概述
调研 KEDA 的使用方式。
了解HPA
Kubernetes 本身就有 HPA 的功能,可以参考下面的代码。下面是一个简单的 HPA 的例子,可以帮我们了解开源社区的 HPA 的使用方式。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: example-hpa
namespace: default
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: example-deployment # 需要扩缩容的 Deployment 名称
minReplicas: 1 # 最小副本数
maxReplicas: 10 # 最大副本数
metrics:
- type: Resource
resource:
name: cpu # 根据 CPU 使用率扩缩容
target:
type: Utilization # 目标类型为利用率
averageUtilization: 50 # 目标 CPU 利用率为 50%
|
在每个时间段内,控制器管理器都会根据每个 HorizontalPodAutoscaler 定义中指定的指标查询资源利用率。 控制器管理器找到由 scaleTargetRef 定义的目标资源,然后根据目标资源的 .spec.selector 标签选择 Pod, 并从资源指标 API(针对每个 Pod 的资源指标)或自定义指标获取指标 API(适用于所有其他指标)。
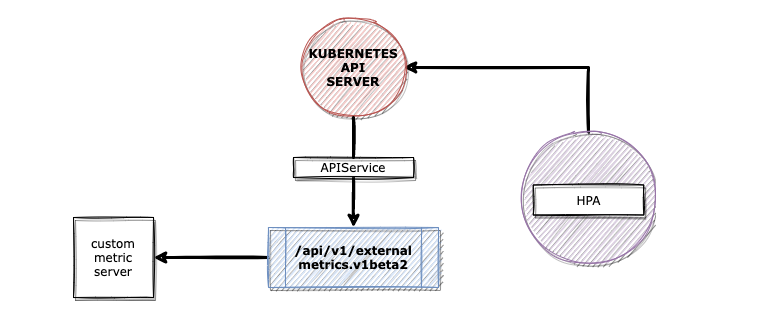
custom-metrics-apiserver
大部分场景下,可能只看 CPU/内存是不足够做 HPA 的依据的。
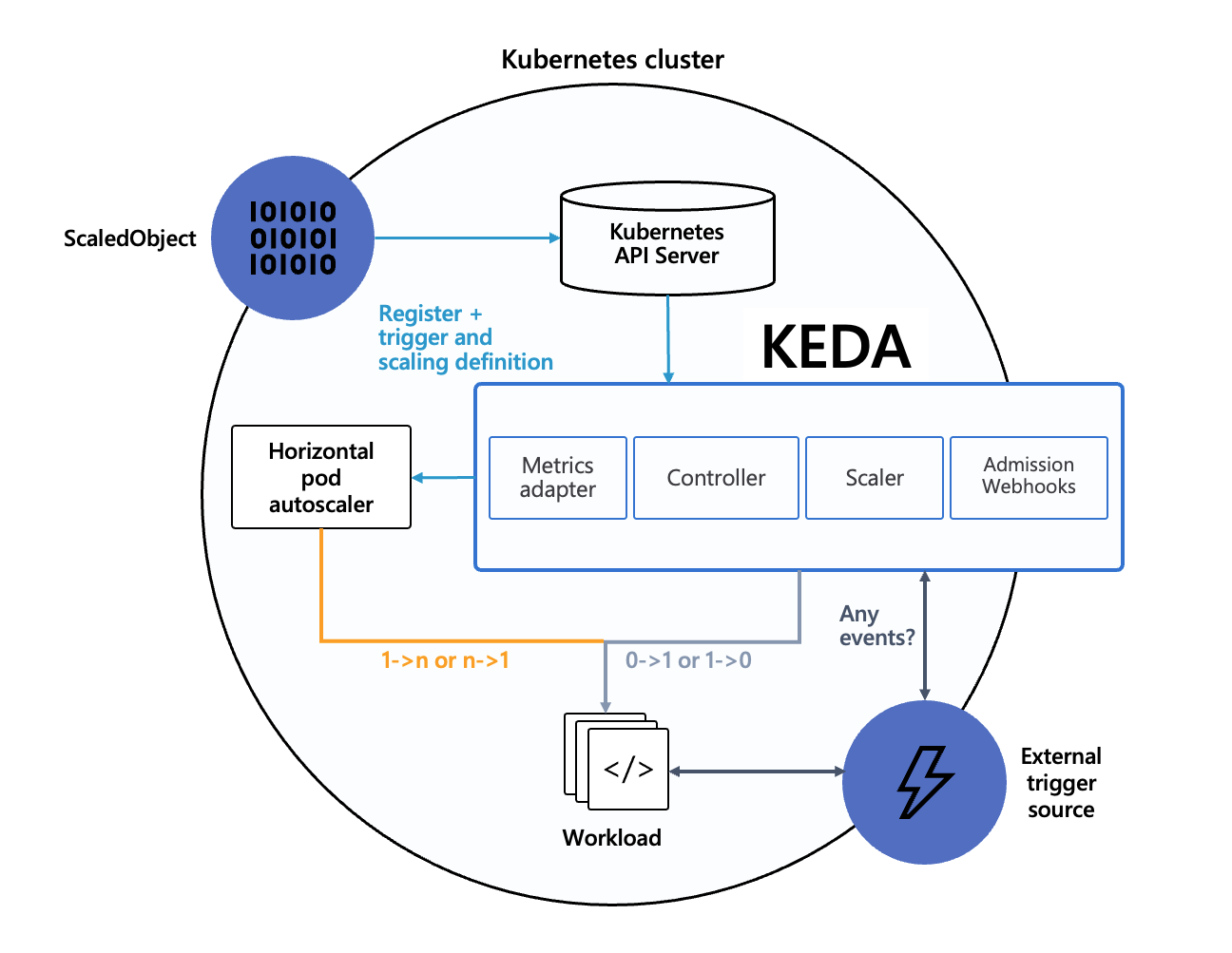
KEDA
KEDA 有下面几个组件,另外新版本中还有 Webhook 组件,主要是用于验证自定义对象的合法性,也可以不部署。
- Metrics Adapter: 将Scaler获取的指标转化成HPA可以使用的格式并传递给HPA,实现了hpa中external metrics,根据事件源配置返回计算结果
- Controller: 负责创建和更新一个HPA对象,并负责扩缩到零,在无事件的时候将副本数降低为0
- Scaler: 连接到外部组件,例如Kafka或者RabbitMQ并获取指标,例如,待处理消息队列大小等
关于 Kafka 的 Scaler,默认情况下,副本数量不会超过以下限制:
- 当指定了主题topic时,不会超过该主题的分区partition数量
- 当没有指定主题时,不会超过消费者组中所有主题的分区总数
- ScaledObject/ScaledJob中指定的maxReplicaCount值。如果未指定,则会考虑默认的maxReplicaCount值为5
- 如果设置了limitToPartitionsWithLag=true,那么副本数量不会超过具有非零延迟的分区数量。也就是说,即使maxReplicaCount设置的值大于分区数量,扩缩器Scaler也不会扩展到目标的maxReplicaCount
有关禁用此默认行为的信息,请参阅下面的 allowIdleConsumers,这是因为如果消费者的数量超过了主题的分区数量,多余的消费者将不得不保持空闲。

安装
1
2
3
4
|
# Kubernetes 1.20.3
helm install keda kedacore/keda --namespace keda --create-namespace --version 2.8.0
# Kubernetes 1.30.4
helm install keda kedacore/keda --namespace keda --create-namespace --version 2.15.1
|
镜像准备
1
2
3
4
5
6
7
|
# 2.8.0还没有webhook
docker pull ghcr.io/kedacore/keda:2.8.0
