Kyuubi工作原理
概述
对比 Kyuubi 和 ThriftServer 工作原理。
对比
为什么要有 Spark Thrift Server?
按作业的生命周期维度分类,我们可以简单的将 Spark 任务简单的分为两种,常驻类型和非常驻类型。常驻类型作业的特点就是 Application 的启动时间相对于总任务运行时长来讲忽略不计或者和计算过程完全解绑,如 Spark Structured Streaming任务,计算过程只有 Task 线程级别的调度,低延时快响应。而非常驻类型的作业,每次都需要启动 Spark 程序。相对而言,这个过程是非常耗时的,特别对于一些秒级分钟级的计算任务负担较重。
STS的出现
Spark Thrift Server 本质上就是一个 Spark 应用在多线程场景下的应用。它在运行时启动一个由 Driver 和 Executor 组成的分布式 SQL 引擎。在 SQL 解析层,该服务可充分利用 Spark SQL 优化器的能力,在计算执行层,由于 Spark ThriftServer 是常驻类型的应用,没有启动开销,当没有开启动态分配的情况下,整个 SQL 的计算过程为纯的线程调度模式,性能极佳。
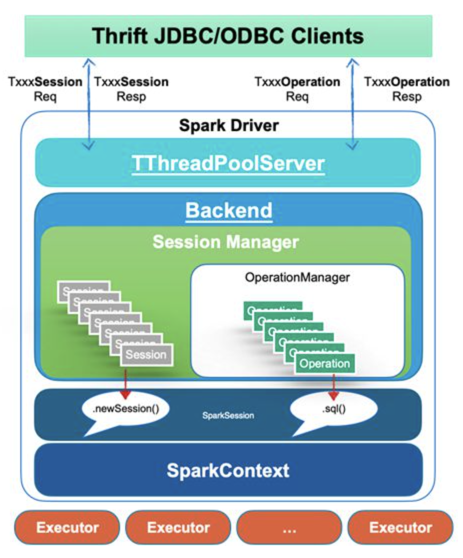
在这个架构的基础上,基于 HiveServer2 实现了 Session 相关操作,来响应客户端的连接和关闭请求,也实现了 Operation 相关操作,来响应客户端查询请求等。这些请求都由 Server 前端实现的线程池模型来响应。并调用 Server 后端的对应方法与 SparkSession 相关接口的绑定。然后 Server 后端通过一个异步线程池,将这些 Operation 提交到分布式 SQL 引擎上真正执行。
首先,在这种模式下用户通过简单的 SQL 语言和 JDBC 接口完成和 Spark ThriftServer 的交互,实现自己的业务逻辑。不需要对 Spark 本身有过多的技能基础,或者对 Spark 所运行的平台,或者底层数据的实现有过多的关注。Spark ThriftServer 基本的容量规划、底层服务的打通、以及后续的优化迭代都可以在服务端完成。当然也有同学会认为,SQL 的表达并不能满足所有的业务,但本身这个服务就是对标 HiveServer2 来给这类用户提供纯 SQL能力的。一些复杂的逻辑也可以尝试使用 UDF/UDAF 之类的进一步支持,基本上大部分的大数据处理工作,Spark ThriftServer都是可以胜任的。
其次,后台各类服务的打通都在 Spark ThriftServer 完成,不需要将其他服务的配置,如 Hive Metastore Server, Hadoop 集群等的链接配置交到终端用户手中。这一定程度上保证了数据安全。在这基础上,服务端的开发和运维一般有能力去做一些认证鉴权之类的防护工作,保护数据安全。
最后,JDBC 接口协议和 C/S 架构下服务端向下兼容的约束基本上保证了不会出现客户端兼容性的问题。用户只需选择合适版本的 JDBC 的驱动即可,服务端的升级不会造成接口的不兼容。至于版本升级中潜在的 SQL 兼容性的问题,在不使用 Spark ThriftServer 时也同样存在,且更难解决。而且在 Spark ThriftServer 模式下,服务端提前可以做全量的 SQL 采集工作,可以在升级前期就完成校验。
STS的问题
Driver单点问题
从上面 Spark Thrift Server的基本架构图我们也可以看出,其本质上是一个 Spark Application。用一个 Spark Application 去响应成千上万的客户端请求,一般会存在比较大的限制。
