概述
目前主要关注 PPO 训练的部分,下面大致介绍一下,如何通过 LET(LLaMA Efficient Tuning) 在 LLM 平台运行基于 Baichuan2-13B-Chat 的 PPO 训练,用户可以基于下面的例子,通过修改对应的脚本,在 LLM 平台进行大模型的 PPO 训练。
首先需要一个 RM 模型,一般来说,采用 Lora 的方式,RM 一个 13B 的模型,单卡就足够,注意 output_dir 输出的路径,用户可以自定义成 CephFS 的一个持久化目录。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py \
--stage rm \
--model_name_or_path /apps/dat/file/llm/model/Baichuan2-13B-Chat \
--do_train True \
--overwrite_cache True \
--finetuning_type lora \
--template baichuan \
--dataset_dir data \
--dataset oaast_rm_zh \
--max_source_length 512 \
--max_target_length 512 \
--learning_rate 5e-05 \
--num_train_epochs 1.0 \
--max_samples 1000 \
--per_device_train_batch_size 4 \
--gradient_accumulation_steps 4 \
--lr_scheduler_type cosine \
--max_grad_norm 1.0 \
--logging_steps 5 \
--save_steps 100 \
--warmup_steps 0 \
--padding_side left \
--lora_rank 8 \
--lora_dropout 0.1 \
--lora_target W_pack \
--resume_lora_training False \
--output_dir /apps/dat/training/LLaMA-Efficient-Tuning/rm/saves/$(date +'%Y/%m/%d/%H/%M/') \
--fp16 True \
--plot_loss True
|
然后再进行 PPO,注意因为需要加载 SFT 的模型和 RM 的模型,对于两个 13B 的模型,单卡就放不下了,所以请使用 deepspeed 的方式启动,需要单机8卡的配置,注意这里 reward_model 是指向了平台提前训练好的一个 RM 模型,用户如果有自己的 RM 模型,请自行切换这个参数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
|
cat > ds_config.json <<"EOF"
{
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"gradient_accumulation_steps": "auto",
"gradient_clipping": "auto",
"zero_allow_untested_optimizer": true,
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"initial_scale_power": 16,
"loss_scale_window": 1000,
"hysteresis": 2,
"min_loss_scale": 1
},
"zero_optimization": {
"stage": 2,
"allgather_partitions": true,
"allgather_bucket_size": 5e8,
"reduce_scatter": true,
"reduce_bucket_size": 5e8,
"overlap_comm": false,
"contiguous_gradients": true
}
}
EOF
deepspeed --num_gpus 8 --master_port=9901 src/train_bash.py \
--deepspeed ds_config.json \
--stage ppo \
--model_name_or_path /apps/dat/file/llm/model/Baichuan2-13B-Chat \
--reward_model /apps/dat/training/LLaMA-Efficient-Tuning/rm/saves/2023/09/22/16/28/ \
--do_train True \
--overwrite_cache True \
--finetuning_type lora \
--template baichuan \
--dataset_dir data \
--dataset oaast_sft_zh \
--max_source_length 512 \
--max_target_length 512 \
--learning_rate 5e-05 \
--num_train_epochs 1.0 \
--max_samples 100000 \
--per_device_train_batch_size 1 \
--gradient_accumulation_steps 1 \
--lr_scheduler_type cosine \
--max_grad_norm 1.0 \
--logging_steps 5 \
--save_steps 100 \
--warmup_steps 0 \
--padding_side left \
--lora_rank 8 \
--lora_dropout 0.1 \
--lora_target W_pack \
--resume_lora_training False \
--output_dir /apps/dat/training/LLaMA-Efficient-Tuning/ppo/saves/$(date +'%Y/%m/%d/%H/%M/') \
--bf16 True \
--plot_loss True
|
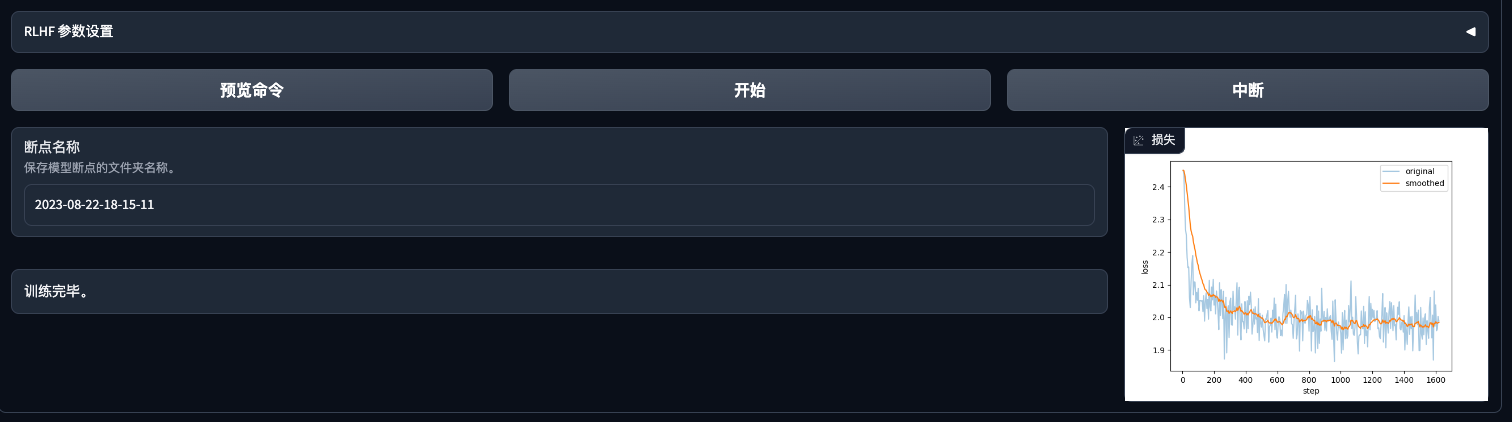
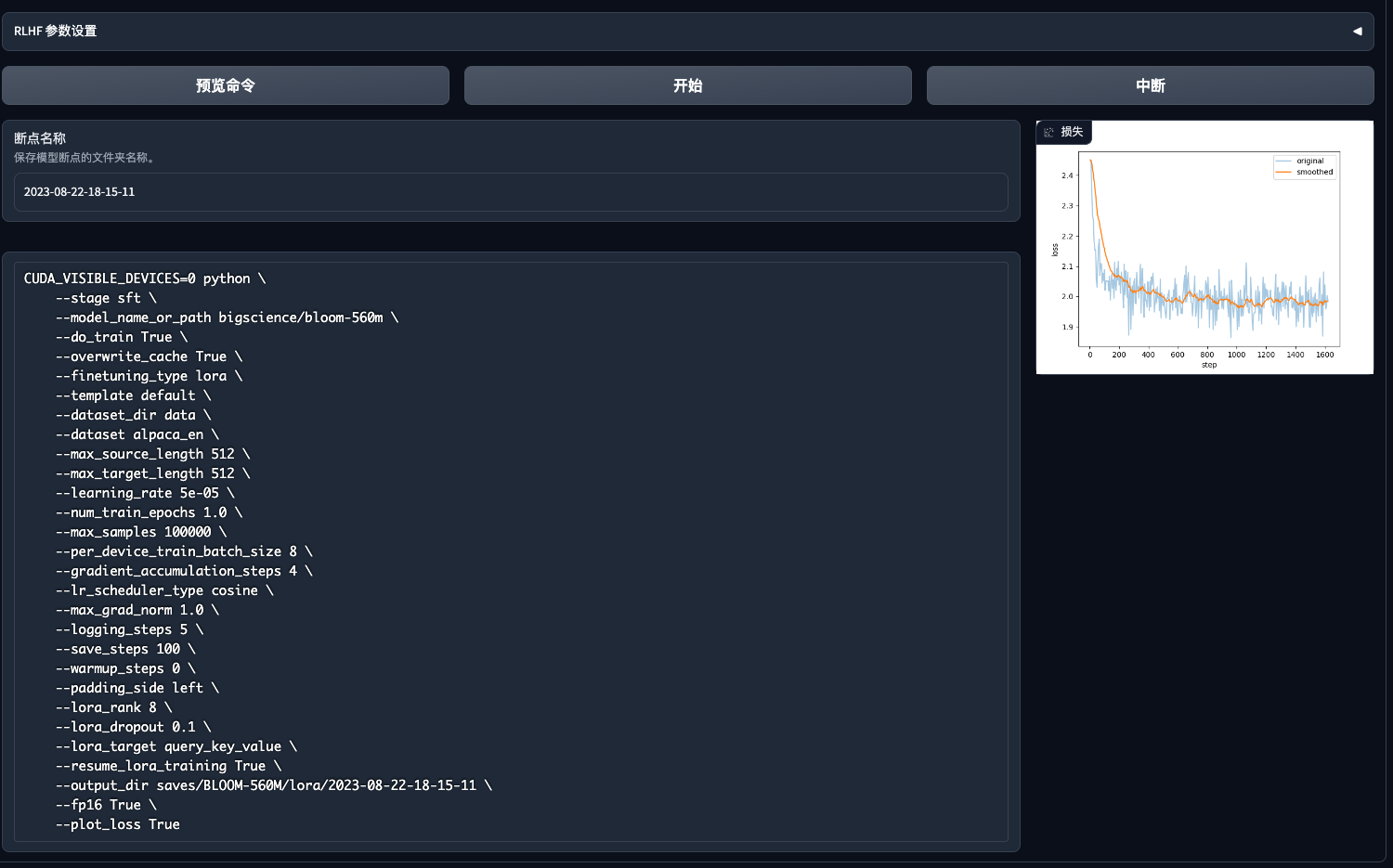
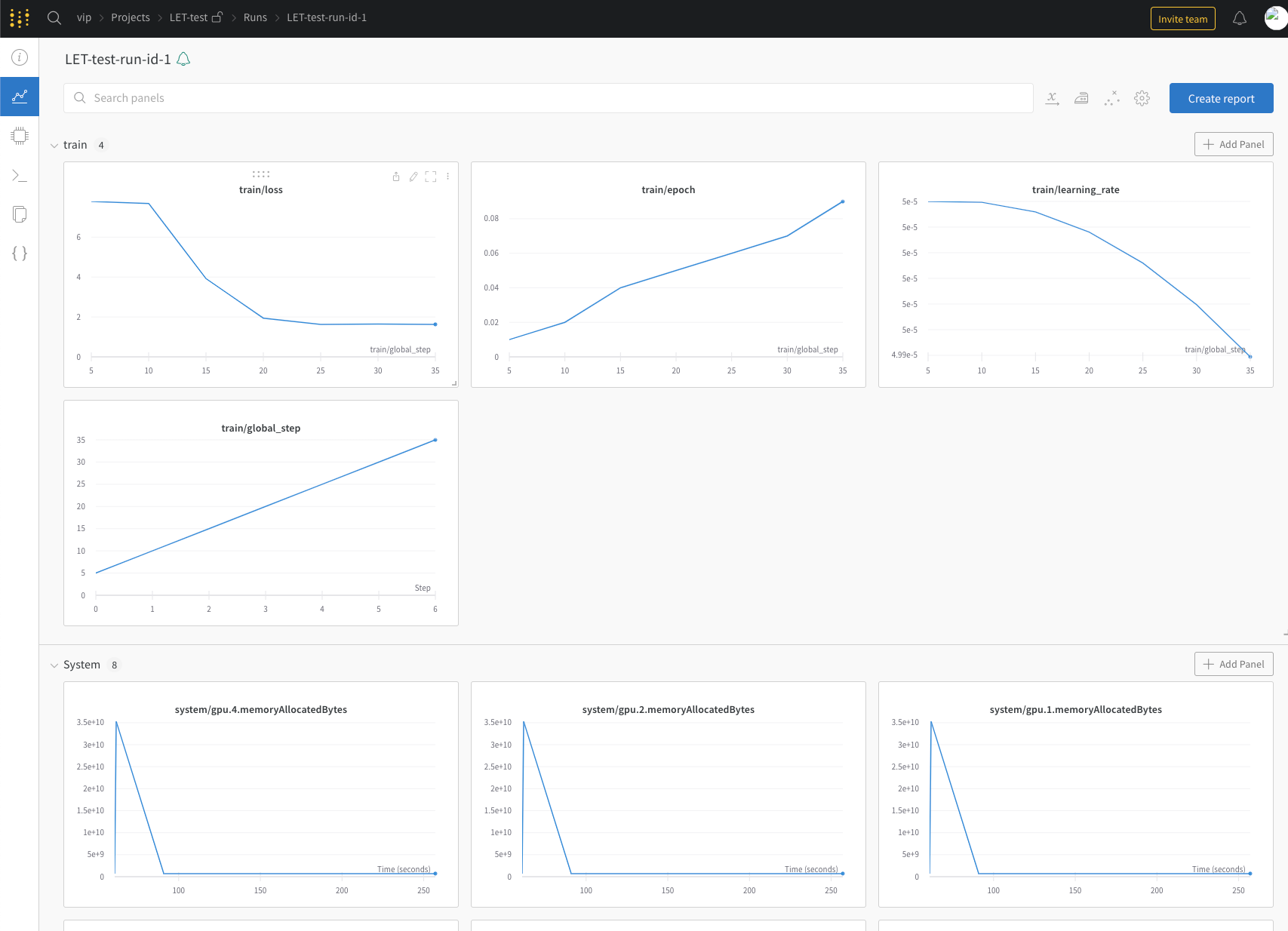
plot_loss 另外这个参数会打印 loss 的折线图,训练中,可以通过 Notebook 查看 /apps/dat/training/LLaMA-Efficient-Tuning/ 目录下的图片。
关于以上 RM 和 PPO 在平台上的例子,可以参考 RM 和 PPO,多机多卡的训练可以参考 PPO-multi。
对接低代码训练框架
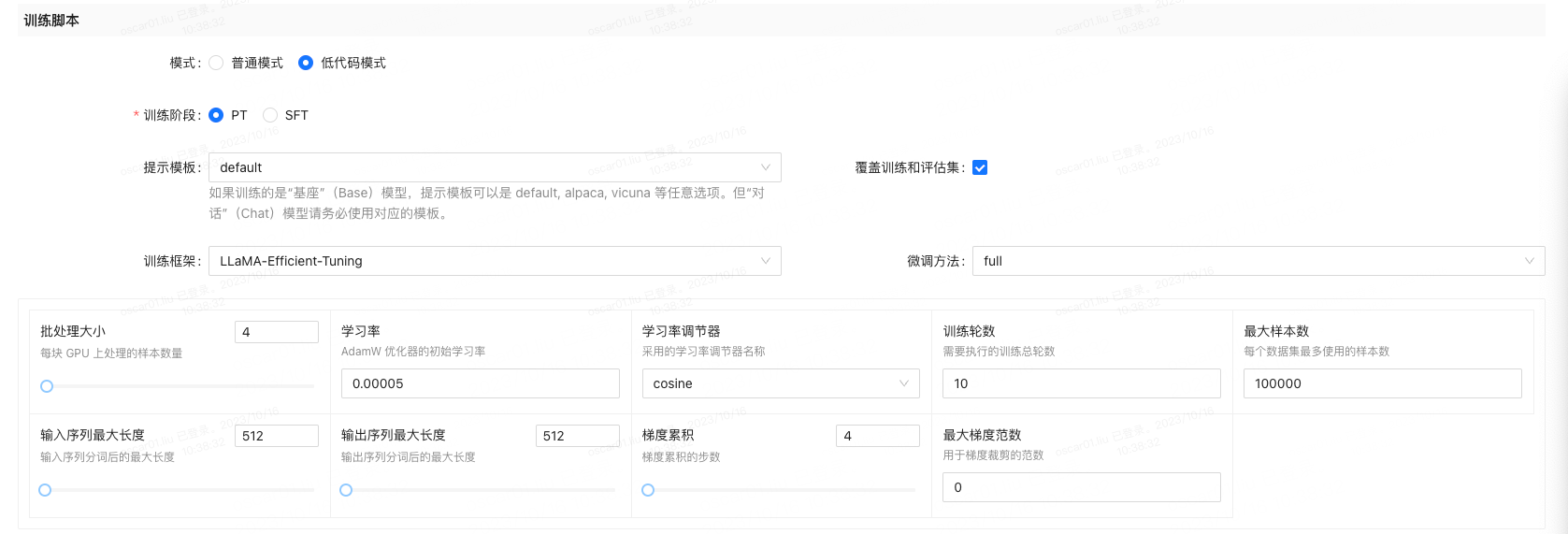
目前大模型基础平台的训练任务,提供了基于 LET 框架的低代码训练任务的构建。

基本的实现原理非常简单,由于大模型基础平台本身就有基于 UI 创建一个在 Kubernetes 集群的训练任务,因此第一期的实现是基于已有的代码逻辑来实现的,在 LET 中,通过环境变量传递对应的参数,然后启动一个预设好的脚本 run.sh 启动一个真正的 LET 训练任务。
Train
继续训练
训练任务失败的演示
虽然任务是失败了,但是前端还是显示训练完毕,这样跟预期是有点差别的。
实际需要补充一个文件。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py \
--stage sft \
--model_name_or_path /apps/dat/file/llm/model/chatglm2-6b \
--do_train True \
--overwrite_cache True \
--finetuning_type lora \
--template default \
--dataset_dir data \
--dataset alpaca_en \
--max_source_length 512 \
--max_target_length 512 \
--learning_rate 5e-05 \
--num_train_epochs 3.0 \
