Kubeflow-Pipeline构建自定义的Workflow
目录
概述
要把 Kubeflow 的 Pipeline 用溜了,肯定是需要有自定义 Pipeline 的能力了,所以需要熟悉一下 Pipeline 里的一些概念。
如果要搞清楚 Pipeline,👇这些文档都必须要读一下,否则你是不清楚怎么利用 Kubeflow 团队提供的 SDK 来构建自己的容器工作流的。
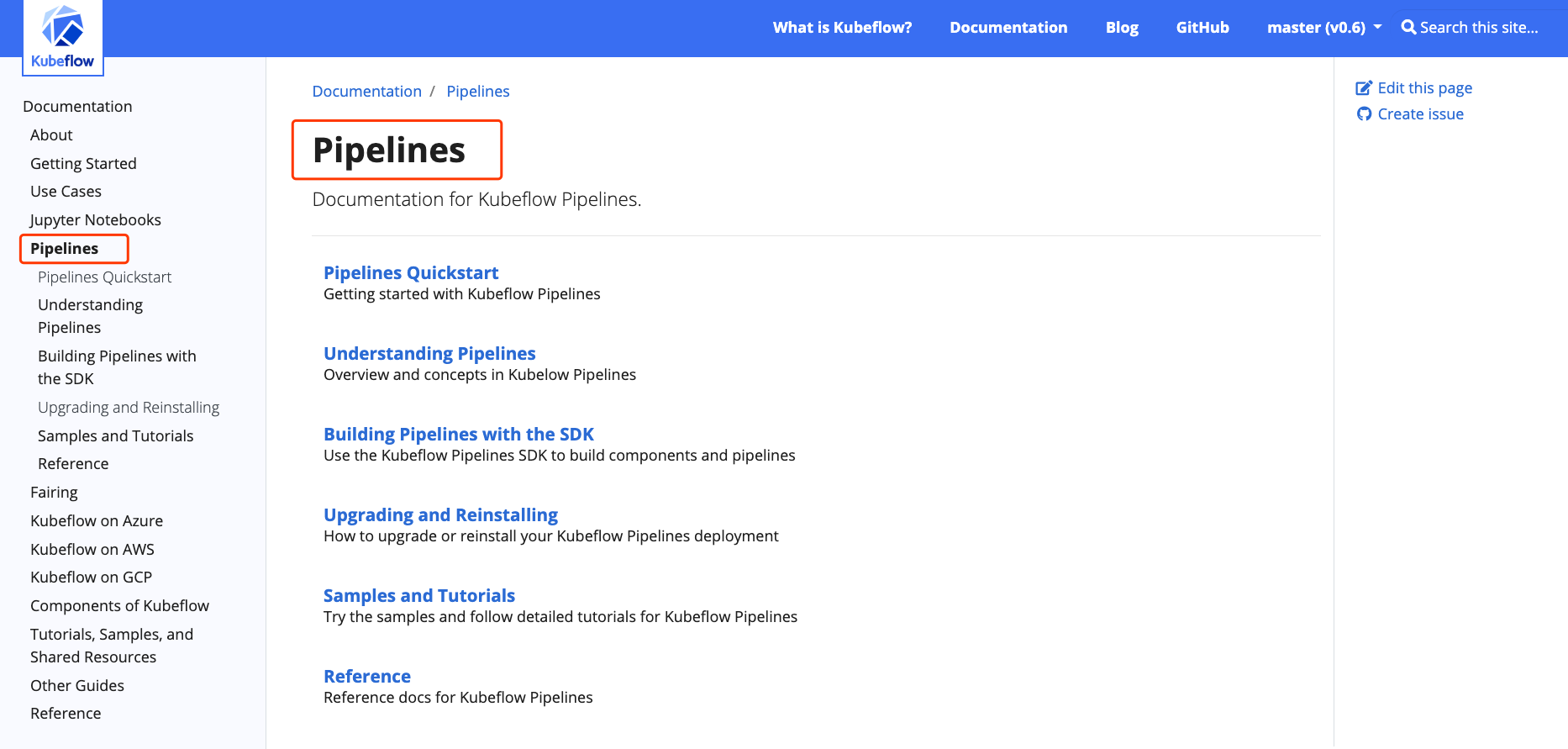
本文的目标就是构建一个简单并且本地可用的 Pipeline。
P.S. 这里先不涉及做机器学习的流程
步骤
理解component和pipeline
A -> B -> C
👆这个流程可以理解成 pipeline,A, B, C 分别就是 component。