对于单线程的 Spark 应用来说,Driver 节点的单点效应,制约着它能起多少 Executor 提高并发能力及把数据分成多少个 Partition 来并行的处理。随着 Executor 数量的上升,Driver 需要处理更多控制面的 RPC 消息,而随着 Partition 的增加,Driver 也需要处理更多数据面的 RPC 消息。在 Spark ThriftServer 这个多线程模型下,它同时还要处理大量的客户端请求,单点的效应会更加的明显。另外,所有执行线程所依赖的 Hive metastore client 是一个,在访问 HMS 的时候也会有较明显的并发问题。
资源隔离问题
超大任务侵占过多或者所有 Spark Thrift Server 的计算资源,导致其他任务延时或者卡死。如果使用 Fair Scheduler Pools 可以一定程度上解决计算侧的资源分配问题。但是在 Driver 调度侧,难以避免的还会遇到 HMS,HDFS 访问单点的问题,特别是读写动态分区表或者大量 Union 的场景。从本质上将,CPU/内存/IO等资源隔离就应该是YARN、Kubernetes这类资源管理器该干的事情。计算层做逻辑上的资源隔离,效果不可能理想,比如,这个问题在 Apache Impala 项目里也同样存在。
多租户局限
Spark Thrift Server 本身应该是一个支持多租户的系统,即它可以接受不用用户不同客户端的请求并在服务端贡献线程池中分配这些资源完成用户的请求返回结果。但从 Spark 自身设计角度出发,单 Spark 应用实现的 Spark Thrift Server 并不能完整支持多租户,因为整个 Application 只有全局唯一的用户名, 同时包括 Driver 端和 Executor 端。这个结合 HiveServer2 来讲更方便理解,Server 端运行的时候一般使用的 Service Principal 进行启动,客户端连接带有完整的用户信息,接受服务端认证通过后会由服务端“伪装执行”,所以每次执行任务的实际用户为客户端用户,这里包括了申请资源运行 MR 程序,访问 HMS 和 HDFS 等服务。
回到 Spark Thrift Server 这边,这些资源申请和服务的访问都交给服务端用户去做。因此该服务端用户必然需要所有元数据和数据的超级权限。从数据安全的角度,这样做一方面造成潜在的权限泄露问题,另一方面 HMS 和 HDFS 也很难去根据不同的用户完成审计,因此线上出了问题一般很难追根溯源。从资源隔离和共享角度,Spark Thrift Server 占用的是单个资源队列(YARN Queue / Kubernetes Namespace, 这也导致很难细粒度或者弹性地控制每个用户可使用的资源池大小,如果有资源计费等需求就很难满足。
局限
Spark Thrift Server 社区版本是不支持高可用(High Availability, HA)的。很难想象一个没有高可用的服务端应用能否支撑起 SLA 的目标,相信运维人员是肯定睡不安稳了。当然,要给 Spark Thrift Server 增加一个 HA 并不难,例如社区老早就有人提出这个问题,并附上了PR,详见SPARK-11100。对于 Spark Thrift Server 的 HA 实现,各个厂商魔改的方式大体上分两种思路,即“主从切换”和“负载均衡”。主从切换由Active Spark Thrift Server 和若干 Standby Spark Thrift Server 构成,当 Active Spark Thrift Server挂掉之后,Standby 节点触发选主成为 Active 节点接替。
这里存在很多问题,第一,主从模式下只有一个 Active 节点,也就面临着严重的 Spark Driver 单点问题,并不能提供很高的并发能力;第二,因软硬件故障,而发生主从切换时,意味着“全部”的当前任务失败,各个 Spark 作业的 Failover 并不轻量,这基本上已经可定义为P0级别的“事故”,SLA 肯定是要受到影响了;第三,Standby 节点造成严重的集群资源浪费,无论是是否开启 Spark 动态资源分配的特性,从主从切换的更加顺滑的目的出发,都要为Standby节点“抢占”一定的资源;第四,一般而言,软件故障的概率远远大于硬件故障,而 Spark ThriftServer 软件故障一般是由于客户端高并发请求或者查询结果集过大导致的,这种模式下,一旦发生切换,客户端重试机制同时触发,新的 Standby 节点只会面对更大的宕机风险。