--max_samples 100000 \
--per_device_train_batch_size 4 \
--gradient_accumulation_steps 4 \
--lr_scheduler_type cosine \
--max_grad_norm 1.0 \
--logging_steps 5 \
--save_steps 100 \
--warmup_steps 0 \
--padding_side left \
--lora_rank 8 \
--lora_dropout 0.1 \
--lora_target query_key_value \
--resume_lora_training True \
--output_dir saves/BLOOM-560M/lora/ \
--fp16 True \
--plot_loss True
|
单机多卡
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
cat >> ds_config.json <<"EOF"
{
"train_micro_batch_size_per_gpu": "auto",
"gradient_accumulation_steps": "auto",
"gradient_clipping": "auto",
"zero_allow_untested_optimizer": true,
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"initial_scale_power": 16,
"loss_scale_window": 1000,
"hysteresis": 2,
"min_loss_scale": 1
},
"zero_optimization": {
"stage": 2,
"allgather_partitions": true,
"allgather_bucket_size": 5e8,
"reduce_scatter": true,
"reduce_bucket_size": 5e8,
"overlap_comm": false,
"contiguous_gradients": true
}
}
EOF
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
deepspeed --num_gpus 8 --master_port=9901 src/train_bash.py \
--deepspeed ds_config.json \
--stage sft \
--model_name_or_path bigscience/bloomz-560m \
--do_train True \
--overwrite_cache True \
--finetuning_type lora \
--template default \
--dataset_dir data \
--dataset alpaca_en \
--max_source_length 512 \
--max_target_length 512 \
--learning_rate 5e-05 \
--num_train_epochs 3.0 \
--max_samples 100000 \
--per_device_train_batch_size 4 \
--gradient_accumulation_steps 4 \
--lr_scheduler_type cosine \
--max_grad_norm 1.0 \
--logging_steps 5 \
--save_steps 100 \
--warmup_steps 0 \
--padding_side left \
--lora_rank 8 \
--lora_dropout 0.1 \
--lora_target query_key_value \
--resume_lora_training True \
--output_dir saves/BLOOMZ-560M/lora/2023-08-31 \
--fp16 True \
--plot_loss True
|
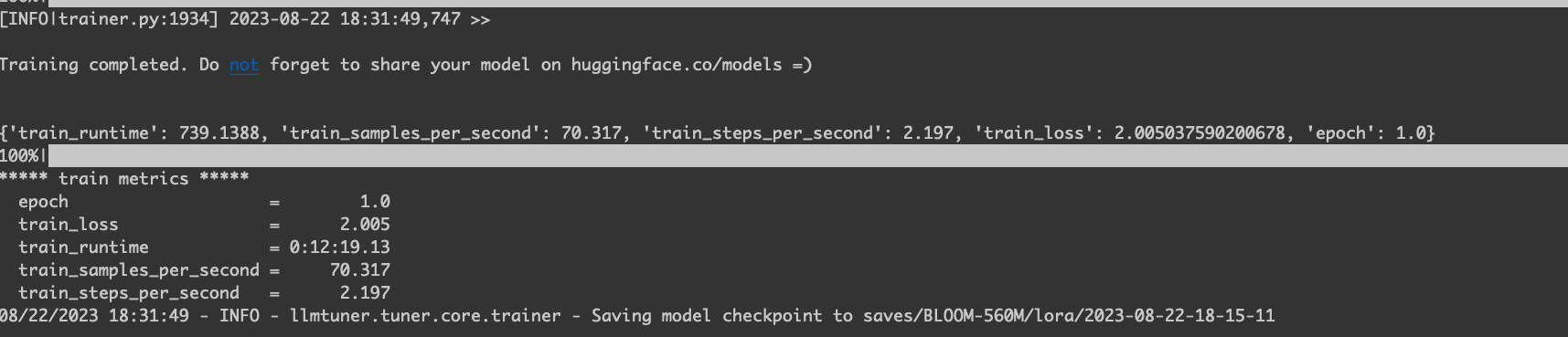
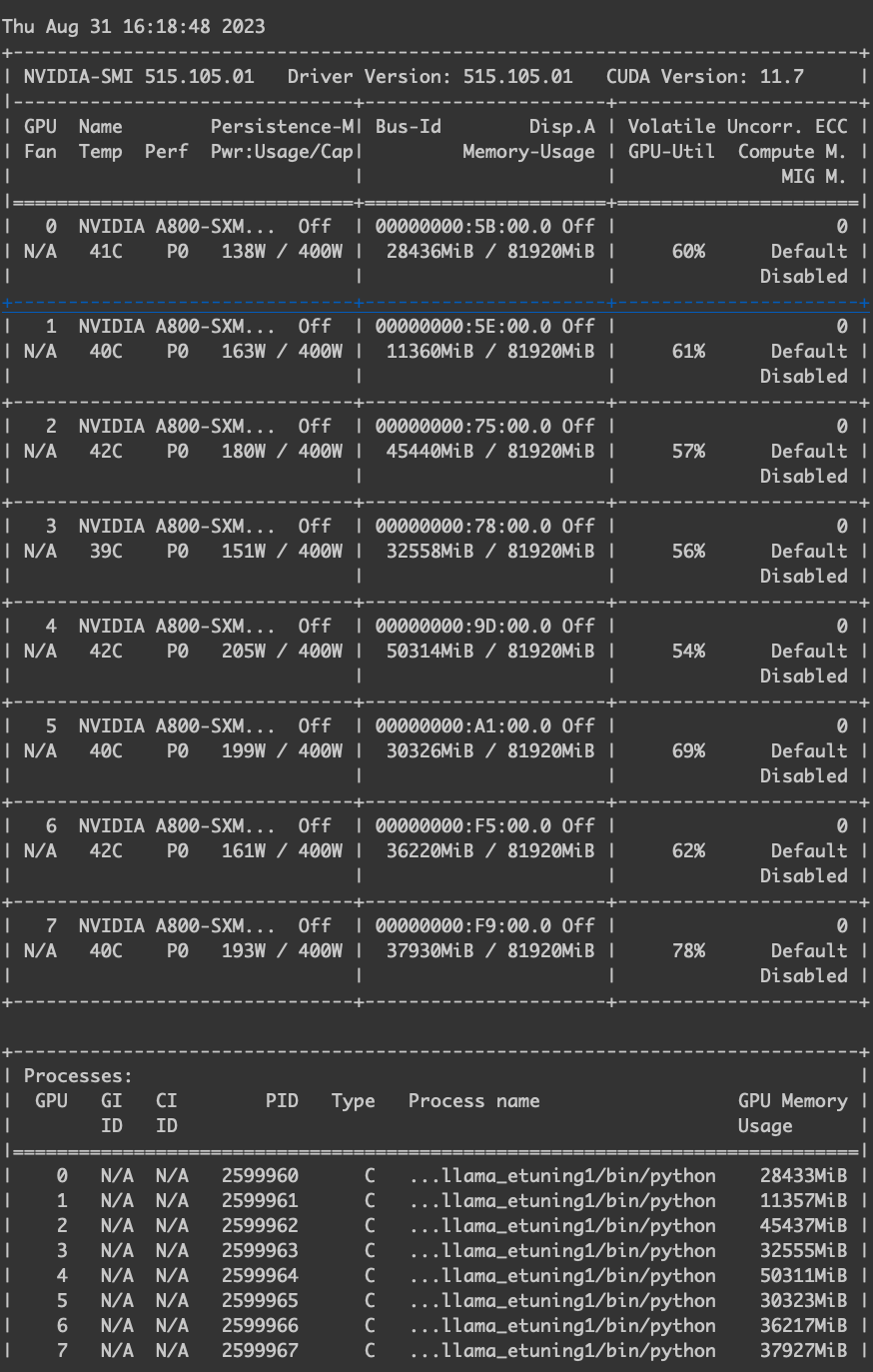
lora 下微调的 GPU 使用率。
训练结束。
下面用 full 模式 finetune 看看。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
deepspeed --num_gpus 8 --master_port=9901 src/train_bash.py \
--deepspeed config.json \
--stage sft \
--model_name_or_path /apps/dat/file/llm/model/chatglm2-6b/ \
--do_train True \
--overwrite_cache True \
--finetuning_type full \
--template default \
--dataset_dir data \
--dataset alpaca_en \
--max_source_length 512 \
--max_target_length 512 \
--learning_rate 5e-05 \
--num_train_epochs 3.0 \
--max_samples 100000 \
--per_device_train_batch_size 4 \
--gradient_accumulation_steps 4 \
--lr_scheduler_type cosine \
--max_grad_norm 1.0 \
--logging_steps 5 \
--save_steps 100 \
--warmup_steps 0 \
--padding_side left \
--lora_rank 8 \
--lora_dropout 0.1 \
--lora_target query_key_value \
--resume_lora_training True \
--output_dir saves/BLOOMZ-560M/full/2023-08-31-08-00-24 \
--fp16 True \
--plot_loss True
|
Evaluate
测试了一波这个评估任务,用了65个小时左右。
完成另一个还挺久的。
RLHF
训练 RM 模型。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py \
--stage ppo \
--model_name_or_path /home/public/model/Baichuan-13B-Chat \
--do_train True \
--overwrite_cache True \
--finetuning_type lora \
--template baichuan \
--dataset_dir data \
--dataset oaast_sft_zh \
--max_source_length 512 \
--max_target_length 512 \
--learning_rate 5e-05 \
--num_train_epochs 3.0 \
--max_samples 100000 \
--per_device_train_batch_size 4 \
--gradient_accumulation_steps 4 \
--lr_scheduler_type cosine \
--max_grad_norm 1.0 \
--logging_steps 5 \
--save_steps 100 \
--warmup_steps 0 \
--padding_side left \
--lora_rank 8 \
--lora_dropout 0.1 \
--lora_target W_pack \
--resume_lora_training False \
--output_dir /tmp \
--fp16 True \
--reward_model saves/Baichuan-13B-Chat/lora/2023-08-30-09-22-32/ \
--plot_loss True
|
