How-to-write-a-Hive-Hook
概述
最近在做元数据的管理和血缘分析,想从 Hive 入手,网上找到一篇介绍 Hive Hook 的博客,仔细看了下,很有启发。翻译了一下全文,原文链接在上面。
提起 Hive Hooks 很少人会想到可以拿他来做什么。本文主要介绍什么是 Hive Hook,以及怎么利用 Hive Hook 来做一些有意思的事情。
什么是Hive
对于刚刚接触 Hive 的用户来说,Hive 就是一个 Hadoop 的 SQL 接口。Hive 可以被认为是一个解析 SQL 并且转化为一系列的 MR/Tez/ Spark 任务的一个编译器。
下面的流程图和术语,解释了 Hive 是如何解析 SQL 并且利用 MR 作为执行引擎的。
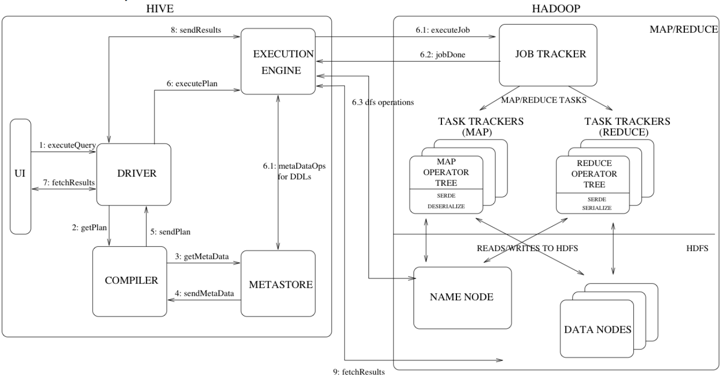
- Driver – 这个组件是用来接收来自 JDBC/ODBC 的查询语句。
- Compiler – 解释器用于解析 query,并且生成一个查询表达式,最终生成执行计划 execution plan。
- Metastore – 这个组件存储了所有的结构信息,包括列、列类型信息,序列化和反序列化还有 HDFS 文件的存储位置。
- Execution Engine – 执行引擎是用于执行 execution plan 的地方,这个执行计划是一个基于 stage 的 DAG。执行引擎维护着执行计划的所有依赖,以及将其放在合适的组件中执行。
什么是Hive Hook
Hook 是一种事件和消息机制,Hive Hook 可以将事件绑定在内部 Hive 的执行流程中,而无需重新编译 Hive。Hook 提供了扩展和继承外部组件的方式。根据不同的 Hook 类型,可以在不同的阶段运行。
- Pre-execution Hook 在执行引擎执行查询之前被调用。这个需要在 Hive 对查询计划进行过优化之后才可以使用。
- Post-execution hooks 在执行计划执行结束结果返回给用户之前被调用。
- Failure-execution hooks 在执行计划失败之后被调用。
- Pre-driver-run 和 post-driver-run 是在查询运行的时候运行的。
- Pre-semantic-analyzer and Post-semantic-analyzer Hook 在 Hive 对查询语句进行语义分析的时候调用。
Hive查询的生命周期
下面是关于 Hive 查询的生命周期。
- Driver.run() 接收命令。
- org.apache.hadoop.hive.ql.HiveDriverRunHook.preDriverRun() 读取 hive.exec.pre.hooks 中的配置,来看 pre 需要运行的 hook.
- org.apache.hadoop.hive.ql.Driver.compile() 开始处理 query,并且生成 AST。
- org.apache.hadoop.hive.ql.parse.AbstractSemanticAnalyzerHook 调用 preAnalyze() 方法。
- Semantic analysis AST 上的语义分析。
- org.apache.hadoop.hive.ql.parse.AbstractSemanticAnalyzerHook.postAnalyze() 在所有语义分析 Hook 方法执行完之后被调用。
- 创建物理查询计划。
- Driver.execute() 准备运行 job。
- org.apache.hadoop.hive.ql.hooks.ExecuteWithHookContext.run() 运行所有 hook。
- org.apache.hadoop.hive.ql.hooks.ExecDriver.execute() 运行所有任务的 query。
- 每一个 job org.apache.hadoop.hive.ql.stats.ClientStatsPublisher.run() 都会被调用,来提供 job 的一些统计数据。间隔的默认值由 hive.exec.counters.pull.interval 来控制,默认是1000ms。
- 完成所有 task。
- 如果查询任务失败了,会调用 hive.exec.failure.hooks.