为了解决 Spark Thrift Server Driver 单点问题,更加合适的做法是负载均衡模式,这样当客户端的请求量上来,我们只要水平的扩充 Spark ThriftServer 即可。但这种模式也有一定的限制,每个 Spark ThriftServer 都是有状态的,两个服务之间并不能共享,比如一些全局临时视图、UDF 等,这表示客户端每次连接如果要复用都必须重新创建它们。
UDF使用的问题
包括前面谈到的 UDF 在高可用下的复用问题,对单个 Spark ThriftServer 来说,还面临这 Jar 包冲突及无法更新和删除的问题。另外,由于 UDF 是直接加载到 Spark ThriftServer 服务端的,但 UDF 中包含一些无意或者恶意的逻辑,如直接调用 System.exit(-1), 或者类似 Kerberos 认证等影响服务全局的一些操作,可能直接将服务杀掉。
接口一致性
从接口和协议上来说,Kyuubi、Spark Thrift Server 以及 HiveServer2 是完全一致的。因此,从用户的角度来讲,总体使用方式是不变的。与 HiveServer2 相比,前两者带给用户最大的不同应该就是性能上的飞跃。
从 SQL 语法兼容的角度,Kyuubi 和 Spark Thrift Server 一样完全委托 Spark SQL Catalyst 层完成,所以和 Spark SQL 全兼容。而 Spark SQL 也基本上完全支持 Hive QL集合,只有少量可枚举的 SQL 行为及语法上的差异。
多租户架构
Kyuubi、Spark ThriftServer 和 HiveServer2 的使用场景是一个典型的多租户架构。
在资源层面,我们要考虑的是在资源隔离的基础上。
- 如何在逻辑上更加安全和高效的利用这些计算资源
- 如何赋予用户对属于自己的资源“足够”的控制能力
HiveServer2 在这方面应该是做的最暴力最灵活的一个,每条 SQL 都被编排成若干 Spark 独立程序进行执行,在执行前都可以设置队列、内存等参数。但这种做法一个方面是导致了极高 Spark 启动时延,另一个方面也无法高效地利用计算资源。
Spark ThriftServer 的方向则完全相反,因为 Spark 程序只有一个且已经预启动,从用户的接口这边已无法进行队列信息、内存参数等资源调整。内部可以通过 Fair Scheduler Pools 进行“隔离”和“共享”,只能对不同的 Pool 设置权重,然后将 SQL 任务抛进不同的 Pool 而得到公平调度的能力,离真正的意义上的资源隔离还差的很远。
Kyuubi 在这个方面在其他两个系统的实现上,做了“中和”。围绕 Kyuubi Engine 这个概念实现多租户特性,一个 Engine 即为一个 Spark 程序。
从资源隔离的角度,不同租户的 Engine 是隔离的,一名用户只能创建和使用他自己的一个或者多个 Engine 实例,资源也只能来自有权限的队列或者 Namespace。
一个用户一个Engine
从用户对资源的控制能力上来讲,用户可以在创建 Engine 实例的时候对其资源进行初始化配置,这种做法虽然没有 HiveServer2 那样灵活,但可以免去大量的 Spark 程序启动开销。
从资源共享的角度,Engine 支持用户端配置不同的共享级别,如果设置为 CONNECTION 级别共享,用户的一次 JDBC 连接就会初始化一个 Engine,在这个连接内,用户可以执行多个 Statement 直至连接关闭。如果设置为 USER 级别共享,用户的多次 JDBC 都会复用这个 Engine,在高可用模式中,无论用户的连接打到哪个 Kyuubi Server 实例上,这个 Engine 都能实现共享。同一个用户可以为自己的每个连接设置不同的隔离级别。比如一些 ETL 流水作业或者定时报表任务,可以选择 CONNECTION 级别共享级别已获得任务粒度的精细资源控制。而在一些交互式分析的场景中,则可以选择 USER 级别共享并设置合适的缓存时间以获得出色的交互响应能力。