docker pull ghcr.io/kedacore/keda-metrics-apiserver:2.8.0
docker pull ghcr.io/kedacore/keda:2.16.1
docker pull ghcr.io/kedacore/keda-admission-webhooks:2.16.1
docker pull ghcr.io/kedacore/keda-metrics-apiserver:2.16.1
|
Staging环境部署
1
2
|
# helm install keda . --namespace keda --create-namespace -f db-values.yaml
Error: INSTALLATION FAILED: chart requires kubeVersion: >=v1.23.0-0 which is incompatible with Kubernetes v1.20.3-vip.1
|
首先是版本问题,Staging 环境的 Kubernetes 版本是 1.20.3,KEDA 2.15 需要 1.23.0 以上的版本,为了更好的兼容性,选择 2.8.0 版本,2.8.0 版本没有 webhook,所以不需要额外的配置。
参考上图,可以知道 KEDA 的架构,Metrics Adapter 会将 Scaler 获取的指标转化成 HPA 可以使用的格式并传递给 HPA,然而 HPA 是要通过 v1beta1.external.metrics.k8s.io 访问 Metrics Adapter 的,而在 Kubernetes 上的标准做法是 HPA 通过 in-cluster 的方式,以 Service 方式访问 kube-apiserver,然后 kube-apiserver 还需要以 Service 的方式访问 Metrics Adapter,这样就会有一个问题,公司内部的 Service 虽然可以通过 Cilium 进行补充,但是对于存量集群,是无法在物理机上部署 Cilium,让 kube-apiserver 可以正常访问 Metrics Adapter 的 Service,因此部署完毕后,还是会遇到以下这样的问题。
1
2
3
4
5
6
7
8
9
10
|
# k get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
keda-operator-cc866c7dd-2jmrx 1/1 Running 0 7m6s 10.189.78.176 10.189.212.124 <none> <none>
keda-operator-metrics-apiserver-676dfd8fdc-sbtw9 1/1 Running 0 7m6s 10.189.78.178 10.189.212.124 <none> <none>
# k get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
keda-operator-metrics-apiserver ClusterIP 10.200.156.82 <none> 443/TCP,80/TCP 7m8s
# k get apiservice v1beta1.external.metrics.k8s.io
NAME SERVICE AVAILABLE AGE
v1beta1.external.metrics.k8s.io keda/keda-operator-metrics-apiserver False (FailedDiscoveryCheck) 7m48s
|
可以看到,keda/keda-operator-metrics-apiserver 是 False 状态的,通过 kubectl 查询接口,也可以验证问题。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
