Hive-SQL解析及应用
概述
SQL 已经成为各家数据公司必不可少的数据查询语言。Hive 在其中的地位也更是显而易见,大多数批处理任务还是在使用 Hive SQL 开发。从 Table 级别看,一个 Hive SQL 文件,包含了如下信息:
- DROP 了哪些 Table (DROP TABLE 语句)
- CREATE 了哪些 Table (CREATE TABLE 语句)
- INSERT 了哪些 Table (INSERT INTO 语句)
- 查询了哪些 Table (SELECT FROM 语句)
- 至于删除或者更新了哪些表的数据, Hive 中我们很少用.
那么, 给定一个 Hive SQL 文件, 如何获取到这些信息呢? 别查了, 没有 API 可以一下搞出来, 我们要站在巨人的肩膀上开发了. 熟悉 Hive 的人都知道, Hive 是将 SQL 翻译成 MapReduce 任务执行, 细节可以参考美团技术博客文章: Hive SQL的编译过程, 写的非常好. 关于 SQL 解析的需求, 我们仅仅需要知道 Hive 是借助于 antlr 开发的 SQL 解析逻辑. 如果想拆解一个 SQL 文件, 就从 SQL -> ASTree 这个地方入手.
获取ASTree
Hive 中的 hive-exec 模块是包含 SQL 解析模块的. 因此项目的 pom.xml 中加上.
|
|
需要注意的是,
当然, 作为一个有洁癖的 Java 程序员, 不用的 jar 包全部 exclude 掉是一个好习惯, 如果你跟我一样, 可以参考这个 Gist (别怕, 直接 copy 过来就好)
|
|
使用 Visitor 模式遍历 ASTree
Visitor 模式 是 ASTree 遍历时经常使用的方法.
|
|
关键的时刻到来了, 终于要收工回家了:
|
|
完了么? 然而并没有. 还记得"大明湖畔"的 CTE(Common Table Expression) 么 所谓 CTE 就是说 SQL 可以写成这个模式:
|
|
上述 SQL 扔到刚才的代码中, 解析的 selected tables 会包含 data1 和 data2, 显然这两个不是真正查询过的表, 因此, 在 OurProcessor.java 中, 需要添加 HiveParser.TOK_CTE 的解析, 并在 HiveParser.TOK_TABREF 中将解析到的 CTE 别名剔除.
想收工回家? 哪儿那么简单, 需求才刚刚开始
来看一个 Hive SQL 文件长什么样儿:
|
|
总结一下, 包含如下功能(坑):
- 一个文件会包含多个 SQL 语句
- 会有设置 Hive 系统参数的语句, 类似set hive.groupby.skewindata=true;
- 存在设置变量值语句, 用于后续 SQL 语句中的参数替换, 类似set hivevar:appid=‘app1’;
- SQL 注释(废话)
- 切换当前所在数据库, 类似USE tmpdb;
因此, SQL 文件解析的步骤如下:
- 切 SQL 语句. 使用 ; 将文件中的语句切成独立的 SQL
- 识别 SET 语句
- 如果是设置 Hive 参数, 直接略过
- 如果是设置参数, 保存变量的值, 用于后续 SQL 语句的变量替换
- 识别 USE 语句, 保存当前所在 database 的 context. 当遇到直接使用 Table 名而不是 db.表名 的时候添加当前 database 的名称
- 识别正式的 SQL 语句, 根据当前 context 中存储的变量替换 SQL 类似 ${variable_name} 字符串
- 执行 SQL 分析流程, 将结果保存
好了, 这下没问题了, 上述 SQL 文件, 我输出如下结果
|
|
不光埋头拉车, 也要抬头看路: SQL 解析后用来干嘛
回到实际问题, 随着业务的发展, ETL 过程也越来越复杂, 动不动几十个上百个 SQL 文件, 之间会有错综复杂的依赖关系, 如何维护执行关系, 保证任务按顺序执行成为越来越头疼的事情.
比如下图是一个 DAG 的一部分, 仅仅是一部分
顿时感觉需要一个新的职位: DAG 维护工程师, 专门负责维护任务 DAG, 简称 DagOps. 但是我们思考, 在同一个时间维度下(例如都是每天的任务):
- 通过分析 SQL 文件, 我们知道了每个 SQL 文件涉及的 Table 信息
- 写入这个 Table 的 SQL 文件, 一定需要在查询这个 Table 的任务的前面执行
回到上述 test_job.sql 文件, 我们仅仅需要保证 test_job.sql 必须在写入 userdb.users 和 userdb.user_data 的任务后面执行, 并且需要读取etldb.daily_users 的任务必须在 test_job.sql 完成后面执行. 那么无论有多少个 SQL 文件, 仅仅需要调用我们的 SQL 分析服务, 就可以构建一个 DAG 自动生成程序, 自动编排 SQL 文件的执行顺序. 从此, DagOps 职位成为了江湖中的传说….
除了消灭DagOps, 还能不能再进一步?