在数据层面,我们需要考虑就是元数据和数据访问的安全性,不同的用户只能访问其有权限访问的数据。如文件级别的 ACL 权限或者是元数据层面的基于 SQL 标准实现的诸如 SELECT/CREATE/ATTER/UPDATE/DROP 等类型和 DATABASE/TABLE/COLUMN 等级别的细粒度权限控制。这一切的实现都依赖一个基本的概念多租户,Spark ThriftServer 单用户显然是不可能适配这套模型的,而 Kyuubi 由于实现了多租户,天然就支持了文件级别的 ACL 权限控制,另外 通过适配 spark-authorizer 插件,也有能力实现 SQL 标准的权限控制。
高可用能力
Spark ThriftServer 的高可用问题前文已经涉及,这里不再赘述。在 Kyuubi 中,我们以负载均衡模式提供高可用, Kyuubi 服务本身不是集群资源的消耗大户,水平扩展不会有过多的负担。
客户端并发
无论是 HiveServer2 还是 Spark ThriftServer 的 SQL 的编译优化都在 Server 端完成,这个阶段需要单点地完成元数据的获取,对于大型分区表扫描存在一定的瓶颈。另外 Spark ThriftServer 同时兼具着 Spark 计算侧的 Driver 角色,负责调度服务,原则上 Executor 数量越多,处理的数据量越大,Server 端的压力也就越大。在 Kyuubi 中,用户提交的 SQL 编译优化都在 Engine 端完成,SQL Analyzer 阶段对于元数据的访问获取可以从 Server 端释放出来,同时所有的计算过程也都在 Engine 端完成,极大降低了 Kyuubi Server 端的工作负载。
服务稳定性
撇开高可用功能不讲,单个 Spark ThriftServer 由于客户端响应逻辑和 Spark 计算强耦合,一方面提高客户端并发能力则会分走大量的 Driver 端线程资源,另一方面 Driver 端在高计算负载下面临繁重的 GC 问题,丧失一定的客户端响应能力。当部分查询返回较大的结果集时,也很容易造成 OOM 的风险。Kyuubi 由于 Server 和 Engine 分离的设计,在这方面完全不存在问题。对于 UDF 使用的问题,因为是在 Engine 内部进行加载和使用的,如果用户“行车不规范”,最多也就“自己两行泪”,不会对服务的稳定性造成任何影响。
总结
Kyuubi 在统一接口基础上,拓展了 Spark ThriftServer 在多租户模式下的使用场景,并依托多租户概念获得了完善的资源隔离共享能力和数据安全隔离的能力。而得益于 Kyuubi Server 和 Engine 松耦合的架构极大提升了服务自身的并发能力和服务稳定性。由于篇幅有限,Kyuubi 对数据湖的友好支持将在以后的分享中进行介绍。点击阅读原文可查看本篇英文版。
关于高可用
Spark Thrift Server(STS) 本质上是一个 Spark 应用,当有大的查询请求时,在元数据服务访问、Spark Driver 的调度和内存压力,或者是应用的整体计算资源限制等方面都有潜在的瓶颈。而 STS 并没有提供原生的高可用(HA)特性,很早之前就有过社区提交过 STS 的 HA 方案,详见 SPARK-11100。对于 STS 的 HA 实现,一般从两个角度出发,主从切换或负载均衡。
主从切换由 Active STS 和若干 Standby STS 构成,当 Active STS 出现问题崩溃挂掉之后,Standby 节点会通过重新选主成为 Active 节点。主从切换不可避免地存在几个问题:
- 主从模式下单个 Active 节i点,会面临着严重的 Spark Driver 单点问题,并不能提供很高的并发能力
- 当发生主从切换时,当前任务将会全部失败,各个 Spark 作业的 Failover 并不轻量
