概述
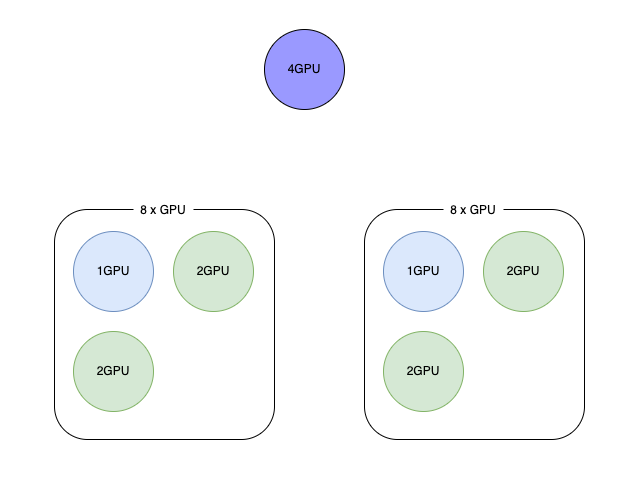
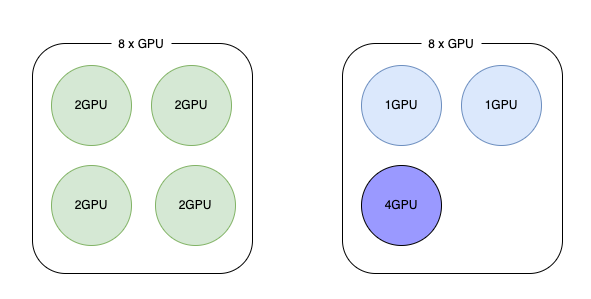
得益于不同尺寸的大模型的发展,我们业务最近部署的 GPU 服务的规格越来越多样了,有1卡、2卡、4卡以及8卡的类型,这跟以往大部分都是1卡的情况相差很大,如果还是以 Kubernetes 默认的调度方式,那么在不同规格的 GPU 服务的情况下,很容易产生资源碎片的问题,尤其是在资源比较紧张,也就是 GPU 分配率本身就比较高的情况下,按照默认的打散的方式的话,如果大部分节点都分配了5卡、6卡的情况下,那些4卡的服务就很难找到合适的节点调度上去了。这种情况下,GPU 服务调度的 binpack 算法可以缓解这样的问题。

binpack算法
该用 binpack 算法之后,可以看到,GPU 分配的时候会先填满一个节点,然后再考虑下一个节点,于是4卡的容器就调度上去了。
从 Kubernetes v1.19 开始,调度框架(Scheduler Framework)被引入,提供了一个更灵活和可扩展的插件机制,允许开发者通过插件的形式自定义调度逻辑。调度框架包括多个阶段(例如Filter、Score、Reserve、Permit等)来替代原来的 Predicates 和 Priorities。
公司 Kubernetes 版本比较低(v1.20),关于调度器的配置在 v1.23 版本有过不大不小的变化,因此目前最新的 Kubernetes 版本的配置方法与 v1.20 是不太相同的,这点在测试和正式环境的时候需要注意,以免在 v1.20 的集群使用最新版本 Kubernetes 的配置。
- Kubernetes v1.19: 调度框架引入,但Predicates和Priorities仍然存在,作为向后兼容的一部分
- Kubernetes v1.20: 调度框架继续改进,官方开始建议使用调度框架插件来替代Predicates和Priorities
- Kubernetes v1.22: Predicates和Priorities被标记为废弃(Deprecated)
- Kubernetes v1.23: Predicates和Priorities正式被移除,调度框架成为唯一的调度机制
在 Kubernetes 的调度器中,RequestedToCapacityRatioResourceAllocation 参数允许用户指定资源以及每类资源的权重,以便根据请求数量与可用容量之比率为节点评分。这就使得用户可以通过使用适当的参数来对扩展资源执行装箱操作,从而提高了大型集群中稀缺资源的利用率。RequestedToCapacityRatioResourceAllocation 优先级函数的行为可以通过名为 requestedToCapacityRatioArguments 的配置选项进行控制。该标志由两个参数 shape 和 resources 组成。shape 允许用户根据 utilization 和 score 值将函数调整为最少请求(least requested)或最多请求(most requested)计算。 resources 包含由 name 和 weight 组成,name 指定评分时要考虑的资源,weight 指定每种资源的权重。如果我们要启用 GPU 的装箱(binpack),那么可以参考下面的 Policy 配置。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
{
"kind": "Policy",
"apiVersion": "v1",
"predicates": [],
"priorities": [
{
"name": "RequestedToCapacityRatioPriority",
"weight": 2,
"argument": {
"requestedToCapacityRatioArguments": {
"shape": [
{
"utilization": 0,
"score": 0
},
{
"utilization": 100,
"score": 10
}
],
"resources": [
{
"name": "nvidia.com/gpu",
"weight": 10
}
]
}
}
}
]
}
|
如果想用 Profile 来给调度器配置插件,可以用下面的配置,注意这是 configmap 的配置,如果使用 Profile 的方式,那么启动命令要改成使用 --config,详细可以查看示例文件 v-1-20-3-scheduler-with-profile.yaml。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
apiVersion: v1
kind: ConfigMap
metadata:
name: gpu-binpack-scheduler-config
namespace: kube-system
data:
gpu-binpack-scheduler-config.yaml: |
apiVersion: kubescheduler.config.k8s.io/v1beta1
kind: KubeSchedulerConfiguration
leaderElection:
leaderElect: true
leaseDuration: 15s
renewDeadline: 10s
retryPeriod: 2s
resourceLock: leases