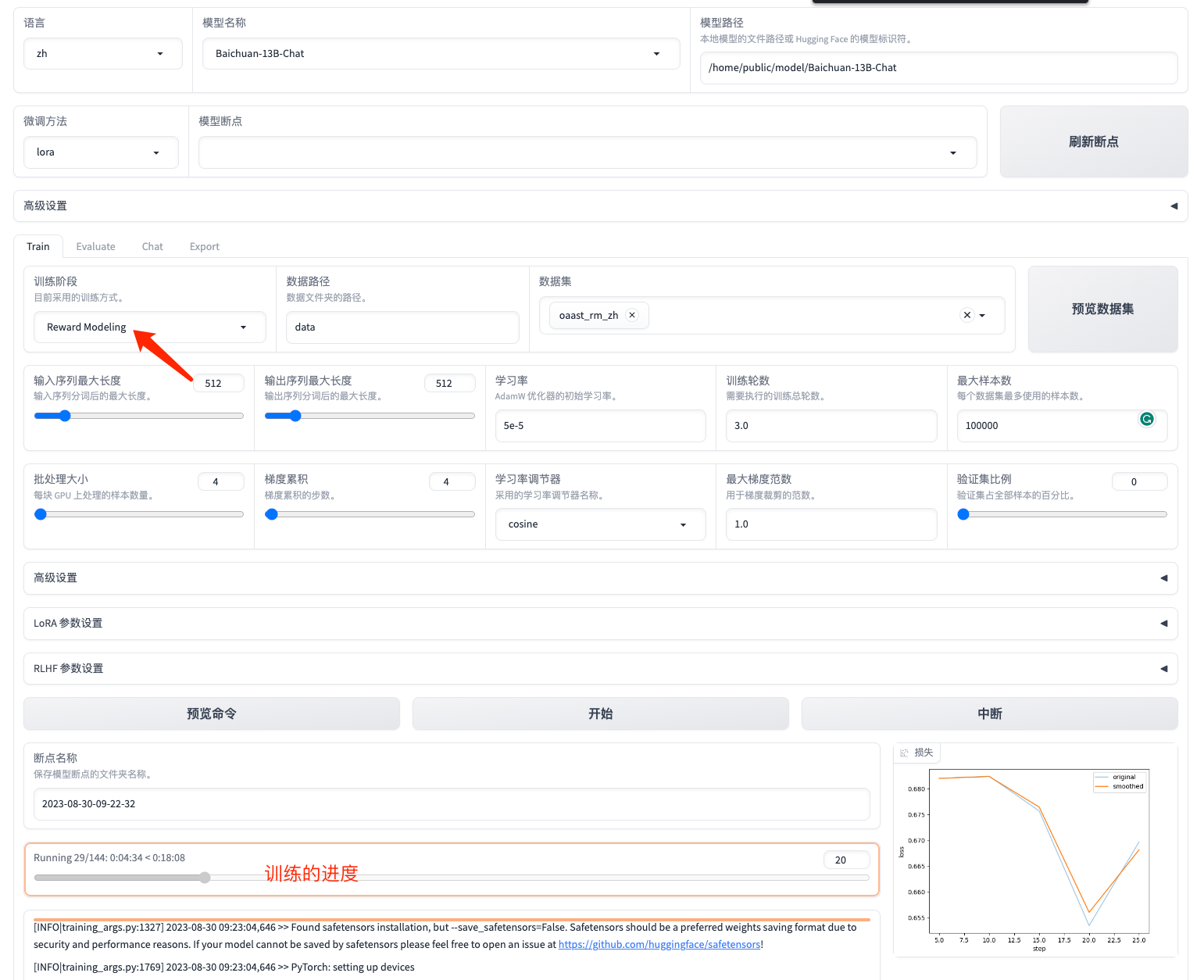
--reward_model 页面渲染的这个参数,会有些问题。
Chat
Export
一些问题
- WebUI只支持单卡训练
一些总结
RLHF的作用在于对于某些特定任务,The GPT-4 base model is only slightly better at this task than GPT-3.5; however, after RLHF post-training we observe large improvements over GPT-3.5。
页面渲染的训练命令还是有些问题的,这个应该是跟代码有关系,真正用起来还是得靠 console。
RLFH 一个 13B 的模型是不行的,估计还是得多卡。
/home/public/model/chatglm2-6b/
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py \
--stage ppo \
--model_name_or_path /apps/dat/file/llm/model/chatglm2-6b/ \
--do_train True \
--overwrite_cache True \
--finetuning_type lora \
--template chatglm2 \
--dataset_dir data \
--dataset oaast_sft_zh \
--max_source_length 512 \
--max_target_length 512 \
--learning_rate 5e-05 \
--num_train_epochs 3.0 \
--max_samples 100000 \
--per_device_train_batch_size 4 \
--gradient_accumulation_steps 4 \
--lr_scheduler_type cosine \
--max_grad_norm 1.0 \
--logging_steps 5 \
--save_steps 100 \
--warmup_steps 0 \
--padding_side left \
--lora_rank 8 \
--lora_dropout 0.1 \
--lora_target query_key_value \
--resume_lora_training False \
--output_dir /tmp \
--fp16 True \
--reward_model saves/ChatGLM2-6B-Chat/lora/ \
--plot_loss True
|
跑起来。
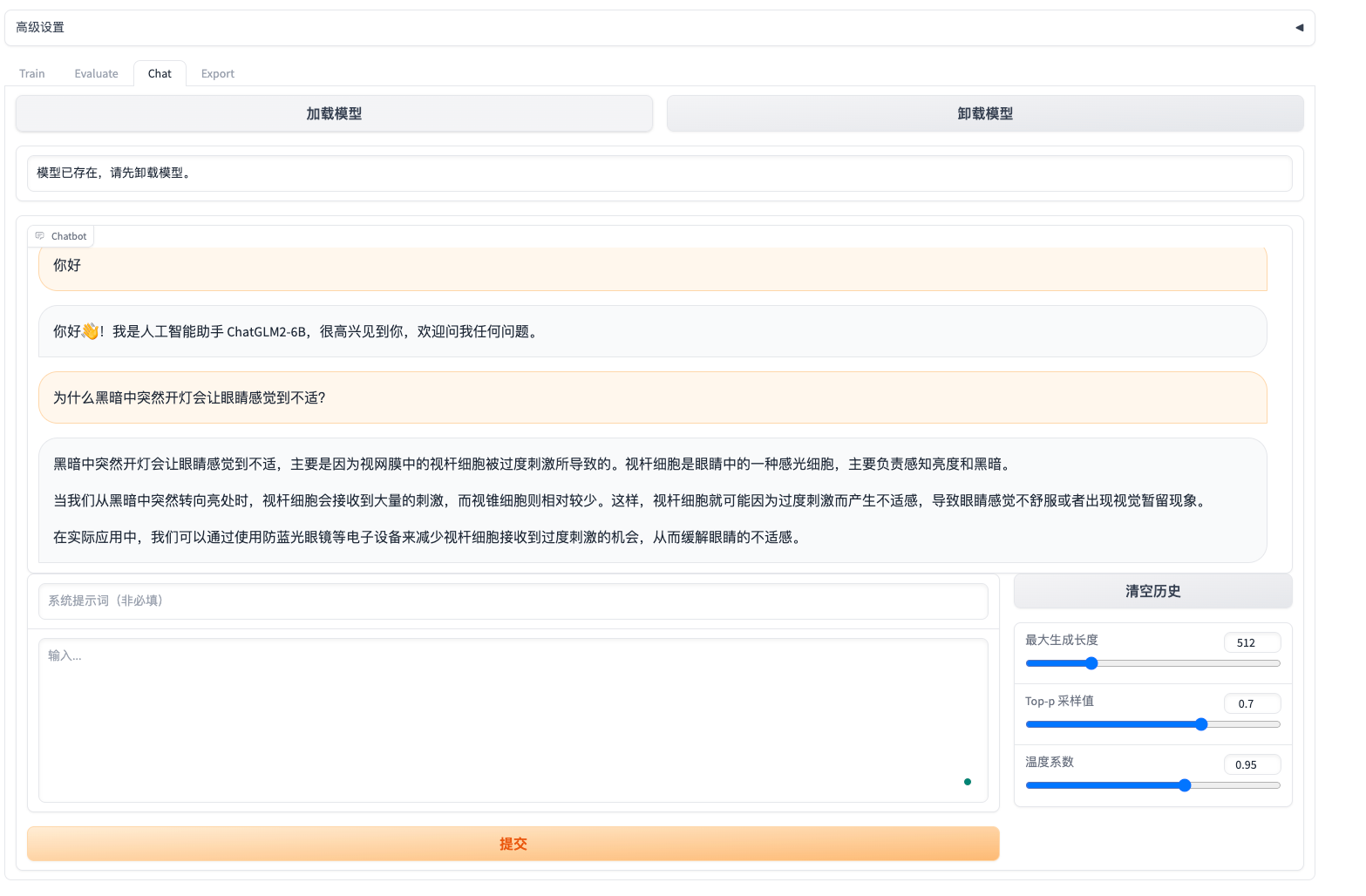
可以用于 chat 的测试。
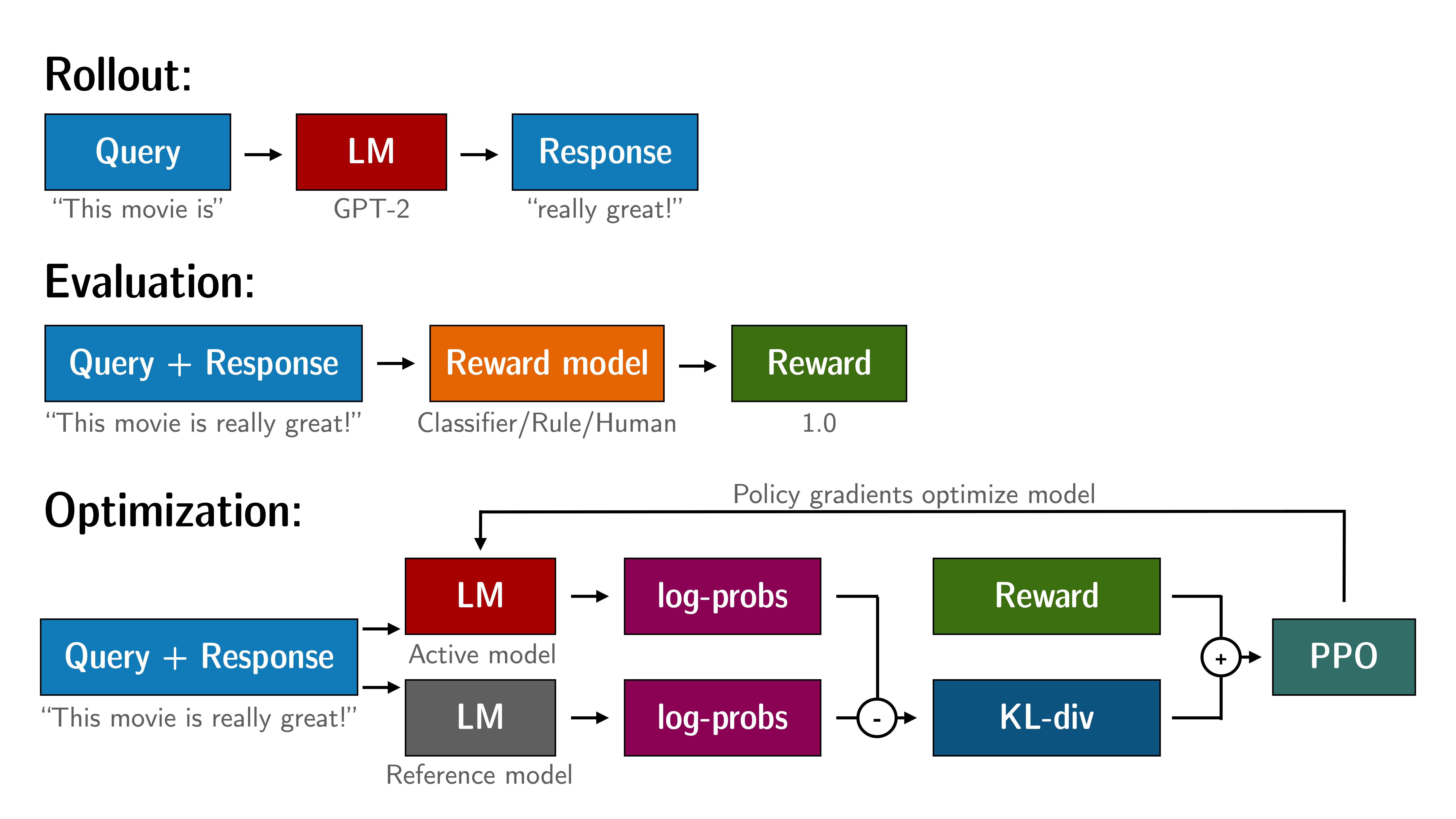
关于PPO
How PPO works Fine-tuning a language model via PPO consists of roughly three steps:
- Rollout: The language model generates a response or continuation based on query which could be the start of a sentence.
- Evaluation: The query and response are evaluated with a function, model, human feedback or some combination of them. The important thing is that this process should yield a scalar value for each query/response pair.
- Optimization: This is the most complex part. In the optimisation step the query/response pairs are used to calculate the log-probabilities of the tokens in the sequences. This is done with the model that is trained and a reference model, which is usually the pre-trained model before fine-tuning. The KL-divergence between the two outputs is used as an additional reward signal to make sure the generated responses don’t deviate to far from the reference language model. The active language model is then trained with PPO.
This process is illustrated in the sketch below:
- Rollout: 语言模型根据query生成response
- 评估: 使用a function、model、human feedback或它们的某种组合进行评估,然后为每个query/response对产生一个标量值,说白了就是奖励模型有了,那就直接打分
- 优化: 在优化步骤中,「query/response pairs」用于计算序列中标记的对数概率,且比较下面这两个模型输出之间的KL散度用作额外的奖励信号,经过训练的模型(即上图中的Active model),基线模型(即上图中的Reference model),通常是PPO微调之前的模型(比如这里的GPT2,或者instructGPT里的SFT),最终使得Active model生成的响应不会偏离基线模型Reference model太远
accelerate
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
accelerate launch src/train_bash.py \
--stage sft \
--model_name_or_path bigscience/bloom-560m \
--do_train True \
--overwrite_cache True \
--finetuning_type lora \
--template default \
--dataset_dir data \
--dataset alpaca_en \
--max_source_length 512 \
--max_target_length 512 \
--learning_rate 5e-05 \
--num_train_epochs 3.0 \
--max_samples 100000 \
--per_device_train_batch_size 4 \
--gradient_accumulation_steps 4 \
--lr_scheduler_type cosine \
--max_grad_norm 1.0 \
--logging_steps 5 \
--save_steps 100 \
--warmup_steps 0 \
--padding_side left \
--lora_rank 8 \
--lora_dropout 0.1 \
--lora_target query_key_value \
--resume_lora_training True \
--output_dir saves/BLOOM-560M/lora/ \
--fp16 True \
--plot_loss True
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
CUDA_VISIBLE_DEVICES=1 accelerate launch src/train_bash.py \
--stage rm \
--model_name_or_path bigscience/bloom-560m \
--do_train True \
--overwrite_cache True \
--finetuning_type lora \
--template default \
--dataset_dir data \