我们进一步想, 既然所有的 Hive SQL 代码都在上线前被分析过了, 那分析过程的"下脚料"能否利用一下? 回忆一下, 是不是有如下场景:
- 用到某个 Table 的数据, 怀疑可能有问题, 找谁讨论一下? 或者这个 Table 上次就是你开发的 ETL 逻辑, 谁动了我的代码导致数据不一致?
- 想在某个 Table 加一个字段, 找谁讨论一下可行性?
- 我用的这个 Table 的数据, 是从哪里来的?
- 这个订单 Table , 跟那个订单 Table 有什么关系?
我们已经基于 Table 知道了数据任务之间的依赖关系, 进一步说, 也就知道 ETL 的 Table 之间的依赖关系, 如果关联上代码信息, 展现给用户呢?
因此我们开发了数据血缘关系功能, 如下图:
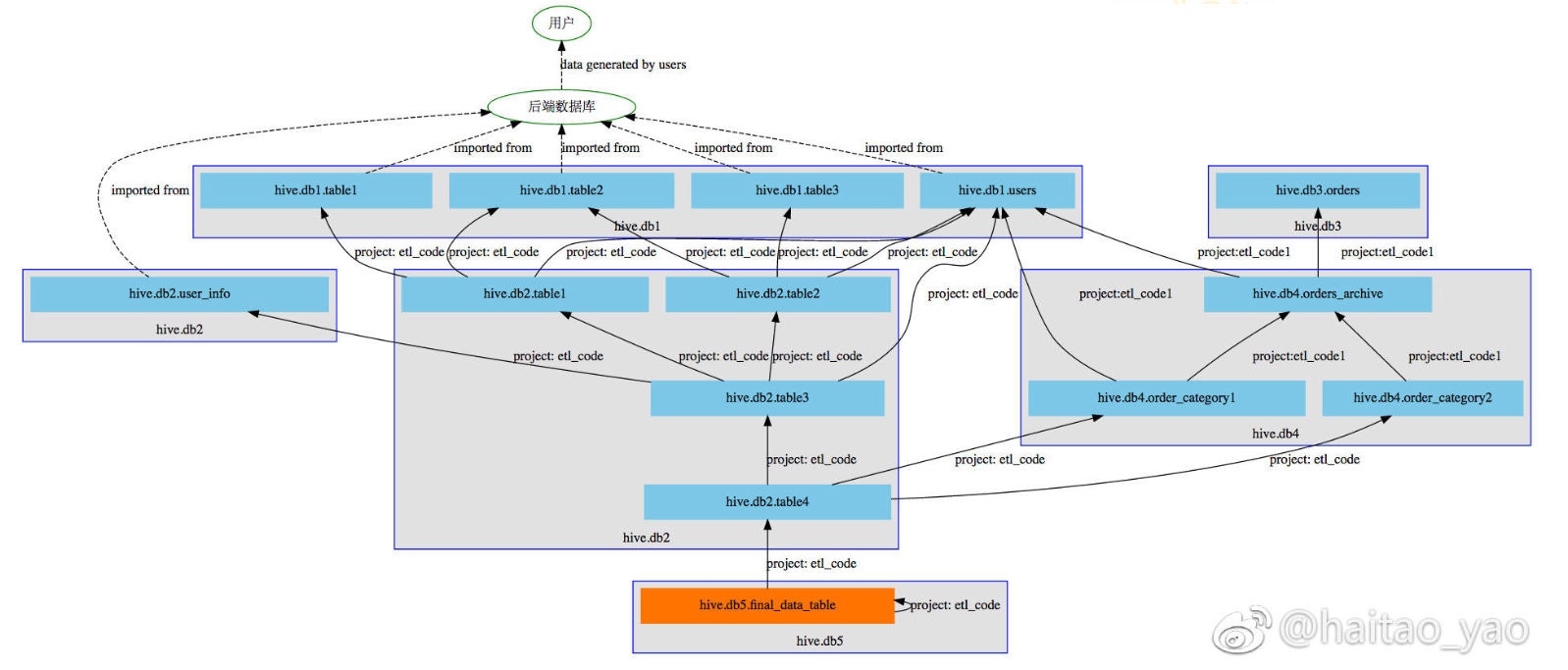
- 每个蓝色的线框代表一个 database
- 蓝色线框内部的每个浅蓝色方块代表一个 Table
- 每个蓝色方块之间的箭头代表依赖关系: A –> B 表示 A 表中的数据需要从 B 表中 ETL 而来
- 每条实线都可以点击, 直接跳转到对应的 ETL SQL 代码 gitlab 页面, 通过 commit message 可以知道最近谁修改过
- 橙色方块代表你当前查看的表: hive.db5.final_data_table
- 最上方表示数据的源头是用户, 用户产生的数据存储到后端数据库, 被导入到数据仓库中进行 ETL
数据的来龙去脉一目了然. 并且在 adhoc 查询工具中, 你写的每个 SQL 都会被分析, 画出一个类似上面的血缘图, 清晰知道自己的 SQL 语句查询的数据的来龙去脉.
总结
我们"拆"了 SQL,
- 攒了一个 DAG 生成服务, 自动编排 SQL 执行, 消灭了 DagOps
- 攒了数据血缘关系功能, 降低数据使用的门槛