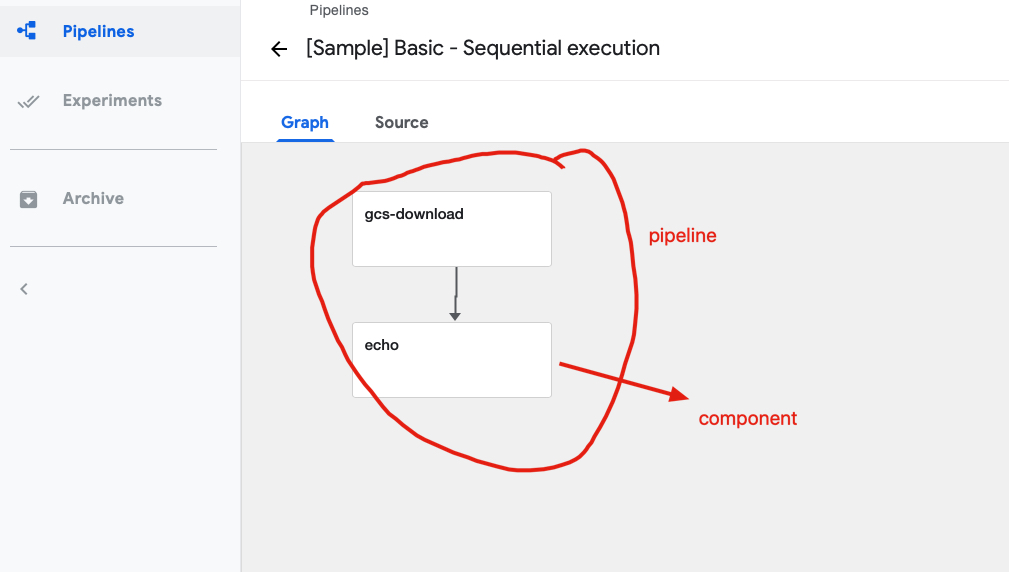
pipeline 可以只有一个 component。
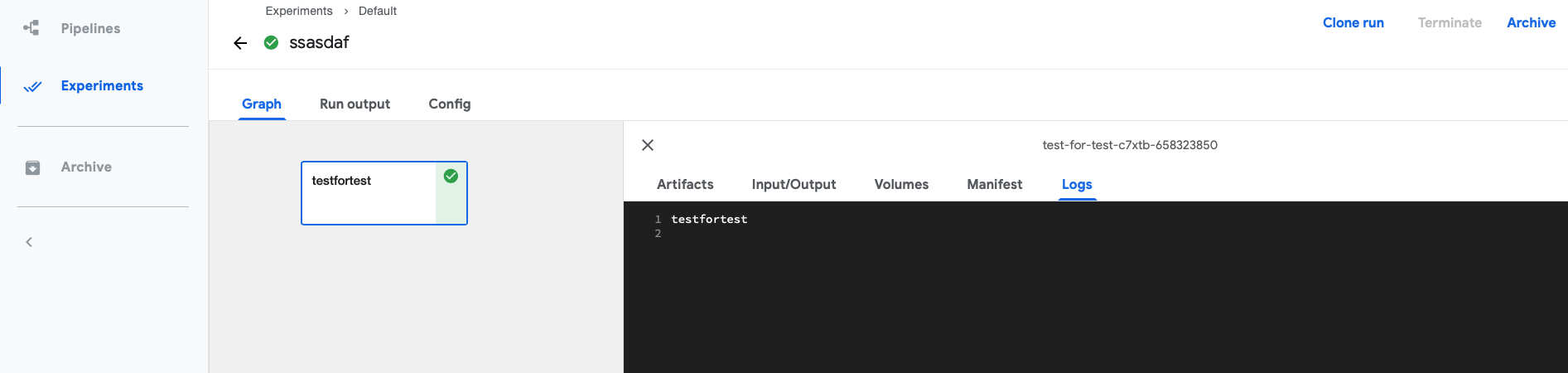
Python SDK构建component和pipeline
假设现在你想写一个机器学习的 pipeline,大概抽象成👇几个步骤。
要构建完整的 pipeline,需要先考虑构建每个步骤 component 的问题。
构建 pipeline 可以有几种方式,区别在于是否将 Python SDK 的代码嵌入到业务代码里。因为如果你本来就写好了一个 training 的程序,那么这时候就可以直接利用 Docker 镜像,将业务代码封装成一个镜像,无需侵入。另一种方法就是边写 training 程序的时候边
警告
本文最后更新于 2017年2月1日,文中内容可能已过时,请谨慎参考。