--dataset oaast_rm \
--max_source_length 512 \
--max_target_length 512 \
--learning_rate 5e-05 \
--num_train_epochs 3.0 \
--max_samples 100000 \
--per_device_train_batch_size 4 \
--gradient_accumulation_steps 4 \
--lr_scheduler_type cosine \
--max_grad_norm 1.0 \
--logging_steps 5 \
--save_steps 100 \
--warmup_steps 0 \
--padding_side left \
--lora_rank 8 \
--lora_dropout 0.1 \
--lora_target query_key_value \
--resume_lora_training False \
--output_dir saves/BLOOM-560M/lora/ \
--fp16 True \
--plot_loss True
|
deepspeed
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
# 有问题,不能直接加config
deepspeed --hostfile=/tmp/hostfile_ds src/train_bash.py \
# 这个需要省略才可以
--deepspeed /data/runzhliu/LLaMA-Efficient-Tuning/config.json \
--stage rm \
--model_name_or_path bigscience/bloom-560m \
--do_train True \
--overwrite_cache True \
--finetuning_type lora \
--template default \
--dataset_dir data \
--dataset oaast_rm \
--max_source_length 512 \
--max_target_length 512 \
--learning_rate 5e-05 \
--num_train_epochs 3.0 \
--max_samples 100000 \
--per_device_train_batch_size 4 \
--gradient_accumulation_steps 1 \
--lr_scheduler_type cosine \
--max_grad_norm 1.0 \
--logging_steps 5 \
--save_steps 100 \
--warmup_steps 0 \
--padding_side left \
--lora_rank 8 \
--lora_dropout 0.1 \
--lora_target query_key_value \
--resume_lora_training False \
--output_dir saves/BLOOM-560M/lora/ \
--fp16 True \
--plot_loss True
|
实际是会执行下面那样的一段 pdsh 的命令。
1
|
pdsh -S -f 1024 -w 29.29.183.4,29.29.187.127 export PYTHONPATH=/data/runzhliu/LLaMA-Efficient-Tuning; export CUDA_VISIBLE_DEVICES=3,4; export LC_TERMINAL_VERSION=3.4.19; export LANG=en_US.UTF-8; export LC_TERMINAL=iTerm2; export LC_CTYPE=en_US.UTF-8; export USER=root; export LOGNAME=root; export HOME=/root; export PATH=/root/miniconda3/envs/llama_etuning1/bin:/root/miniconda3/condabin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin; export SHELL=/usr/bin/zsh; export TERM=xterm-256color; export XDG_SESSION_ID=22822; export XDG_RUNTIME_DIR=/run/user/0; export DBUS_SESSION_BUS_ADDRESS=unix:path=/run/user/0/bus; export XDG_SESSION_TYPE=tty; export XDG_SESSION_CLASS=user; export MOTD_SHOWN=pam; export SSH_TTY=/dev/pts/125; export SHLVL=1; export PWD=/data/runzhliu/LLaMA-Efficient-Tuning; export OLDPWD=/root; export ZSH=/root/.oh-my-zsh; export PAGER=less; export LESS=-R; export LSCOLORS=Gxfxcxdxbxegedabagacad; export CONDA_EXE=/root/miniconda3/bin/conda; export _CE_M=; export _CE_CONDA=; export CONDA_PYTHON_EXE=/root/miniconda3/bin/python; export CONDA_SHLVL=2; export CONDA_PREFIX=/root/miniconda3/envs/llama_etuning1; export CONDA_DEFAULT_ENV=llama_etuning1; export CONDA_PREFIX_1=/root/miniconda3; export _=/root/miniconda3/envs/llama_etuning1/bin/accelerate; export ACCELERATE_DEBUG_MODE=true; export ACCELERATE_MIXED_PRECISION=no; export ACCELERATE_CONFIG_DS_FIELDS=deepspeed_hostfile,deepspeed_multinode_launcher,gradient_accumulation_steps,offload_optimizer_device,offload_param_device,zero3_init_flag,zero_stage,mixed_precision; export ACCELERATE_USE_DEEPSPEED=true; export ACCELERATE_DEEPSPEED_ZERO_STAGE=2; export ACCELERATE_GRADIENT_ACCUMULATION_STEPS=1; export ACCELERATE_DEEPSPEED_OFFLOAD_OPTIMIZER_DEVICE=none; export ACCELERATE_DEEPSPEED_OFFLOAD_PARAM_DEVICE=none; export ACCELERATE_DEEPSPEED_ZERO3_INIT=false; cd /data/runzhliu/LLaMA-Efficient-Tuning; /root/miniconda3/envs/llama_etuning1/bin/python -u -m deepspeed.launcher.launch --world_info=eyIyOS4yOS4xODMuNCI6IFswXSwgIjI5LjI5LjE4Ny4xMjciOiBbMF19 --node_rank=0 --master_addr=10.99.211.55 --master_port=21011 --no_local_rank src/train_bash.py --stage 'rm' --model_name_or_path 'bigscience/bloom-560m' --do_train 'True' --overwrite_cache 