概述
Pipeline 提供了几个内置的 Pipeline……有点绕口,但是真正使用的时候,但是默认提供的几个 Pipeline 都要基于 GCP Google 的云平台,但是我们的目的是在自己的集群部署,自然是访问不到 GCP 的,所以根据官网,总结了一些构建 Pipeline 的流程。
理解Pipeline
从官网文档了解,什么是 Pipeline,看看定义还是非常有使用价值的。

首先,数据科学家本身就是在提数据,训练,保存模型,部署模型几个重要环节中工作,Pipeline 提供了一个很友好的 UI 来给数据科学家来定义整个过程,而且整个过程是运行在 K8S 集群上的。这对于一些对资源利用率有要求的公司,统一一层 K8S 来服务在线的应用和这些机器学习,还是很不错的。
通过定义这个 Pipeline,就可以定义环环相扣的机器学习 Workflow,市面是有很多类似的产品的,例如阿里云,腾讯云都有,但是都不全是基于 K8S 来做的。然后 Pipeline 也提供了相关的工具来定义这个 Pipeline,不过都是 Python 的,当然这个对于数据科学家来说,不会是什么问题。最后就是,Pipeline 在 Kubeflow 的生态内,结合 Notebook,数据科学家甚至都可以不用跳出去 Kubeflow 来做其他操作,一站式 e2e 的就搞定了。
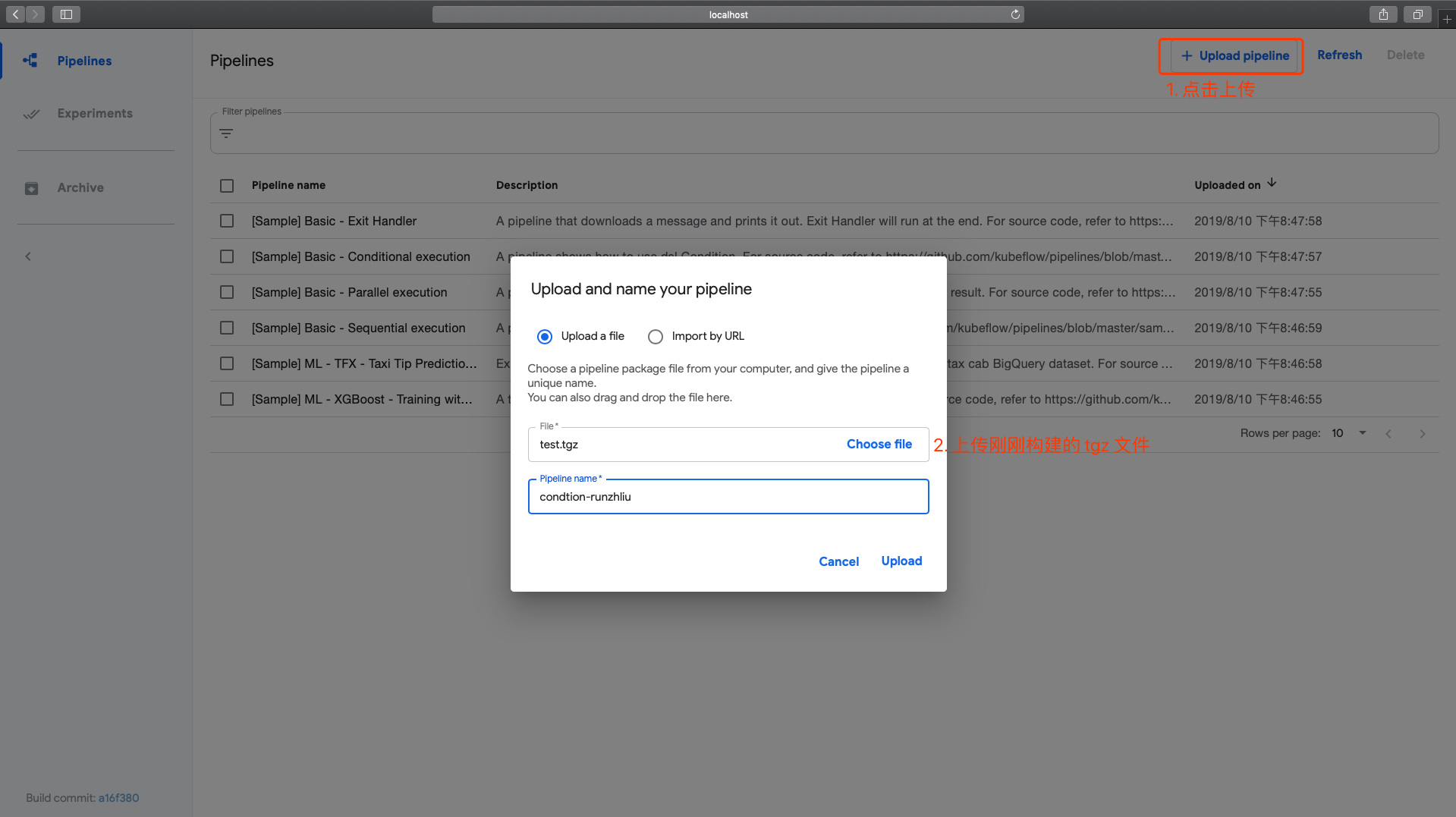
上传Pipeline
通过👇这个 Link,学习一下如何构建自己的 Pipeline 并且上传。
https://www.kubeflow.org/docs/pipelines/tutorials/build-pipeline/
主要包括几个步骤。
- 安装专门的SDK
- Python定义好Pipeline
- SDK构建pipeline的包,最后通过UI上传
请理解👇脚本每一步的含义。
1
2
3
4
|
# 下载官方的示例python代码来构建
git clone https://github.com/kubeflow/pipelines.git
# 实例代码在这里
cd pipelines/samples/core
|
分析一下这个例子的代码,留意一下里面的注释。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
|
## 省略了 License
import kfp
from kfp import dsl
def random_num_op(low, high):
"""Generate a random number between low and high."""