# k get --raw "/apis/external.metrics.k8s.io/v1beta1" | jq .
Error from server (ServiceUnavailable): the server is currently unable to handle the request
# k describe apiservice v1beta1.external.metrics.k8s.io
Name: v1beta1.external.metrics.k8s.io
Namespace:
...
Kind: APIService
...
Spec:
Group: external.metrics.k8s.io
Group Priority Minimum: 100
Insecure Skip TLS Verify: true
Service:
Name: keda-operator-metrics-apiserver
Namespace: keda
Port: 443
Version: v1beta1
Version Priority: 100
Status:
Conditions:
Last Transition Time: 2025-02-19T08:47:29Z
Message: failing or missing response from https://10.200.156.82:443/apis/external.metrics.k8s.io/v1beta1: Get "https://10.200.156.82:443/apis/external.metrics.k8s.io/v1beta1": context deadline exceeded (Client.Timeout exceeded while awaiting headers)
Reason: FailedDiscoveryCheck
Status: False
Type: Available
|
这个问题是因为 kube-apiserver 无法访问 Metrics Adapter 的 Service,这个是 Staging 环境,甚至是我们生产大部分集群的问题!解决这个问题最好的方式,当然是升级集群,让全集群都可以支持 Service,但在 Staging 集群下,为了测试通过,可以考虑用 iptables 硬改。
1
2
3
4
5
6
7
8
9
10
11
12
13
|
# 将kube-apiserver节点上的流量通过iptables转发到具体的Pod
iptables -t nat -A PREROUTING -p tcp -d 10.200.156.82 --dport 443 -j DNAT --to-destination 10.189.78.178:6443
iptables -t nat -A POSTROUTING -p tcp -d 10.189.78.178 --dport 6443 -j MASQUERADE
iptables -t nat -A OUTPUT -p tcp -d 10.200.156.82 --dport 443 -j DNAT --to-destination 10.189.78.178:6443
iptables -t nat -L -n -v
curl -k -v https://10.200.156.82:443/apis/external.metrics.k8s.io/v1beta1
# 取消iptables规则
iptables -t nat -D PREROUTING -p tcp -d 10.200.156.82 --dport 443 -j DNAT --to-destination 10.189.78.178:6443
iptables -t nat -D POSTROUTING -p tcp -d 10.189.78.178 --dport 6443 -j MASQUERADE
iptables -t nat -D OUTPUT -p tcp -d 10.200.156.82 --dport 443 -j DNAT --to-destination 10.189.78.178:6443
iptables -t nat -L -n -v
curl -k -v https://10.200.156.82:443/apis/external.metrics.k8s.io/v1beta1
|
执行完上面的操作之后,现在 kube-apiserver 就可以访问 Metrics Adapter 的 Service 了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
# k get apiservice v1beta1.external.metrics.k8s.io
NAME SERVICE AVAILABLE AGE
v1beta1.external.metrics.k8s.io keda/keda-operator-metrics-apiserver True 14m
# k get --raw "/apis/external.metrics.k8s.io/v1beta1" | jq .
{
"kind": "APIResourceList",
"apiVersion": "v1",
"groupVersion": "external.metrics.k8s.io/v1beta1",
"resources": []
}
# k describe apiservice v1beta1.external.metrics.k8s.io
Name: v1beta1.external.metrics.k8s.io
Namespace:
...