'True' --finetuning_type 'lora' --template 'default' --dataset_dir 'data' --dataset 'oaast_rm' --max_source_length '512' --max_target_length '512' --learning_rate '5e-05' --num_train_epochs '3.0' --max_samples '100000' --per_device_train_batch_size '1' --gradient_accumulation_steps '1' --lr_scheduler_type 'cosine' --max_grad_norm '1.0' --logging_steps '5' --save_steps '100' --warmup_steps '0' --padding_side 'left' --lora_rank '8' --lora_dropout '0.1' --lora_target 'query_key_value' --resume_lora_training 'False' --output_dir 'saves/BLOOM-560M/lora/' --fp16 'True' --plot_loss 'True'
|
集成LLM平台
单机单卡运行
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
|
cd /apps/dat/training/cs-runzhliu/LLaMA-Efficient-Tuning
pip install wandb transformers==4.32.0 -i https://mirrors.cloud.tencent.com/pypi/simple
pip install -r requirements.txt -i https://mirrors.cloud.tencent.com/pypi/simple
OUTPUT_DIR=/apps/dat/training/cs-runzhliu/LLaMA-Efficient-Tuning/saves
MODEL_NAME_OR_PATH=/apps/dat/file/llm/model/chatglm2-6b
DATASET_DIR=data
DATASET=alpaca_en
export WANDB_ENTITY="vip"
export WANDB_BASE_URL="http://gd17-llm-002-wandb.vip.vip.com"
export WANDB_API_KEY="local-94b1dec19c8036a97a7414183d12f81c33d3578c"
export WANDB_PROJECT=LET-test
export WANDB_RUN_ID=LET-test-run-id-1
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py \
--stage sft \
--model_name_or_path $MODEL_NAME_OR_PATH \
--do_train True \
--overwrite_cache True \
--finetuning_type lora \
--template default \
--dataset_dir $DATASET_DIR \
--dataset $DATASET \
--max_source_length 512 \
--max_target_length 512 \
--learning_rate 5e-05 \
--num_train_epochs 3.0 \
--max_samples 100000 \
--per_device_train_batch_size 4 \
--gradient_accumulation_steps 4 \
--lr_scheduler_type cosine \
--max_grad_norm 1.0 \
--logging_steps 5 \
--save_steps 100 \
--warmup_steps 0 \
--padding_side left \
--lora_rank 8 \
--lora_dropout 0.1 \
--lora_target query_key_value \
--resume_lora_training True \
--output_dir $OUTPUT_DIR \
--fp16 True \
--plot_loss True \
--report_to wandb
|
wandb配置
单机多卡运行
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
|
OUTPUT_DIR=/apps/dat/training/cs-runzhliu/LLaMA-Efficient-Tuning/saves
MODEL_NAME_OR_PATH=/apps/dat/file/llm/model/chatglm2-6b
DATASET_DIR=data
DATASET=alpaca_en
export WANDB_ENTITY="vip"
export WANDB_BASE_URL="http://gd17-llm-002-wandb.vip.vip.com"
export WANDB_API_KEY="local-94b1dec19c8036a97a7414183d12f81c33d3578c"
export WANDB_PROJECT=LET-test
export WANDB_RUN_ID=LET-test-run-id-1
cat >> config.json <<"EOF"
{
"train_micro_batch_size_per_gpu": "auto",
"gradient_accumulation_steps": "auto",
"gradient_clipping": "auto",
"zero_allow_untested_optimizer": true,
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"initial_scale_power": 16,
"loss_scale_window": 1000,
"hysteresis": 2,
"min_loss_scale": 1
},
"zero_optimization": {
"stage": 2,
"allgather_partitions": true,
"allgather_bucket_size": 5e8,
"reduce_scatter": true,
"reduce_bucket_size": 5e8,
"overlap_comm": false,
"contiguous_gradients": true
}
}
EOF
deepspeed --num_gpus 8 --master_port=9901 src/train_bash.py \
--deepspeed config.json \
--stage sft \
--model_name_or_path $MODEL_NAME_OR_PATH \
--do_train True \
--overwrite_cache True \
--finetuning_type full \
--template default \
--dataset_dir $DATASET_DIR \
--dataset $DATASET \
--max_source_length 512 \
--max_target_length 512 \
--learning_rate 5e-05 \
--num_train_epochs 3.0 \
--max_samples 100000 \
--per_device_train_batch_size 4 \
--gradient_accumulation_steps 4 \
--lr_scheduler_type cosine \
--max_grad_norm 1.0 \
--logging_steps 5 \
--save_steps 100 \
--warmup_steps 0 \
--padding_side left \
--lora_rank 8 \
--lora_dropout 0.1 \
--lora_target query_key_value \