- Standby 节点造成严重的集群资源浪费,无论是是否开启 Spark 动态资源分配的特性,都要考虑为 Standby 节点提前抢占一定的资源
为了解决 STS Driver 单点问题,可以通过负载均衡来实现 STS 的 HA,随着客户端的请求量增长,只要水平扩充 STS 即可。但这种模式同样存在一定的限制,每个 STS 都是有状态的,两个服务之间并不能共享一些内存变量等,比如一些全局临时视图、UDF 等,这表示客户端每次连接如果要复用都必须重新创建,这会一定程度上影响扩展的 STS 的性能。
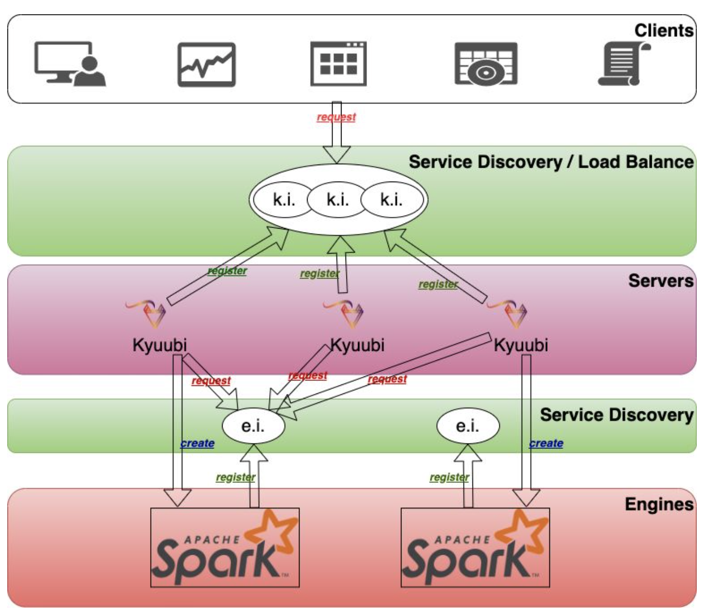
Kyuubi 是 Server 和 Engine 分离的架构,Engine 可以理解成一个 Spark Application,并且基于 ZooKeeper 同时提供了高可用和负载均衡的特性,无论用户的连接打到哪个 Kyuubi Server 实例上,这个 Engine 都能实现共享,比如当客户端从 Server 的服务发现层的命名空间中找到多个已经注册的 Kyuubi Server 实例,并且选择一个进行连接,然后再通过 Engine 的服务发现层,选择已经创建的 Engine 或者重新创建一个,同时这些服务发现层都可以实现用户和资源的隔离。
关于稳定性
对于单线程的 Spark 应用来说,Driver 节点的单点效应,制约着它能起多少 Executor 提高并发能力及把数据分成多少个 Partition 来并行的处理。随着 Executor 数量的上升,Driver 需要处理更多控制面的 RPC 消息,而随着 Partition 的增加,Driver 也需要处理更多数据面的 RPC 消息。在 STS 多线程模型下,服务端同时还要处理大量的客户端请求,单点的效应会更加的明显。另外当 Driver 端在高计算负载的情况下,还会面临繁重的 GC 问题,从而会失去一定的客户端响应能力。此外,当部分查询返回较大的结果集时,也很容易造成 OOM 的风险。
显然 Kyuubi 得益于 Server 和 Engine 分离的设计,在稳定性上原生地避免了上面提到的问题,至少在资源隔离的情况下,单个 Engine 或者 Server 的崩溃或者高负载,是不会对其他用户的查询造成太大影响。
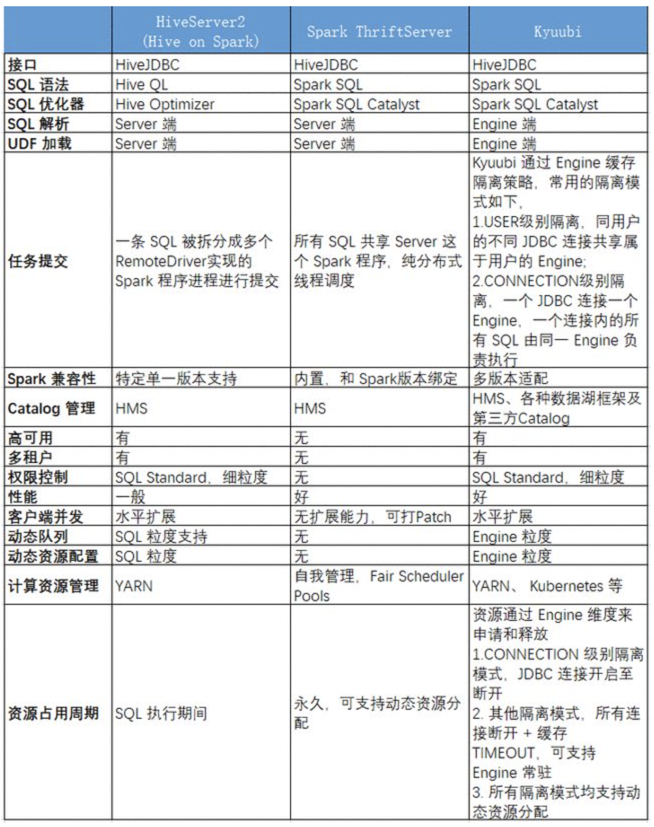
STS和Kyuubi的对比
| 对比 | STS | Kyuubi |
|---|---|---|
| 接口 | HiveJDBC | HiveJDBC |
| SQL语法 | Spark SQL | Spark SQL |
| SQL解析 | Server端 | Server端 |
| UDF加载 | Server端 | Engine端 |
| 任务提交 | 所有SQL共享Server这个Spark Application,纯分布式线程调度 | Kyuubi通过Engine缓存隔离策略,常用的隔离模式包括User和Connection级别,前者是同用户的不同JDBC连接共享属于用户的Engine,后者是一个JDBC连接一个Engine,一个连接内的所有SQL由同一Engine负责执行 |
| Spark兼容性 | 内置,和Spark版本绑定 | 多版本适配,不受版本限制 |
| 高可用 | 无 | 负载均衡 |
| 多租户 | 无 | 支持 |
| 权限 | 无 | SQL级别、细粒度 |
| 客户端并发 | 无扩展 | 扩展好 |
| 动态队列 | 无 | Engine粒度 |
| 动态资源配置 | 无 | Engine粒度 |
| 计算资源配置 | 自我管理,Fair Scheduler Pools | Yarn或者K8S |
| 资源占用周期 | 永久,可支持动态资源分配 | 资源通过Engine维度来申请和释放,如Connection级别隔离模式,JDBC连接开启至关闭,如其他隔离模式,所有连接断开+缓存TIMEOUT,可支持Engine常驻,还有就是所有隔离模式都支持动态资源分配 |