Kubeflow-Pipeline部署记录
目录
概述
Kubeflow 集成了机器学习的很多组件,比如训练、调参、模型部署,也包括了像 Tensorflow, Pytorch 等框架的支持。另外就是其还提供了 Pipeline 组件,用于用户定义机器学习的流程,从开始 -> 训练 -> 保存模型,等常见的机器学习任务流。本文主要从单独部署和测试,两个方面,展示一下使用 Pipeline 的姿势。
部署
Pipeline 作为 Kubeflow 的组件之一,其实是可以单独部署的,方法可以参考 Github 上的文档。
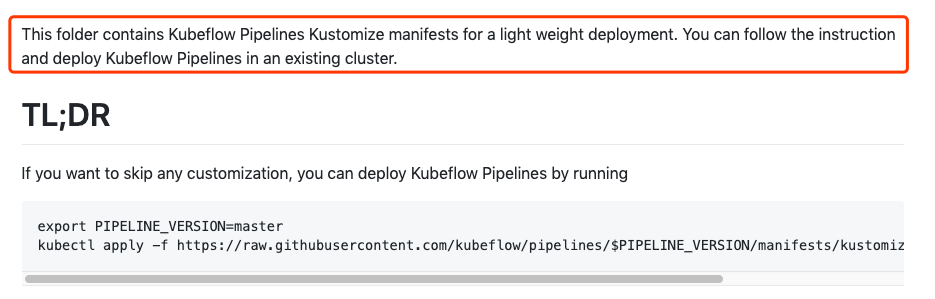
明确一下部署的目标,本文只针对给一个 K8S 集群上部署 Pipeline,不在 GCP 也不在 AWS 这些云厂商上,并且是通过 port-forward 来访问 UI。
根据部署的目标,我们需要去掉 proxy 这个模块,也就是修改文件的红色方框的部分,从原文件删除。

另外注意一下 kubectl 的版本。

|
|
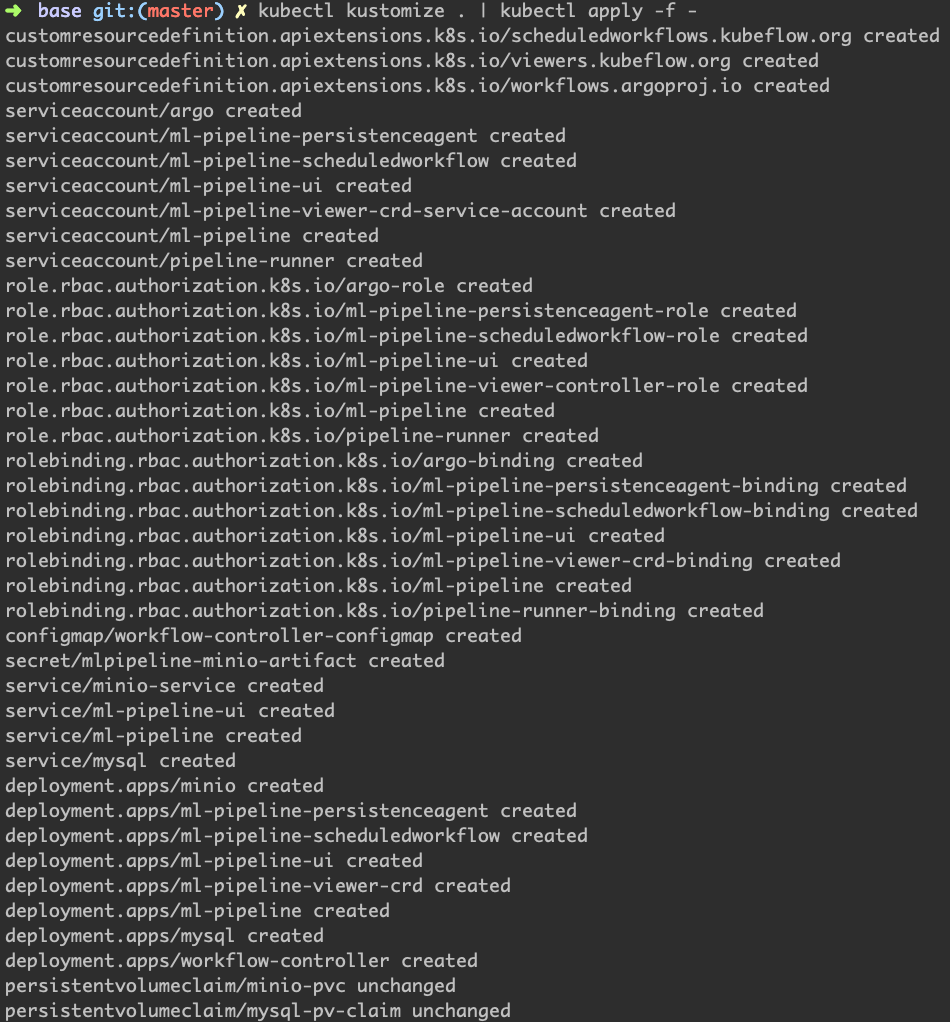