--resume_lora_training True \
--output_dir $OUTPUT_DIR \
--fp16 True \
--plot_loss True
|
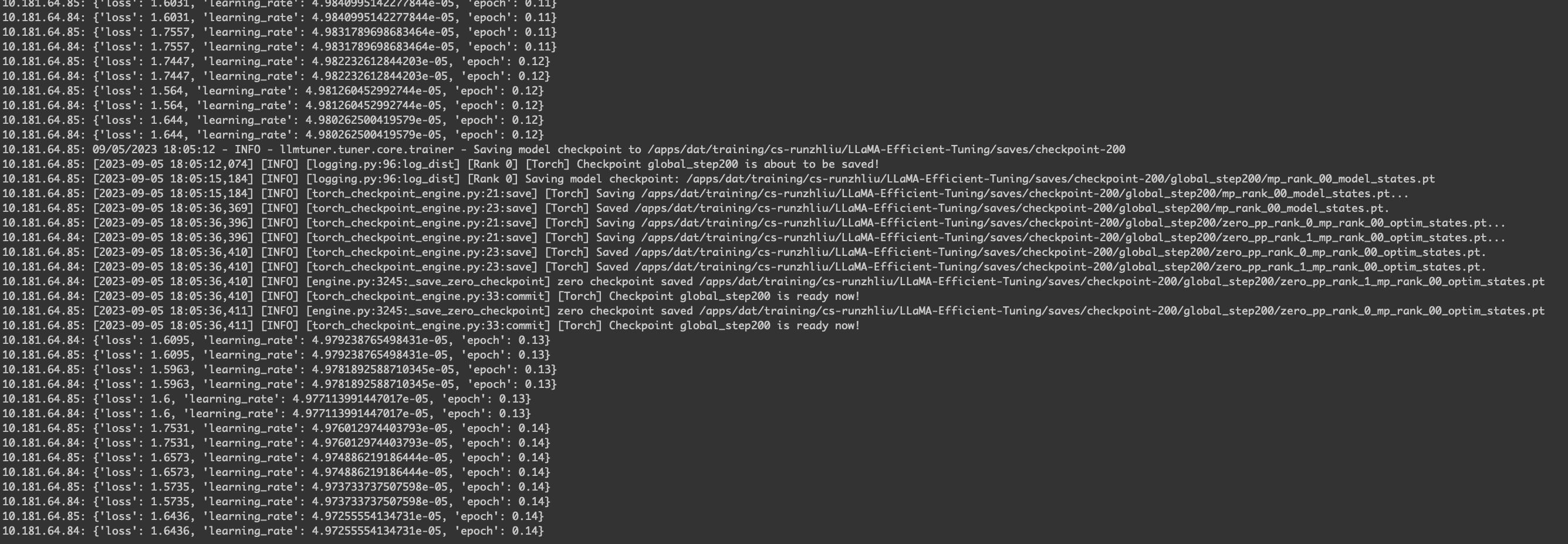
日志显示。
wandb 显示。
多机多卡运行
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
export OUTPUT_DIR=/apps/dat/training/cs-runzhliu/LLaMA-Efficient-Tuning/saves
export MODEL_NAME_OR_PATH=/apps/dat/file/llm/model/chatglm2-6b
export DATASET_DIR=data
export DATASET=alpaca_en
apt-get update -y
apt-get install openssh-server -y
service ssh start
apt-get install pdsh -y
apt-get install ninja-build -y
deepspeed --hostfile=/tmp/hostfile src/train_bash.py \
--deepspeed config.json \
--stage sft \
--model_name_or_path /apps/dat/file/llm/model/chatglm2-6b \
--do_train True \
--overwrite_cache True \
--finetuning_type lora \
--template default \
--dataset_dir data \
--dataset alpaca_en \
--max_source_length 512 \
--max_target_length 512 \
--learning_rate 5e-05 \
--num_train_epochs 3.0 \
--max_samples 100000 \
--per_device_train_batch_size 4 \
--gradient_accumulation_steps 4 \
--lr_scheduler_type cosine \
--max_grad_norm 1.0 \
--logging_steps 5 \
--save_steps 100 \
--warmup_steps 0 \
--padding_side left \
--lora_rank 8 \
--lora_dropout 0.1 \
--lora_target query_key_value \
--resume_lora_training True \
--output_dir /apps/dat/training/cs-runzhliu/LLaMA-Efficient-Tuning/saves \
--fp16 True \
--plot_loss True
|
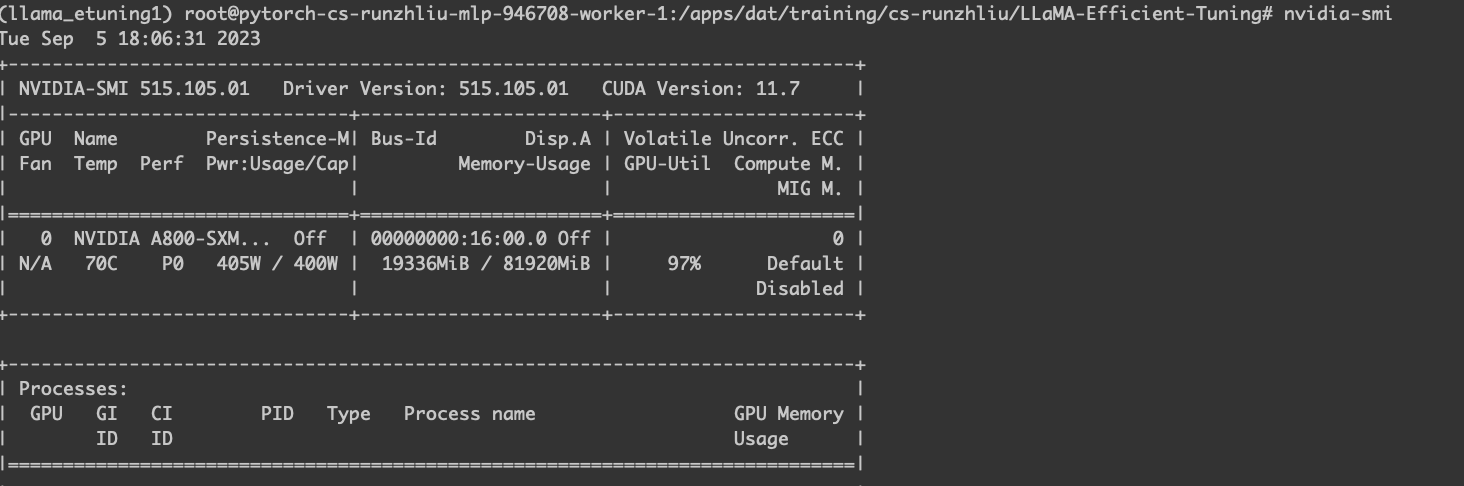
worker-1 的 GPU 使用情况。
torchrun
如果是通过平台默认的分布式运行的方式,可以使用 torchrun 来运行训练的脚本。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
torchrun \
--nnodes=${NNODES} \
--nproc_per_node=${NPROC_PER_NODE} \
--master_addr=${MASTER_ADDR} \
--master_port=12375 \
--node_rank=${NODE_RANK} \
src/train_bash.py \
--stage sft \
--deepspeed config.json \
--model_name_or_path /apps/dat/file/llm/model/chatglm2-6b \
--do_train True \
--overwrite_cache True \
--finetuning_type lora \
--template default \
--dataset_dir data \
--dataset alpaca_en \
--max_source_length 512 \
--max_target_length 512 \
--learning_rate 5e-05 \
--num_train_epochs 3.0 \
--max_samples 100000 \
--per_device_train_batch_size 4 \
--gradient_accumulation_steps 4 \
--lr_scheduler_type cosine \
--max_grad_norm 1.0 \
--logging_steps 5 \
--save_steps 100 \
--warmup_steps 0 \
--padding_side left \
--lora_rank 8 \
--lora_dropout 0.1 \
--lora_target query_key_value \
--resume_lora_training True \
--output_dir /tmp/saves \
--fp16 True \
--plot_loss True
|
基础
Stage –stage
无 –model_name_or_path
无 –do_train
无 –overwrite_cache
无 –finetuning_type
无 –template
Data dir –dataset_dir
Dataset –dataset
Max source length –max_source_length
Max target length –max_target_length
Learning rate –learning_rate
Epochs –num_train_epochs
Max samples –max_samples
Batch size –per_device_train_batch_size
Gradient accumulation –gradient_accumulation_steps
LR Scheduler –lr_scheduler_type
Maximum gradient norm –max_grad_norm
Advanced configurations
Logging steps –logging_steps
Save steps –save_steps
Warmup steps –warmup_steps
Compute type –fp16 true或者–bp16 true
Padding side –padding_side
LoRA configurations
LoRA rank –lora_rank
LoRA Dropout –lora_dropout
LoRA modules (optional) –lora_target
Resume LoRA training –resume_lora_training
Val size –暂时不开放
无 –output_dir
STAGE
MODEL_NAME_OR_PATH
DO_TRAIN
OVERWRITE_CACHE
FINETUNING_TYPE
TEMPLATE
DATASET_DIR
DATASET
MAX_SOURCE_LENGTH
MAX_TARGET_LENGTH
LEARNING_RATE
NUM_TRAIN_EPOCHS
MAX_SAMPLES
PER_DEVICE_TRAIN_BATCH_SIZE
GRADIENT_ACCUMULATION_STEPS
LR_SCHEDULER_TYPE
MAX_GRAD_NORM
LOGGING_STEPS
SAVE_STEPS
WARMUP_STEPS
FP16 TRUE或者–BP16 TRUE
PADDING_SIDE
LORA_RANK
LORA_DROPOUT
LORA_TARGET
RESUME_LORA_TRAINING
OUTPUT_DIR
PPO
首先需要一个 RM 模型。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py \
--stage rm \