- 运行执行后的 Hook ExecuteWithHookContext.run()
- 运行 org.apache.hadoop.hive.ql.HiveDriverRunHook.postDriverRun()。注意这是在查询完成,结果返回之前执行的。
- 返回结果。
Hive Hook的API
Hive 支持很多类型的 Hook。
- PreExecute 和 PostExecute 扩展自 Hook 接口。
- ExecuteWithHookContext 扩展 the Hook 接口,并且传递 HookContext 给 Hook. HookContext 封装了 Hook 所需要的所有信息。
- HiveDriverRunHook 扩展 Hook 接口,运行常规的 Hive 逻辑在 Driver 上。
- HiveSemanticAnalyzerHook 扩展 Hook 接口对查询进行语义分析. preAnalyze() 和 postAnalyze() 方法可以在语义分析的之前之后运行。
- HiveSessionHook 扩展 Hook 接口提供 session 级别的 hooks. 当 Session 开始,hook 就会被调用。
Hive 的代码里有很多关于 Hook 的例子。
- DriverTestHook 是非常简单的 HiveDriverRunHook,并且可以打印执行的命令在结果里。
- PreExecutePrinter 和 PostExecutePrinter 是执行前后的 Hook,可以打印参数。
- ATSHook 是运行时的 ExecuteWithHookContext,可以把运行时的 query 和 plan 发送到 YARN 的 timeline server。
- EnforceReadOnlyTables 是 ExecuteWithHookContext,可以理解成检查是否有修改只读表的一个 Hook。
- LineageLogger 是 ExecuteWithHookContext,可以记录 query 的血缘信息在日志文件中。
- PostExecOrcFileDump 是一个运行后的 Hook,可以打印 ORC 文件的信息。
- PostExecTezSummaryPrinter 是一个运行后的 Hook,可以打印 Tez 的 summary。
- UpdateInputAccessTimeHook 是一个运行前的 Hook,可以更新所有的的在 query 运行前,所有的输入表的访问时间。
写一个Hive Hook
现在准备写一个 Hive Hook 的例子,并且加载进去 Hive 里面。这个例子非常简单,用的是 pre-execution hook,意思就是在查询执行之前,打印 “Hello from the hook !!"。
创建工程的 pom 文件。
|
|
在项目中引入 hive-exec 的 package。
|
|
创建一个 Class 实现了 Hook 接口 org.apache.hadoop.hive.ql.hooks.ExecuteWithHookContext,这个接口只有一个方法。
|
|
现在我们放一个 statement 在这个示例了。
|
|
最后,完整的类定义如下:
|
|
编译打包。
|
|
构建出的 jar 包放在 Hive 的 classpath,并且设置成 pre-execution hook。
|
|
这就是使用 Hive Hook 的全部,现在就可以看到每次 Hive 语句执行之前都会看到 “Hello from hook !!"。
Metastore Hooks
Hive 也有 metastore 的定制的 hook 来处理关于 metastore 变化的事件。 Metastore initialization hooks 会在 metastore 初始化的时候被调用。比如说保持 HBase 同步到 Hive 的 metastore 中。如果想记录外部组件在 Hive 中创建了那些 tables/databases 之类的,那么这个 Hook 就很合适了。
|
|
Table 对象有所有的关于 Hive 表的信息,包括 name, Serializer, properties, columns 等等,注意 HiveMetaHook 不是扩展自 Hook 接口的。
Caveats
- 需要注意的是 Hook 的实例不能复用。
- Hook 是在正常的 Hive 流程中被调用的,所以需要避免那些吃性能的操作。
参考资料
- http://stackoverflow.com/questions/17461932/hive-execution-hook
- http://www.slideshare.net/julingks/apache-hive-hooksminwookim130813
- https://github.com/apache/hive/blob/master/ql/src/java/org/apache/hadoop/hive/ql/Driver.java
- http://dharmeshkakadia.github.io/hive-hook/