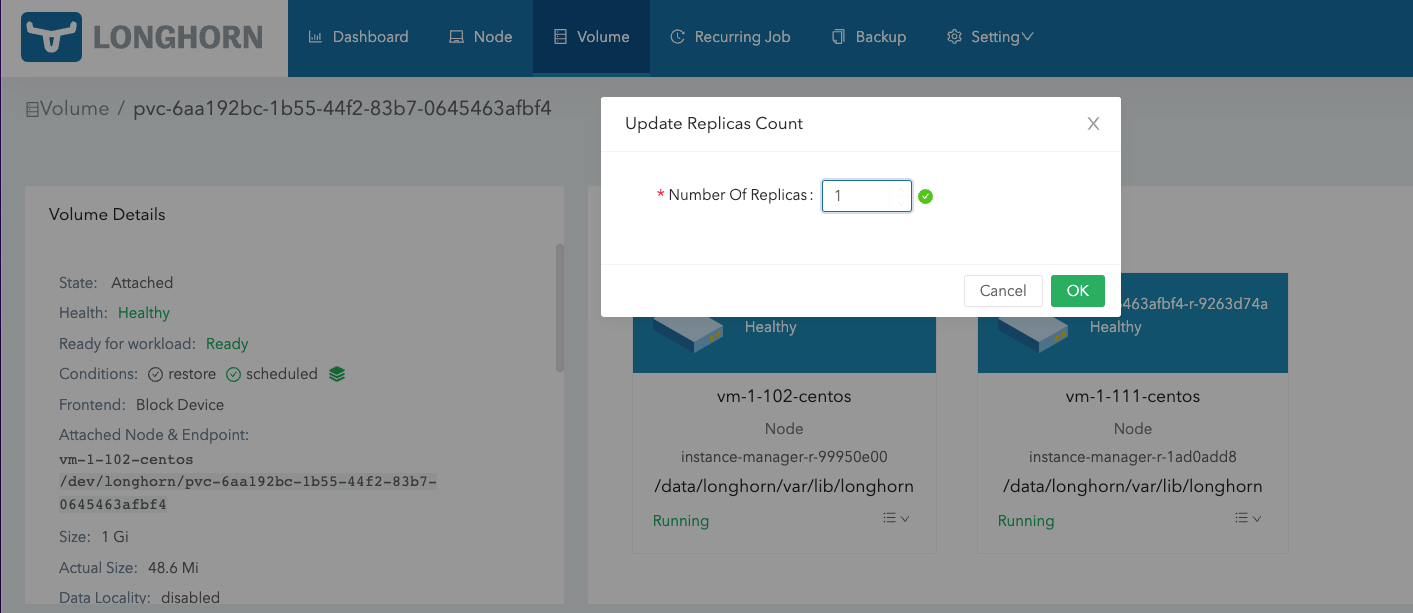
此时将默认副本数调整成1,然后删除 vm-1-102-centos 这个节点上的副本,会发现 vm-1-102-centos 这个节点上的目录没有了。
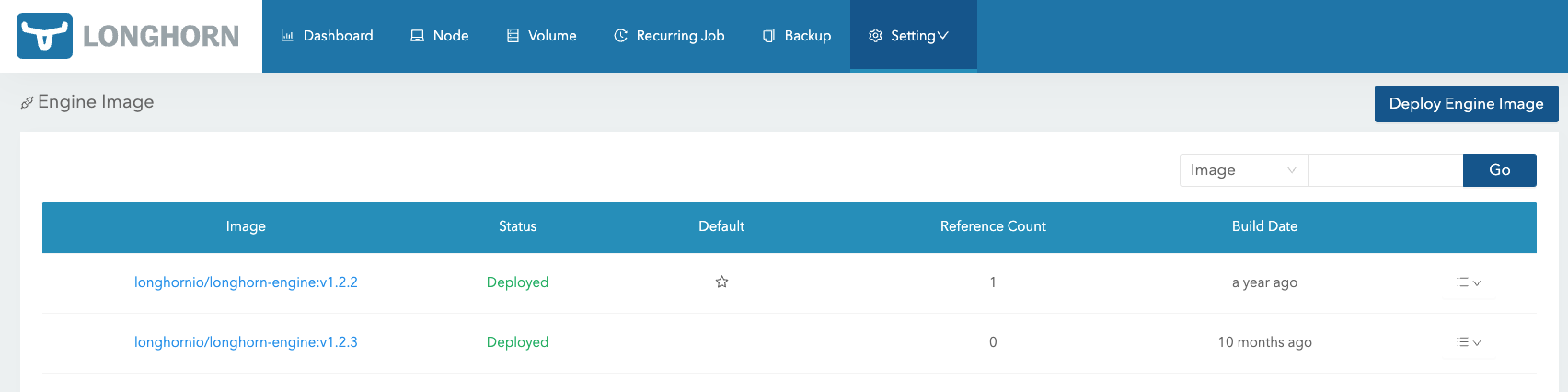
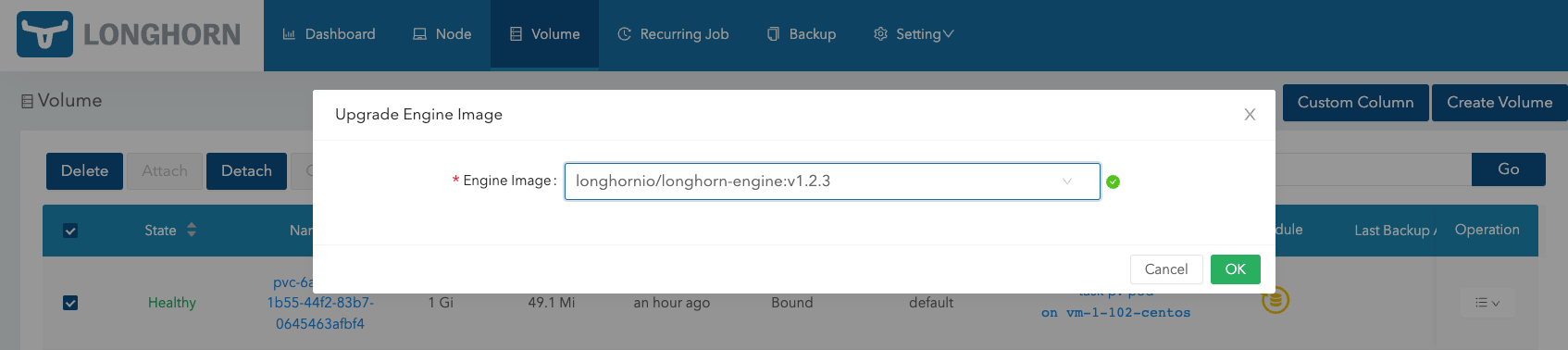
更新 Engine 的镜像,查看对网络存储是否有影响,新增 longhornio/longhorn-engine:v1.2.3 这个镜像。
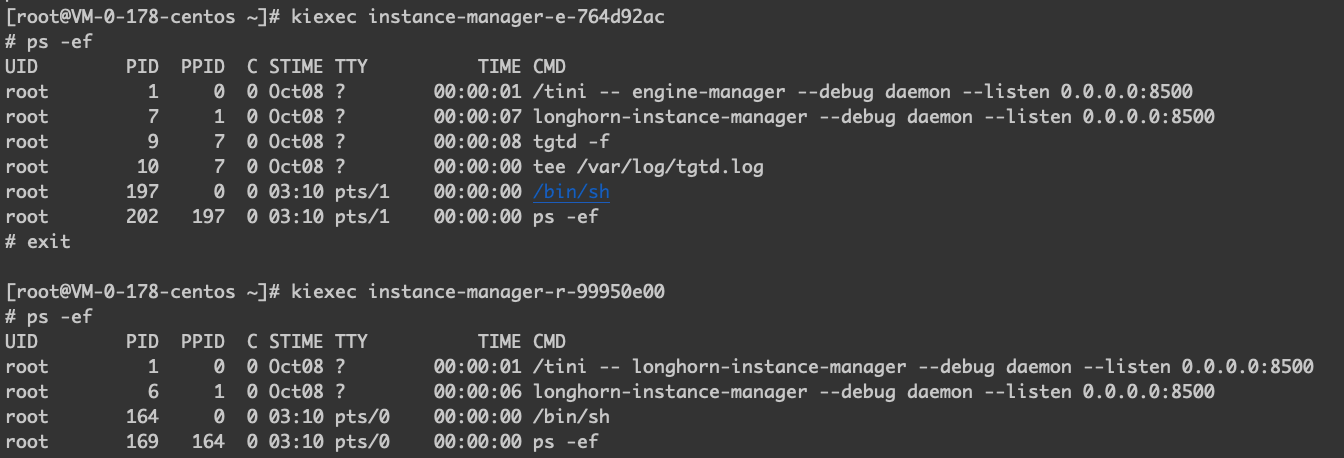
可以看到 instance-manager-e 和 instance-manager-r 内的进程是有重启的。
删除这个卷之后,查看一下 instance-manager-e 和 instance-manager-r 内的进程的变化。可以看到关于 replica 和 engine 的进程都停止了。
卷亲和性
1
|
FailedScheduling 0/8 nodes are available: 1 node(s) had taint {app: master}, that the pod didn't tolerate, 2 node(s) had taint {network: only}, that the pod didn't tolerate, 2 node(s) had taint {node-role.kubernetes.io/controlplane: true}, that the pod didn't tolerate, 3 node(s) had volume node affinity conflict.
|
节点亲和性: 每个PV卷可以通过设置节点亲和性来定义一些约束,进而限制从哪些节点上可以访问此卷。使用这些卷的Pod只会被调度到节点亲和性规则所选择的节点上执行。要设置节点亲和性,配置PV卷.spec中的nodeAffinity