--model_name_or_path /apps/dat/file/llm/model/Baichuan2-13B-Chat \
--do_train True \
--overwrite_cache True \
--finetuning_type lora \
--template baichuan \
--dataset_dir data \
--dataset oaast_rm_zh \
--max_source_length 512 \
--max_target_length 512 \
--learning_rate 5e-05 \
--num_train_epochs 1.0 \
--max_samples 1000 \
--per_device_train_batch_size 4 \
--gradient_accumulation_steps 4 \
--lr_scheduler_type cosine \
--max_grad_norm 1.0 \
--logging_steps 5 \
--save_steps 100 \
--warmup_steps 0 \
--padding_side left \
--lora_rank 8 \
--lora_dropout 0.1 \
--lora_target W_pack \
--resume_lora_training False \
--output_dir saves/Baichuan2-13B-Chat/lora/2023-09-22-07-08-58 \
--fp16 True \
--plot_loss True
|
然后再进行 PPO。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py \
--stage ppo \
--model_name_or_path /apps/dat/file/llm/model/Baichuan2-13B-Chat \
--reward_model saves/Baichuan2-13B-Chat/lora/2023-09-22-07-08-58 \
--do_train True \
--overwrite_cache True \
--finetuning_type lora \
--template baichuan \
--dataset_dir data \
--dataset oaast_sft_zh \
--max_source_length 512 \
--max_target_length 512 \
--learning_rate 5e-05 \
--num_train_epochs 1.0 \
--max_samples 100000 \
--per_device_train_batch_size 4 \
--gradient_accumulation_steps 4 \
--lr_scheduler_type cosine \
--max_grad_norm 1.0 \
--logging_steps 5 \
--save_steps 100 \
--warmup_steps 0 \
--padding_side left \
--lora_rank 8 \
--lora_dropout 0.1 \
--lora_target W_pack \
--resume_lora_training False \
--output_dir ppo-result/saves/Baichuan-13B-Chat/lora/2023-09-22-07-08-58 \
--fp16 True \
--plot_loss True
|
一般单卡是跑不了的,配置一下多卡。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
|
rm -rf ppo-result/saves/Baichuan-13B-Chat/lora/2023-09-22-07-08-58
cat > ds_config.json <<"EOF"
{
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"gradient_accumulation_steps": "auto",
"gradient_clipping": "auto",
"zero_allow_untested_optimizer": true,
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"initial_scale_power": 16,
"loss_scale_window": 1000,
"hysteresis": 2,
"min_loss_scale": 1
},
"zero_optimization": {
"stage": 2,
"allgather_partitions": true,
"allgather_bucket_size": 5e8,
"reduce_scatter": true,
"reduce_bucket_size": 5e8,
"overlap_comm": false,
"contiguous_gradients": true
}
}
EOF
deepspeed --num_gpus 8 --master_port=9901 src/train_bash.py \
--deepspeed ds_config.json \
--stage ppo \
--model_name_or_path /apps/dat/file/llm/model/Baichuan2-13B-Chat \
--reward_model saves/Baichuan2-13B-Chat/lora/2023-09-22-07-08-58 \
--do_train True \
--overwrite_cache True \
--finetuning_type lora \
--template baichuan \
--dataset_dir data \
--dataset oaast_sft_zh \
--max_source_length 512 \
--max_target_length 512 \
--learning_rate 5e-05 \
--num_train_epochs 1.0 \
--max_samples 100000 \
--per_device_train_batch_size 1 \
--gradient_accumulation_steps 1 \
--lr_scheduler_type cosine \
--max_grad_norm 1.0 \
--logging_steps 5 \
--save_steps 100 \
--warmup_steps 0 \
--padding_side left \
--lora_rank 8 \
--lora_dropout 0.1 \
--lora_target W_pack \
--resume_lora_training False \
--output_dir ppo-result/saves/Baichuan-13B-Chat/lora/2023-09-22-07-08-58 \
--bf16 True \
--plot_loss True
|
DPO
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
|
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py \
--stage sft \
--model_name_or_path /apps/dat/file/llm/model/Baichuan-13B-Chat-0901/ \
--do_train \
--dataset alpaca_gpt4_en \
--template baichuan \
--finetuning_type lora \
--lora_target W_pack \
--output_dir /tmp/sft/ \
--overwrite_cache \
--per_device_train_batch_size 4 \
--gradient_accumulation_steps 4 \
--lr_scheduler_type cosine \
--logging_steps 10 \
--save_steps 1000 \
--learning_rate 5e-5 \
--num_train_epochs 1.0 \