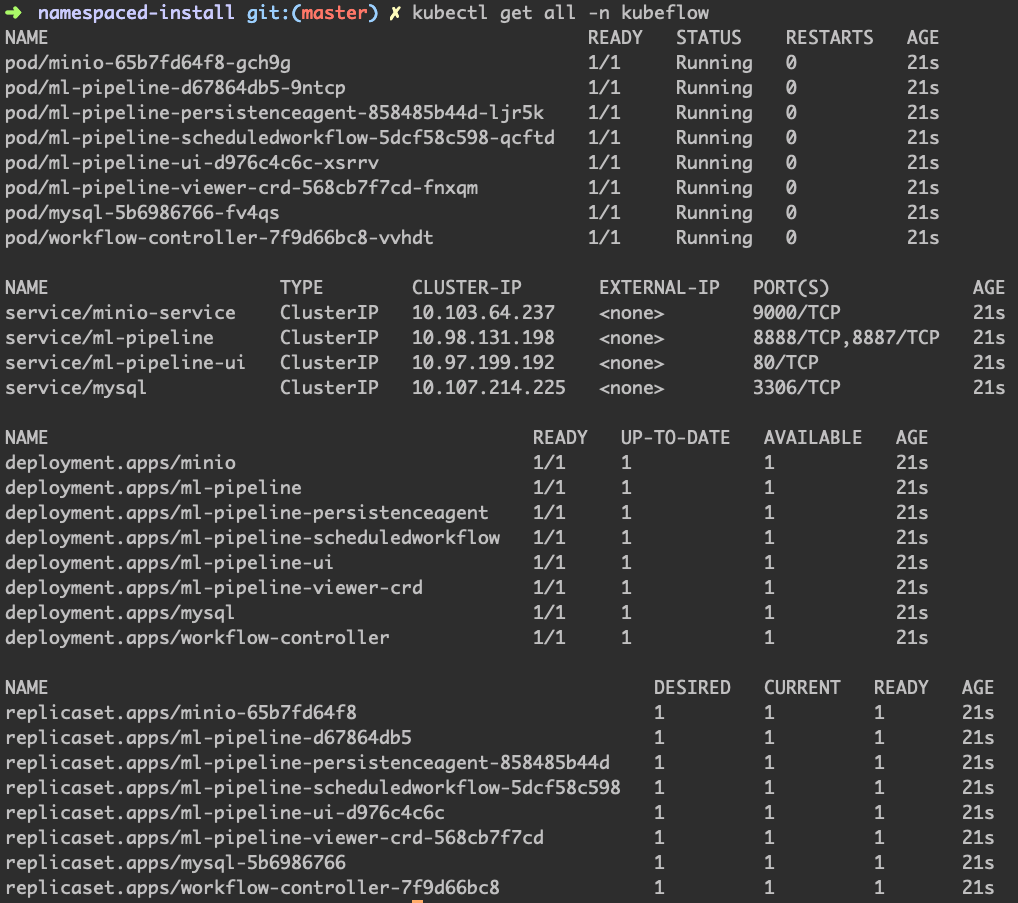
这是部署的过程。建议详细看看部署了什么资源。
部署成功之后的 UI 还是相当简洁的。
举个例子,Conditional execution,也就是条件运行的一个 Pipeline。
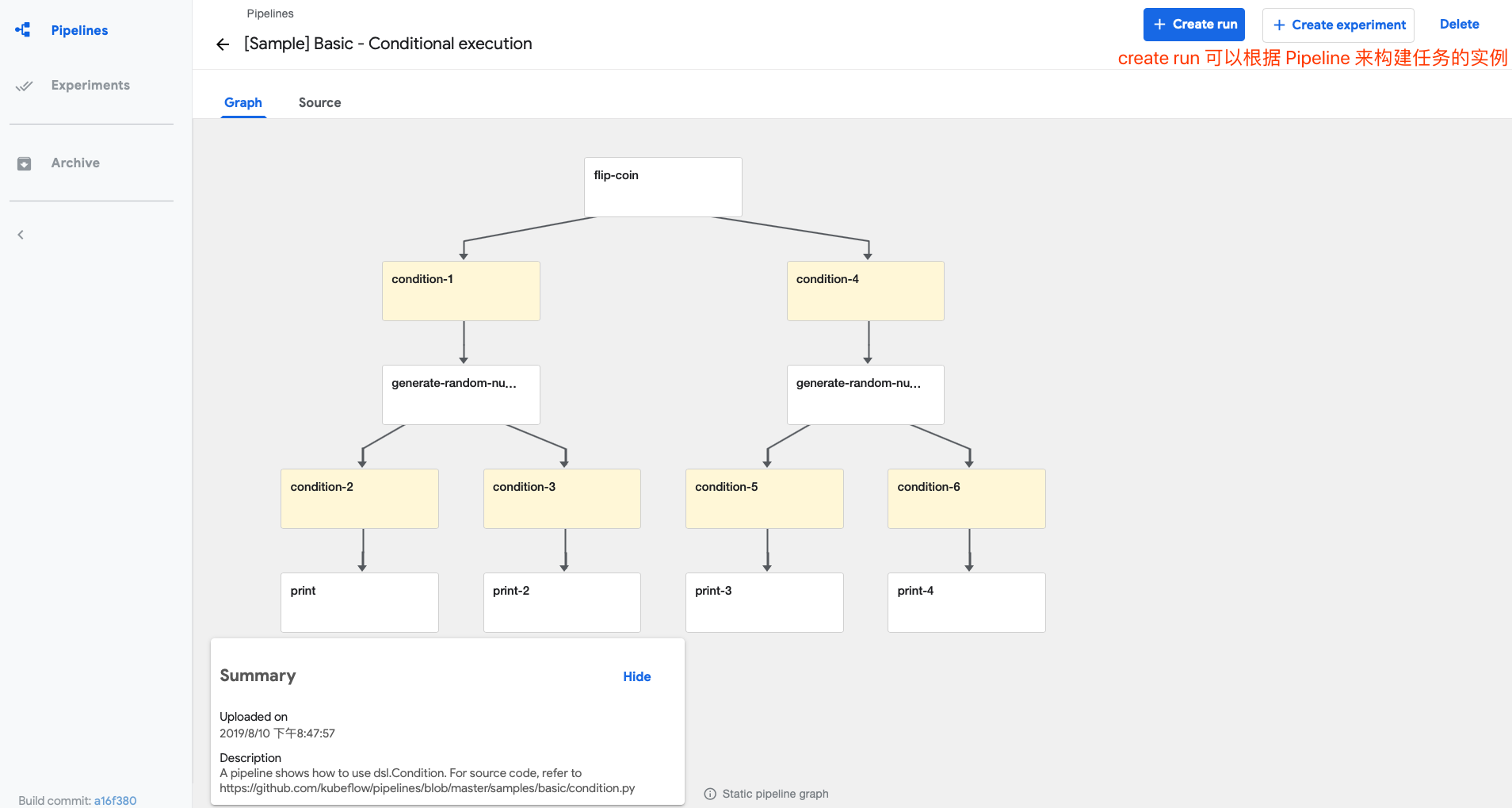
整个 Pipeline 是一个有向无环图,不过他有一些条件,比如说满足 condition1 会走左分支。
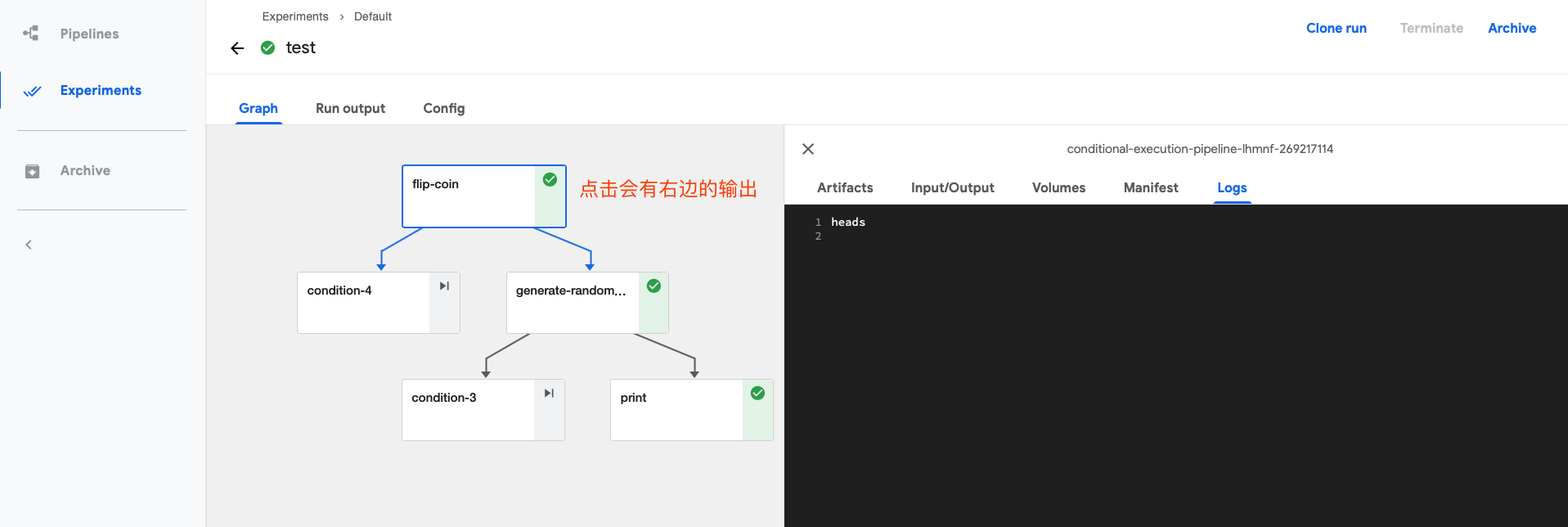
总结
Pipeline 是基于 Argo 来做的,本质是一个容器工作流,所以背后的 Run 实际上都是一些容器。Pipeline 可以帮助用户构建机器学习的任务流,通过组成 DAG 来串联起数据处理的过程,不过在描绘 Pipeline 的时候,需要用到该项目提供的 Python SDK,这是需要一定的学习成本的,虽然官网也提供了一些教程,但是总体而言,还是有点麻烦,暂时还不确定是否可以在 DAG 中加入时间调度的因素,后面还会继续展开。
参考资料
警告
本文最后更新于 2017年2月1日,文中内容可能已过时,请谨慎参考。