配置文件清理
清理 iSCSI 相关的文件。Longhorn 的文档中,没有具体给出如何还原一个部署过 Longhorn 的节点的流程,这里主要涉及到 iSCSI 的配置文件,当涉及到节点频繁下架上架,甚至在重装之前,会先后加入到 Kubernetes 集群,如果这些配置文件得不到正常的清楚,将会导致后面安装的时候,会出现一些莫名其妙的问题,比如存在不熟悉的 target 名。
1
2
3
4
5
6
7
8
|
/etc/iscsi/iscsid.conf
The configuration file read by iscsid and iscsiadm on startup.
/etc/iscsi/initiatorname.iscsi
The file containing the iSCSI InitiatorName and InitiatorAlias read by iscsid and iscsiadm on startup.
/var/lib/iscsi/nodes/
This directory contains the nodes with their targets.
/var/lib/iscsi/send_targets
This directory contains the portals.
|
1
2
3
4
|
# 删除iSCSI软件
yum autoremove -y iscsi-initiator-utils
# 确保删除配置文件
rm -rf /var/lib/iscsi/send_targets /var/lib/iscsi/nodes/ /etc/iscsi/initiatorname.iscsi /etc/iscsi/iscsid.conf
|
参考资料
- iSCSI网络存储介绍及客户端配置操作
- Linux下搭建iSCSI共享存储的方法TGT方式CentOS6.9系统下
- Linux上Open-iSCSI的安装,配置和使用
警告
本文最后更新于 2022年11月9日,文中内容可能已过时,请谨慎参考。