Spec:
Group: external.metrics.k8s.io
Group Priority Minimum: 100
Insecure Skip TLS Verify: true
Service:
Name: keda-operator-metrics-apiserver
Namespace: keda
Port: 443
Version: v1beta1
Version Priority: 100
Status:
Conditions:
Last Transition Time: 2025-02-19T09:02:03Z
Message: all checks passed
Reason: Passed
Status: True
Type: Available
Events: <none>
|
生产环境
要注意一下,需要确保你的 Kubernetes 参数符合 启用Kubernetes Apiserver标志 的要求。
1
2
3
4
5
6
7
|
--requestheader-client-ca-file=<path to aggregator CA cert>
--requestheader-allowed-names=front-proxy-client
--requestheader-extra-headers-prefix=X-Remote-Extra-
--requestheader-group-headers=X-Remote-Group
--requestheader-username-headers=X-Remote-User
--proxy-client-cert-file=<path to aggregator proxy cert>
--proxy-client-key-file=<path to aggregator proxy key>
|
测试和验证
部署下面的 Deployment 和 ScaledObject,注意这个 ScaledObject 的含义是查询 Staging 环境的 Prometheus 获取 sum(container_cpu_usage_seconds_total{pod="kube-prometheus-stack-kube-state-metrics-7c76bcf9d-d277k"}) 这个指标,然后会对比 threshold 的值,然后按照比例决定扩缩容的实例数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
apiVersion: apps/v1
kind: Deployment
metadata:
name: test
labels:
app: test
spec:
replicas: 1
selector:
matchLabels:
app: test
template:
metadata:
labels:
app: test
spec:
containers:
- name: test
image: runzhliu/network-multitool:latest
---
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: cpu-scaler
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: test
minReplicaCount: 1
maxReplicaCount: 5
triggers:
- type: prometheus
metadata:
serverAddress: http://10.189.94.109:9090
metricName: container_cpu_usage_seconds_total
query: sum(container_cpu_usage_seconds_total{pod="kube-prometheus-stack-kube-state-metrics-7c76bcf9d-d277k"})
threshold: "1"
|
我们分别查看 ScaledObject 和 HPA 和 Deployment 的状态。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
|
# k get so
NAME SCALETARGETKIND SCALETARGETNAME MIN MAX TRIGGERS AUTHENTICATION READY ACTIVE FALLBACK AGE
cpu-scaler apps/v1.Deployment test 1 5 prometheus True True False 46s
# k get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
keda-hpa-cpu-scaler Deployment/test 5490133m/1 (avg) 1 5 1 35s
# k get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE
keda-operator-cc866c7dd-2jmrx 1/1 Running 0 26m 10.189.78.176 10.189.212.124
keda-operator-metrics-apiserver-676dfd8fdc-sbtw9 1/1 Running 0 26m 10.189.78.178 10.189.212.124
test-69dbc75dd-8gx9l 1/1 Running 0 16s 10.190.99.109 10.199.131.25
test-69dbc75dd-c5bhn 0/1 ContainerCreating 0 16s <none> 10.189.222.28
test-69dbc75dd-tpjlj 0/1 ContainerCreating 0 1s <none> 10.189.212.248
test-69dbc75dd-v8s62 1/1 Running 0 52s 10.83.225.164 10.83.220.99
test-69dbc75dd-x5v9g 1/1 Running 0 16s 10.190.133.62 10.189.212.6
# kubectl describe hpa keda-hpa-cpu-scaler
Name: keda-hpa-cpu-scaler
Namespace: keda
...
Annotations: autoscaling.alpha.kubernetes.io/conditions:
[{"type":"AbleToScale","status":"True","lastTransitionTime":"2025-02-19T09:13:25Z","reason":"ReadyForNewScale","message":"recommended size...
autoscaling.alpha.kubernetes.io/current-metrics:
[{"type":"External","external":{"metricName":"s0-prometheus-container_cpu_usage_seconds_total","metricSelector":{"matchLabels":{"scaledobj...
autoscaling.alpha.kubernetes.io/metrics:
[{"type":"External","external":{"metricName":"s0-prometheus-container_cpu_usage_seconds_total","metricSelector":{"matchLabels":{"scaledobj...