--plot_loss \
--fp16
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py \
--stage rm \
--model_name_or_path /apps/dat/file/llm/model/Baichuan-13B-Chat-0901/ \
--do_train \
--dataset comparison_gpt4_en \
--template baichuan \
--finetuning_type lora \
--lora_target W_pack \
--resume_lora_training False \
--checkpoint_dir /tmp/sft/ \
--output_dir /tmp/rm/ \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 4 \
--lr_scheduler_type cosine \
--logging_steps 10 \
--save_steps 1000 \
--learning_rate 1e-6 \
--num_train_epochs 1.0 \
--plot_loss \
--fp16
# trl版本要0.7.1
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py \
--stage dpo \
--model_name_or_path /apps/dat/file/llm/model/Baichuan-13B-Chat-0901/ \
--do_train \
--dataset comparison_gpt4_en \
--template baichuan \
--finetuning_type lora \
--lora_target W_pack \
--resume_lora_training False \
--output_dir /tmp/dpo \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 4 \
--lr_scheduler_type cosine \
--logging_steps 10 \
--save_steps 1000 \
--learning_rate 1e-5 \
--num_train_epochs 1.0 \
--plot_loss \
--fp16
# 全参的方式,显存已经达到50G
CUDA_VISIBLE_DEVICES=1 python src/train_bash.py \
--stage dpo \
--model_name_or_path /apps/dat/file/llm/model/opt-1.3b \
--do_train \
--dataset comparison_gpt4_en \
--template default \
--finetuning_type full \
--resume_lora_training False \
--output_dir /tmp/dpo-full \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 4 \
--lr_scheduler_type cosine \
--logging_steps 10 \
--save_steps 1000 \
--learning_rate 1e-5 \
--num_train_epochs 1.0 \
--plot_loss \
--fp16
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
|
deepspeed --num_gpus 8 --master_port=9901 src/train_bash.py \
--deepspeed config.json \
--stage sft \
--model_name_or_path /apps/dat/file/llm/model/Qwen-14B-Chat \
--do_train \
--dataset alpaca_gpt4_en \
--template chatml \
--finetuning_type full \
--output_dir /tmp/a/ \
--overwrite_cache \
--per_device_train_batch_size 4 \
--gradient_accumulation_steps 4 \
--lr_scheduler_type cosine \
--logging_steps 10 \
--save_steps 1000 \
--learning_rate 5e-5 \
--num_train_epochs 3.0 \
--plot_loss \
--fp16
# DPO全参基本是跑不通的
deepspeed --num_gpus 8 --master_port=9901 src/train_bash.py \
--deepspeed config.json \
--stage dpo \
--model_name_or_path /apps/dat/file/llm/model/Qwen-14B-Chat \
--do_train \
--dataset comparison_gpt4_zh \
--template chatml \
--finetuning_type full \
--output_dir /tmp/Baichuan-DPO \
--overwrite_cache \
--ddp_timeout 18000 \
--per_device_train_batch_size 1 \
--gradient_accumulation_steps 2 \
--lr_scheduler_type cosine \
--logging_steps 10 \
--save_steps 200 \
--num_train_epochs 1.0 \
--learning_rate 1e-5 \
--plot_loss
deepspeed --num_gpus 8 --master_port=9901 src/train_bash.py \
--deepspeed config.json \
--stage sft \
--model_name_or_path /apps/dat/file/llm/model/Qwen-14B-Chat \
--do_train \
--dataset alpaca_gpt4_en \
--template chatml \
--finetuning_type full \
--output_dir /tmp/a/ \
--overwrite_cache \
--per_device_train_batch_size 4 \
--gradient_accumulation_steps 4 \
--lr_scheduler_type cosine \
--logging_steps 10 \
--save_steps 1000 \
--learning_rate 5e-5 \
--num_train_epochs 3.0 \
--plot_loss
|
参考资料
- LLaMA-Efficient-Tuning中文文档
- ChatGPT技术原理解析:从RL之PPO算法、RLHF到GPT4、instructGPT
- 北大硕士RLHF实践,基于DeepSpeed-Chat成功训练上自己的模型
- 百川13B多机多卡全参预训练出现FileExistsError
- LLaMA-2-70B用zero-3去pretrain,出现OOM问题,10结点,每个节点8卡(40G,A100)#406
- trl
- PPO_Chinese_Generate
- 在一张 24 GB 的消费级显卡上用 RLHF 微调 20B LLMs
- accelerate+deepspeed多机多卡训练的两种方法
- 训练属于自己的ChatGPT(2)——使用TRL强化学习PPO控制文本的生成
- LLMs Fine-tuning 学习笔记(一):trl+peft
- deepspeed的多机多卡训练
- DeepSpeed介绍
- deepSpeed (DeepSpeed-Chat)体验
- DPO方式全量训练7B模型需要资源#798
警告
本文最后更新于 2023年8月21日,文中内容可能已过时,请谨慎参考。