return dsl.ContainerOp(
name='Generate random number',
image='python:alpine3.6',
command=['sh', '-c'],
arguments=['python -c "import random; print(random.randint($0, $1))" | tee $2', str(low), str(high), '/tmp/output'],
file_outputs={'output': '/tmp/output'}
)
def flip_coin_op():
"""Flip a coin and output heads or tails randomly."""
return dsl.ContainerOp(
name='Flip coin',
image='python:alpine3.6',
command=['sh', '-c'],
arguments=['python -c "import random; result = \'heads\' if random.randint(0,1) == 0 '
'else \'tails\'; print(result)" | tee /tmp/output'],
file_outputs={'output': '/tmp/output'}
)
def print_op(msg):
"""Print a message."""
return dsl.ContainerOp(
name='Print',
image='alpine:3.6',
command=['echo', msg],
)
@dsl.pipeline(
## 这是你 Pipeline 的名字和描述
## 为了和默认的 Condition 那个例子有所区别,这里更改了 name 和 description。
name='test test name',
description='just test'
)
def flipcoin_pipeline():
## 这里面就是从上到下来设计这个 Pipeline 了,先做什么后做什么
## 或者有条件限制的话就做跳转
flip = flip_coin_op()
## 如果 flip 这个值等于 heads 就走这个分支
## 这是 SDK 定义的 API,想用好 Pipeline,除了简单的按顺序写方法
## 还有像条件控制这样的魔法
with dsl.Condition(flip.output == 'heads'):
## 又是一个条件,就不赘述了
random_num_head = random_num_op(0, 9)
with dsl.Condition(random_num_head.output > 5):
print_op('heads and %s > 5!' % random_num_head.output)
with dsl.Condition(random_num_head.output <= 5):
print_op('heads and %s <= 5!' % random_num_head.output)
## 如果 flip 这个值等于 tails 就走这个分支
with dsl.Condition(flip.output == 'tails'):
random_num_tail = random_num_op(10, 19)
with dsl.Condition(random_num_tail.output > 15):
print_op('tails and %s > 15!' % random_num_tail.output)
with dsl.Condition(random_num_tail.output <= 15):
print_op('tails and %s <= 15!' % random_num_tail.output)
if __name__ == '__main__':
## 最后就是保存这个 Pipeline 了
kfp.compiler.Compiler().compile(flipcoin_pipeline, __file__ + '.zip')
|
了解了如何通过 Pipeline 提供的 SDK 来构建工作流之后,还需要通过 pip 来下载一些工具,方便直接转换你写的 pipeline 文件。假设你已经有 Python3 环境了那么就装包就行了。
https://www.kubeflow.org/docs/pipelines/sdk/install-sdk/#install-the-kubeflow-pipelines-sdk
1
2
3
4
|
## 安装
pip install https://storage.googleapis.com/ml-pipeline/release/0.1.20/kfp.tar.gz --upgrade
## 检查一下安装成功了没
which dsl-compile
|
确定一下,所在的目录,然后就可以搞起来了。
然后就是上传了。
总结
如果有需要深度使用 Pipeline 的同学,建议看看其 SDK。本质上,构建出来的 Pipeline 文件是一个 基于 Argo 的一个定义 Workflow 的 YAML 文件。
警告
本文最后更新于 2017年2月1日,文中内容可能已过时,请谨慎参考。