CreationTimestamp: Wed, 19 Feb 2025 17:13:10 +0800
Reference: Deployment/test
Min replicas: 1
Max replicas: 5
Deployment pods: 5 current / 5 desired
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulRescale 116s horizontal-pod-autoscaler New size: 4; reason: external metric s0-prometheus-container_cpu_usage_seconds_total(&LabelSelector{MatchLabels:map[string]string{scaledobject.keda.sh/name: cpu-scaler,},MatchExpressions:[]LabelSelectorRequirement{},}) above target
Normal SuccessfulRescale 101s horizontal-pod-autoscaler New size: 5; reason: external metric s0-prometheus-container_cpu_usage_seconds_total(&LabelSelector{MatchLabels:map[string]string{scaledobject.keda.sh/name: cpu-scaler,},MatchExpressions:[]LabelSelectorRequirement{},}) above target
# k get --raw "/apis/external.metrics.k8s.io/v1beta1/namespaces/keda/s0-prometheus-container_cpu_usage_seconds_total" | jq .
{
"kind": "ExternalMetricValueList",
"apiVersion": "external.metrics.k8s.io/v1beta1",
"metadata": {},
"items": [
{
"metricName": "s0-prometheus-container_cpu_usage_seconds_total",
"metricLabels": null,
"timestamp": "2025-02-19T09:18:28Z",
"value": "5491464m"
}
]
}
|
可以看到 Test Deployment 有 5 个 Pod,这是因为我们的阈值是 1,而我们的指标是 5490133m,所以会扩容到 5 个 Pod,这个是我们预期的结果。
其他case
n-0
这个主要是测试一下 n 个实例缩容到0的情况,修改 ScaleObject 的 minReplicaCount 为 0,然后再次部署。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: cpu-scaler
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: test
minReplicaCount: 0
maxReplicaCount: 5
triggers:
- type: prometheus
metadata:
serverAddress: http://10.189.94.109:9090
metricName: container_cpu_usage_seconds_total
query: sum(container_cpu_usage_seconds_total{job="xxx"}) or vector(0)
threshold: "1"
|
因为 Prometheus 在这里作为一个外部的 Scaler,因此当看到指标为0,是可以将目标的 Deployment 缩容到0的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
|
# k describe so cpu-scaler
Name: cpu-scaler
Namespace: keda
Labels: scaledobject.keda.sh/name=cpu-scaler
API Version: keda.sh/v1alpha1
Kind: ScaledObject
...
Spec:
Max Replica Count: 5
Min Replica Count: 0
Scale Target Ref:
API Version: apps/v1
Kind: Deployment
Name: test
Triggers:
Metadata:
Metric Name: container_cpu_usage_seconds_total
Query: sum(container_cpu_usage_seconds_total{job="xxx"}) or vector(0)
Server Address: http://10.189.94.109:9090
Threshold: 1
Type: prometheus
Status:
Conditions:
Message: ScaledObject is defined correctly and is ready for scaling
Reason: ScaledObjectReady
Status: True
Type: Ready
Message: Scaling is not performed because triggers are not active
Reason: ScalerNotActive
Status: False
Type: Active
Status: Unknown
Type: Fallback
External Metric Names:
s0-prometheus-container_cpu_usage_seconds_total
Hpa Name: keda-hpa-cpu-scaler
Original Replica Count: 1
Scale Target GVKR:
Group: apps
Kind: Deployment
Resource: deployments
Version: v1
Scale Target Kind: apps/v1.Deployment
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal KEDAScalersStarted 16s keda-operator Started scalers watch
Normal ScaledObjectReady 16s keda-operator ScaledObject is ready for scaling
Normal KEDAScaleTargetDeactivated 16s keda-operator Deactivated apps/v1.Deployment keda/test from 1 to 0
# k get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
keda-hpa-cpu-scaler Deployment/test <unknown>/1 (avg) 1 5 0 21s
# k get so
NAME SCALETARGETKIND SCALETARGETNAME MIN MAX TRIGGERS AUTHENTICATION READY ACTIVE FALLBACK AGE
cpu-scaler apps/v1.Deployment test 0 5 prometheus True False Unknown 25s
|
0-1
从 0 到 1 的话,同样可以使用上面的例子,当 vector(1) 生效的时候,就会将 Deployment 扩容到 1。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: cpu-scaler
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: test
minReplicaCount: 0
maxReplicaCount: 5
triggers:
- type: prometheus
metadata:
serverAddress: http://10.189.94.109:9090
metricName: container_cpu_usage_seconds_total
query: sum(container_cpu_usage_seconds_total{job="xxx"}) or vector(1)
threshold: "1"
|
多触发器(AND/OR 逻辑)
KEDA 支持为一个 ScaledObject 配置多个触发器,支持以下逻辑:
- OR逻辑(默认): 任意一个触发器满足条件时扩缩容
- AND逻辑: 所有触发器都满足条件时扩缩容
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: multi-trigger-scaler
namespace: keda
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: your-deployment
minReplicaCount: 0
maxReplicaCount: 10
triggers:
- type: prometheus
metadata:
