1 Overview
前面文章介绍过如何通过 Pipeline 来构建工作流,因为 Kubeflow 主要是在机器学习的场景下使用的,那么本文就简单介绍一下怎么构建一个简单 ML 的工作流。
官网的给出的例子不是太直观,而且和 GCP 有比较强的耦合,不过仔细看看文档,还是可以总结出一套简单的方案的。提前说明一下,需要的工作并不会很多。

2 ML Workflow
首先准备一段 Training 的代码,这是一段很经典的 mnist 数据集训练的代码。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
from __future__ import absolute_import, division, print_function, \
unicode_literals
import tensorflow as tf
def train_model():
mnist = tf.keras.datasets.mnist
# 下载 mnist 数据集,可以离线提前下载后填写路径
# 不填就要走公网下载数据了,数据量不大,十多兆
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(x_train, y_train, epochs=5)
model.evaluate(x_test, y_test)
if __name__ == '__main__':
train_model()
|
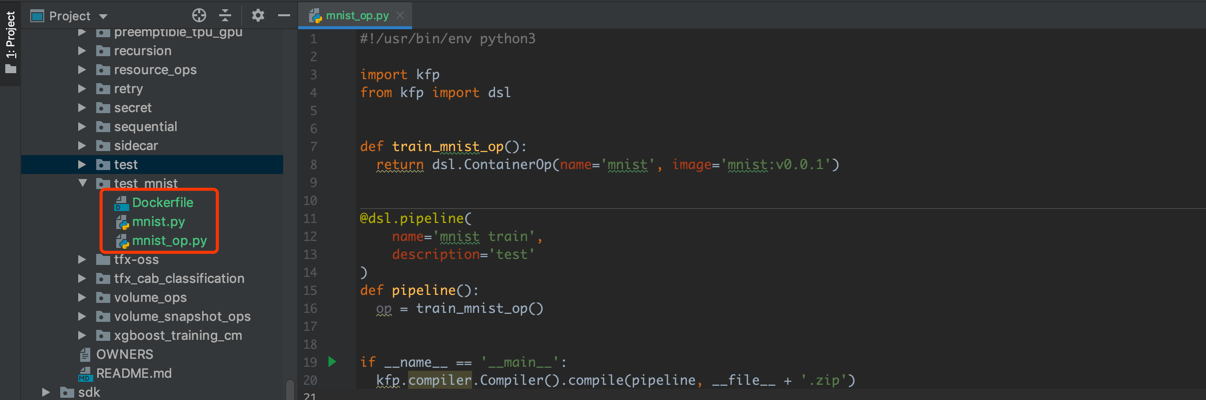
明确一下目标,我们需要把这个训练过程,放在 Pipeline 上运行,所以我们会将👆的代码封装成一个 component,然后再构架 pipeline,这里会了方便,依然是构建一个包含一个 component 的 pipeline。
按照官方文档,可以通过其提供的 Python SDK,将这个 component 转化为可以通过 UI 上传的 zip 文件。
https://www.kubeflow.org/docs/pipelines/sdk/sdk-overview/
这里还是提供了两种方法,将代码封装成 component 的,一种是将你的代码用 Docker 镜像封装,另一种就是通过 Python SDK 来侵入代码,通过 Python 直接完成 build 和 push,反正不管怎样,本质上都会被封装成一个镜像,毕竟跑在 Pipeline 上的都是容器。
可以参考我编的 Dockerfile。
1
2
3
|
FROM tensorflow/tensorflow:1.14.0-py3
ADD mnist.py .