serverAddress: http://prometheus-server:9090
metricName: http_requests_total
query: sum(rate(http_requests_total[5m]))
threshold: "10"
- type: rabbitmq
metadata:
host: "amqp://user:password@rabbitmq-host"
queueName: "your-queue"
queueLength: "5"
|
分批扩缩容
缩容是有 cooldownPeriod 参数可以控制缩容的延迟时间,从而避免快速缩容引发服务不稳定。如果扩容后负载快速下降,cooldownPeriod 会确保系统在指定时间内不会立即缩容,从而间接实现分批扩缩容的效果。当前对于扩容没有很好的办法,只能通过配置 pollingInterval 或者使用多个 ScaledObject 来控制。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: cooldown-scaler
namespace: keda
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: your-deployment
minReplicaCount: 1
maxReplicaCount: 10
cooldownPeriod: 300 # 缩容延迟 300 秒
triggers:
- type: prometheus
metadata:
serverAddress: http://prometheus-server:9090
metricName: http_requests_total
query: sum(rate(http_requests_total[5m])) or vector(0)
threshold: "10"
|
在 Kubernetes 1.20 中,由于 autoscaling/v1 还没有实现 behavior 字段,理想情况下在 Kubernetes 1.30.4,ScaledObject 可以通过 HPA 的 behavior 参数来实现分批扩缩容。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: cpu-scaler
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: test
minReplicaCount: 0
maxReplicaCount: 5
advanced: # Optional. Section to specify advanced options
restoreToOriginalReplicaCount: true # Optional. Default: false
horizontalPodAutoscalerConfig: # Optional. Section to specify HPA related options
behavior: # Optional. Use to modify HPA's scaling behavior
scaleDown:
stabilizationWindowSeconds: 300
policies:
- type: Percent
value: 100
periodSeconds: 15
triggers:
- type: prometheus
metadata:
serverAddress: http://10.189.94.109:9090
metricName: container_cpu_usage_seconds_total
query: sum(container_cpu_usage_seconds_total{job="xxx"}) or vector(1)
threshold: "1"
|
Scaler
对于我们的业务场景来看,下面几个原生的 Scaler 是比较有用的。
- Kafka: 直接对接VMS
- Prometheus: 可以对接线上的Prometheus
- Cron: 定时任务
对比HPA
- 反应时间
- 定时
- 可以暂停
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: example-scaler
namespace: default
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: your-deployment
minReplicaCount: 1
maxReplicaCount: 10
paused: true # 暂停扩缩容
triggers:
- type: prometheus
metadata:
serverAddress: http://prometheus-server:9090