ENTRYPOINT ["python", "mnist.py"]
|
还有转成 zip 文件的 pipeline 构建代码。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
#!/usr/bin/env python3
# mnist_op.py
import kfp
from kfp import dsl
def train_mnist_op():
return dsl.ContainerOp(name='mnist', image='mnist:v0.0.1')
@dsl.pipeline(
name='mnist train',
description='test'
)
def pipeline():
op = train_mnist_op()
if __name__ == '__main__':
kfp.compiler.Compiler().compile(pipeline, __file__ + '.zip')
|
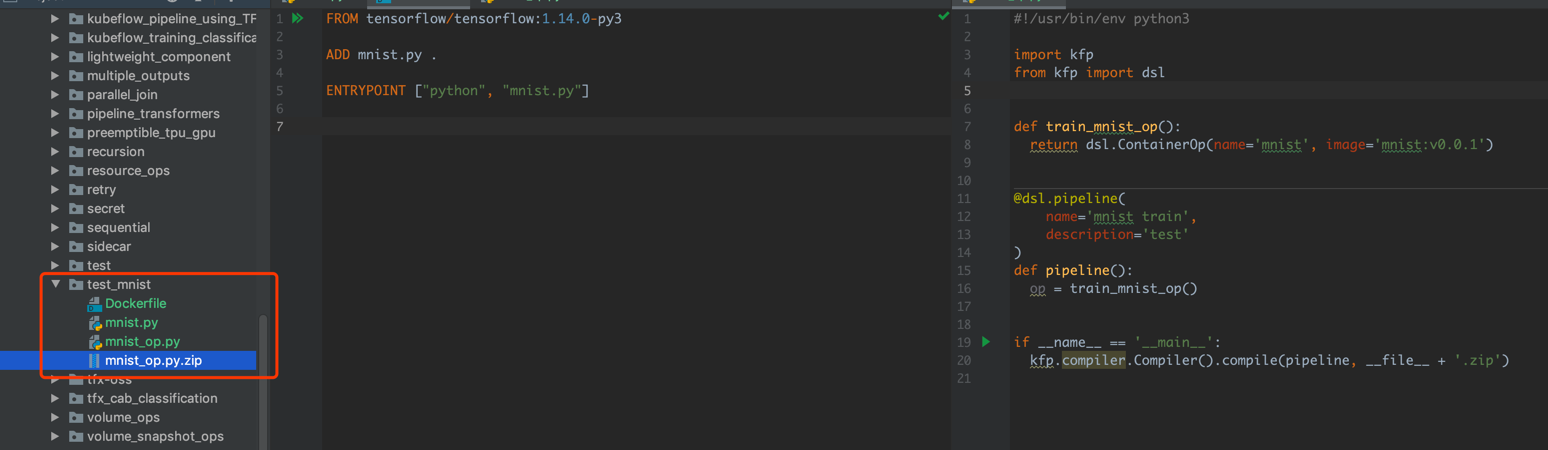
然后在目录下,运行 docker build -t mnist:v0.0.1 .,就完成镜像的构建了。然后就是运行代码构建 zip 文件。
1
|
dsl-compile --py mnist_op.py --output mnist_op.py.zip
|
结果如下。
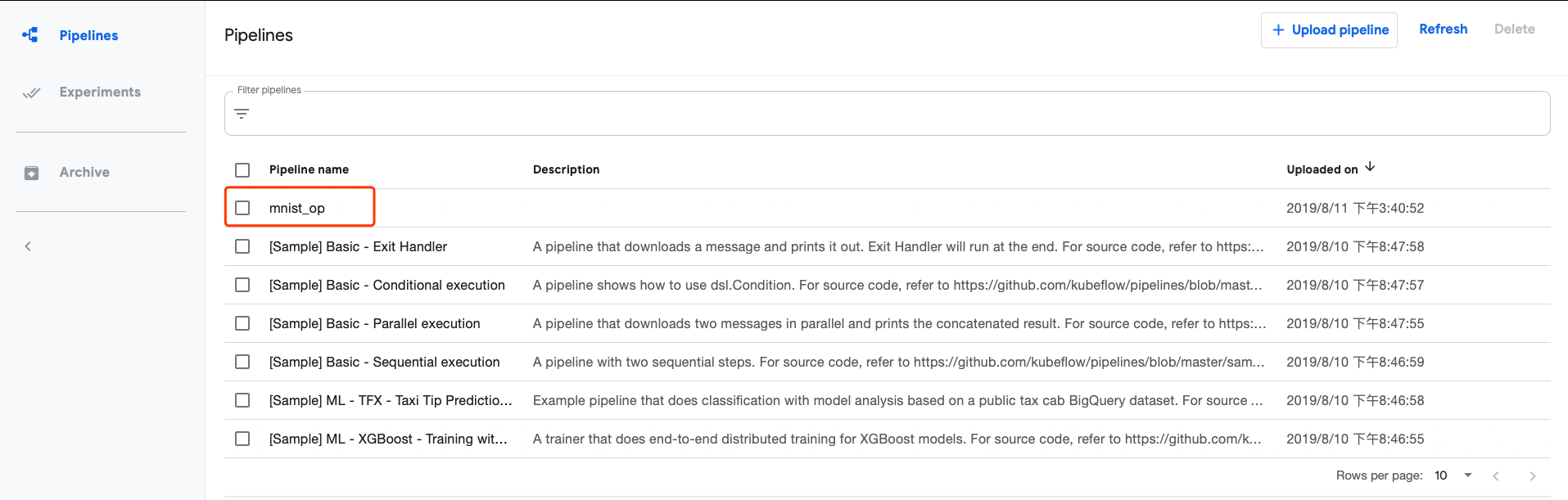
通过 Pipeline UI 上传。
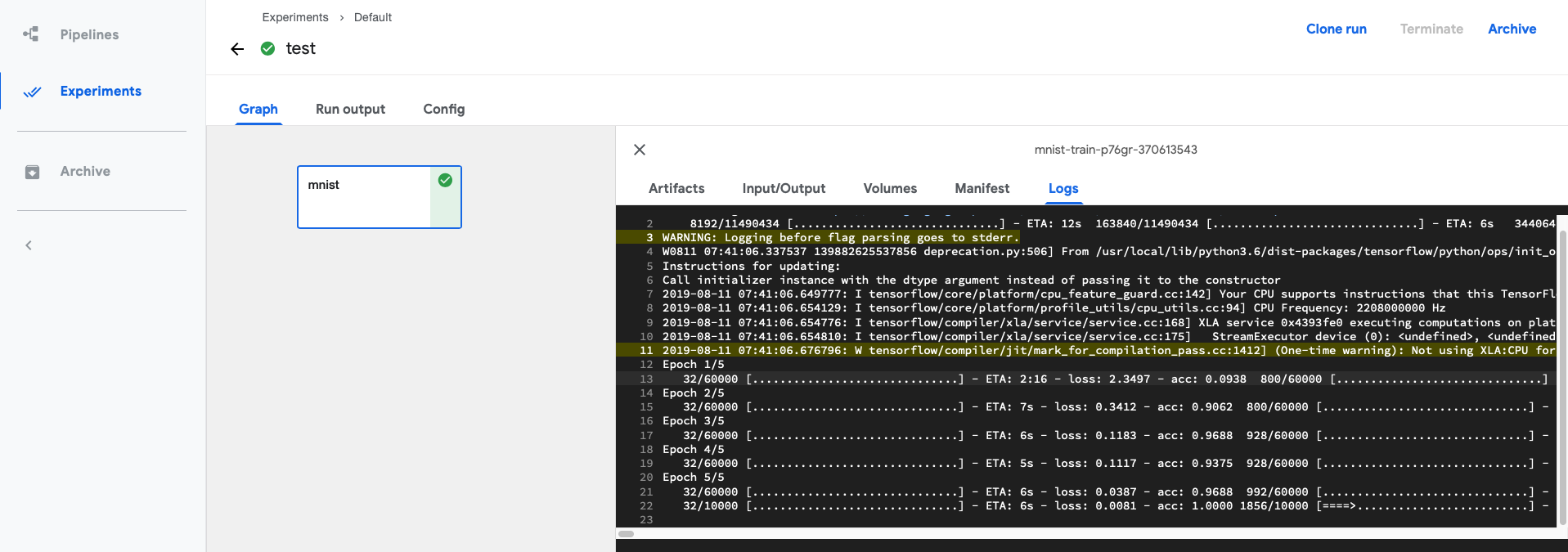
创建 Run,并查看结果。
总结
按照👆的流程,应该就可以创建一个非常简答的 ML Pipeline 了,当然一个完整的流程,会切分成读取数据,清洗数据(Transform),训练,然后输出模型,大家可以按照上述的访问,分别构建 component,然后最终构建起自己的 pipeline。
警告
本文最后更新于 2017年2月1日,文中内容可能已过时,请谨慎参考。