metricName: http_requests_total
query: sum(rate(http_requests_total[5m])) or vector(0)
threshold: "10"
|
对比Knative
| 特性 |
Knative |
KEDA |
| 适用场景 |
- 事件驱动的无服务器(serverless)工作负载。
- 适用于 HTTP 请求触发的短生命周期应用、函数计算。 |
- 容器化的工作负载,尤其是需要自定义事件触发的场景(例如消息队列、数据库查询、外部指标)。 |
| 扩缩容能力 |
- 默认支持缩容到 0(当没有请求时)。
- 针对 HTTP 请求的自动扩缩容,延迟较低,适合实时性要求较高的应用。 |
- 支持缩容到 0,可以基于多种触发器(消息队列、Kafka、Prometheus、数据库等)扩缩容。
- 更灵活的触发器支持,适合复杂事件驱动场景。 |
| 触发器支持 |
- 仅支持基于 HTTP 请求的扩缩容(Knative Serving)。
- 支持 Knative Eventing 处理部分事件驱动场景,但需依赖额外组件(如 Broker 和 Trigger)。 |
- 支持多种触发器,包括 Prometheus、RabbitMQ、Kafka、Redis、AWS SQS、Azure Queue 等,事件来源非常丰富。 |
| 定制化 |
- 偏向标准化,功能较为固定,适合简化操作的无服务器场景。 |
- 高度可定制化,可以根据业务需求自由配置不同触发器和扩缩容逻辑(如阈值、冷却时间等)。 |
| 冷启动性能 |
- 冷启动时间较短,尤其是 Knative Serving 针对 HTTP 请求优化较好。 |
- 冷启动时间取决于容器启动速度和触发器响应时间,某些复杂触发器场景可能会导致冷启动时间较长。 |
| 事件处理能力 |
- Knative Eventing 支持事件的路由、分发和转换,但需要额外组件(Broker/Trigger),复杂性较高。 |
- 不具备事件路由功能,直接扩缩容目标工作负载,配置简单,性能高。 |
| 依赖性 |
- Knative 安装较重,依赖 Istio、Contour 等服务网格组件,非常依赖 Service。 |
- 轻量级,仅需 Operator 和 ScaledObject,无需复杂的服务网格依赖,External Metrics 依赖 Service。 |
| 社区生态 |
- 适配 Serverless 场景较多,生态完善(如 Tekton、Cloud Run)。 |
- 支持多种云服务和事件源,但生态成熟度略低于 Knative。 |
| 资源开销 |
- 由于依赖服务网格和事件路由组件,资源开销较大,适合中大型集群。 |
- 轻量级,资源开销小,适合小型集群和边缘场景。 |
| 易用性 |
- 安装与配置复杂度较高(尤其是 Knative Eventing),维护较难。 |
- 安装简单,主要通过 CRD(ScaledObject)配置触发器和扩缩容逻辑,入门门槛低。 |
| 优势 |
- 针对 HTTP 请求优化,冷启动性能好,标准化程度高,适合无服务器化需求。
- 社区生态广泛,Serverless 场景支持丰富。 |
- 支持多种触发器,扩缩容逻辑灵活。
- 轻量级,易于部署和管理,适用于事件驱动的多种场景。 |
| 劣势 |
- 仅适用于 HTTP 请求或需要额外组件(Knative Eventing)支持事件触发。
- 安装复杂,依赖多种服务网格组件,资源开销较大。 |
- 冷启动性能比 Knative 略低,尤其在复杂触发器场景下。
- 无原生的事件路由功能,需要结合其他工具实现更复杂的事件处理流程。 |
| 内部集成 |
- 最新版本不支持Kubernetes 1.20 |
- 最新版本不支持Kubernetes 1.20 |
业务场景
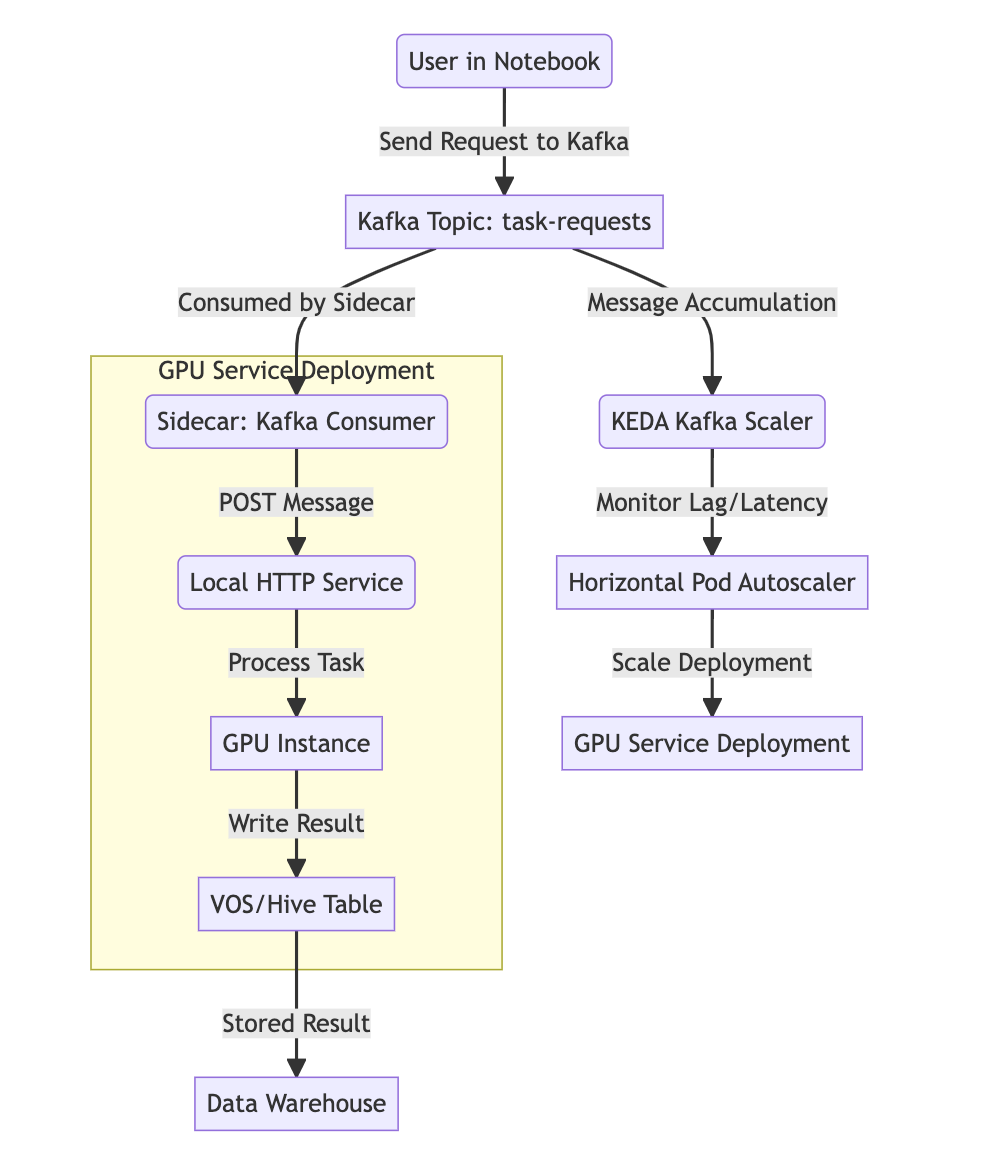
基于队列刷数
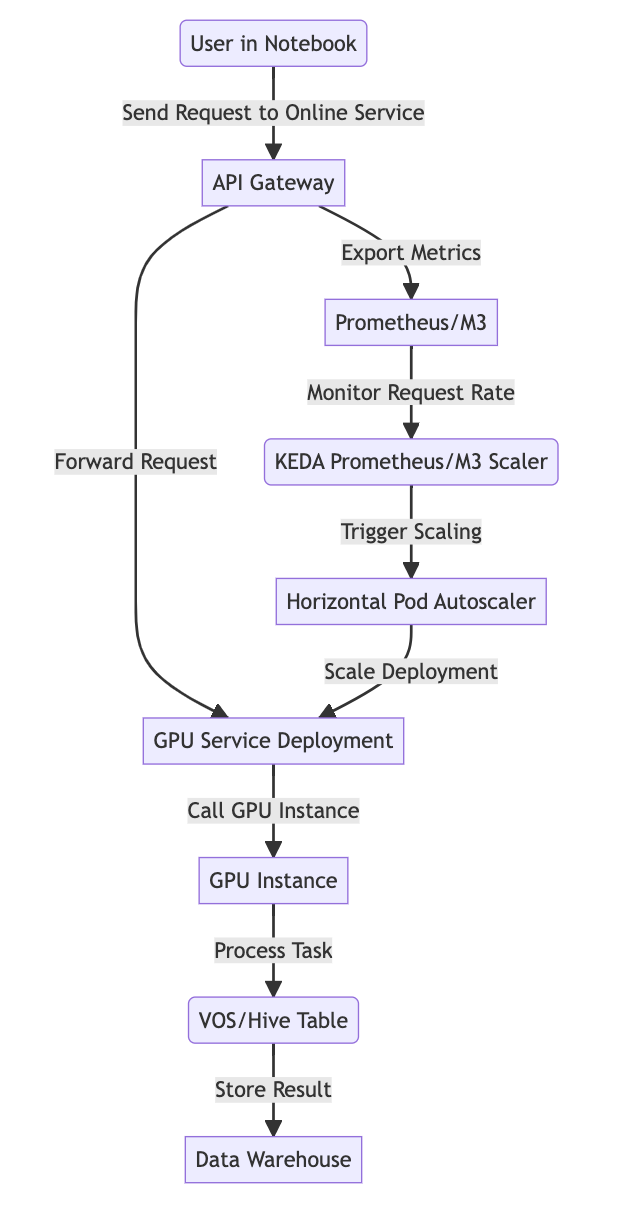
在线服务刷数
实现一个Scaler
- 基于M3
- 基于VMS
- 基于Janus的请求指标
参考资料
- KEDA vs HPA
- Kubernetes弹性扩缩容之HPA和KEDA
- 兼容性问题
- 如何通过Autoscaler实现Kubernetes的伸缩?
- KEDA 2.8
- Using KEDA to trigger HPA with Prometheus Metrics
- KEDA External Scaler for TencentCloud CLB
- Pod水平自动扩缩
- HorizontalPodAutoscaler演练
- Custom Metrics Apiserver
警告
本文最后更新于 2025年1月22日,文中内容可能已过时,请谨慎参考。