resourceNamespace: kube-system
resourceName: gpu-binpack-scheduler
profiles:
- schedulerName: gpu-binpack-scheduler
plugins:
score:
enabled:
- name: NodeResourcesMostAllocated
pluginConfig:
- name: NodeResourcesMostAllocated
args:
resources:
- name: nvidia.com/gpu
weight: 10
- name: cpu
weight: 1
- name: memory
weight: 1
|
关于 RequestedToCapacityRatioResourceAllocation 优先级函数如何对节点评分,可以参考下面的流程,看完之后应该会更清晰。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
|
请求的资源
nvidia.com/gpu: 2
Memory: 256MB
CPU: 2
资源权重
nvidia.com/gpu: 5
Memory: 1
CPU: 3
FunctionShapePoint {{0, 0}, {100, 10}}
节点 Node1 配置
可用:
nvidia.com/gpu: 4
Memory: 1 GB
CPU: 8
已用:
nvidia.com/gpu: 1
Memory: 256MB
CPU: 1
节点得分:
nvidia.com/gpu = resourceScoringFunction((2+1),4)
= (100 - ((4-3)*100/4)
= (100 - 25)
= 75
= rawScoringFunction(75)
= 7
Memory = resourceScoringFunction((256+256),1024)
= (100 -((1024-512)*100/1024))
= 50
= rawScoringFunction(50)
= 5
CPU = resourceScoringFunction((2+1),8)
= (100 -((8-3)*100/8))
= 37.5
= rawScoringFunction(37.5)
= 3
NodeScore = (7 * 5) + (5 * 1) + (3 * 3) / (5 + 1 + 3)
= 5
节点 Node2 配置
可用:
nvidia.com/gpu: 8
Memory: 1GB
CPU: 8
已用:
nvidia.com/gpu: 2
Memory: 512MB
CPU: 6
节点得分:
nvidia.com/gpu = resourceScoringFunction((2+2),8)
= (100 - ((8-4)*100/8)
= (100 - 50)
= 50
= rawScoringFunction(50)
= 5
Memory = resourceScoringFunction((256+512),1024)
= (100 -((1024-768)*100/1024))
= 75
= rawScoringFunction(75)
= 7
CPU = resourceScoringFunction((2+6),8)
= (100 -((8-8)*100/8))
= 100
= rawScoringFunction(100)
= 10
NodeScore = (5 * 5) + (7 * 1) + (10 * 3) / (5 + 1 + 3)
= 7
因此按照以上的结算过程,Node2 是优选的节点。
|
Kubernetes配置
测试条件下,我们有如下配置的 Kubernetes 集群(没有GPU节点)。
1
2
3
4
5
|
# k get no -o wide
NAME STATUS ROLES VERSION INTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
master Ready control-plane,master v1.20.3 192.168.1.200 openEuler 22.03 LTS 5.10.0-60.125.0.152.oe2203.x86_64 docker://19.3.13
node1 Ready <none> v1.20.3 192.168.1.201 openEuler 22.03 LTS 5.10.0-60.139.0.166.oe2203.x86_64 docker://19.3.13
node2 Ready <none> v1.20.3 192.168.1.202 openEuler 22.03 LTS 5.10.0-60.139.0.166.oe2203.x86_64 docker://19.3.13
|
调度器配置
如果我们希望 GPU Pod 调度的时候可以按照 binpack 的形式来调度,在 Kubernetes 上有几种选择。
- 新增一个调度器的进程,比如是一个Deployment形式的调度器
- 给默认调度器增加profile
针对1,这种形式有点类似 Volcano 的调度器,在 Volcano 中,scheduler 是一个单独的 Deployment 部署在 Kubernetes 集群中。针对2,则使用的是默认的调度器进程,只是通过不同的 profile 进行了调度器插件的区分。
fake-gpu
虽然测试集群没有可用的 GPU,但是可以通过下面的配置,可以让给没有 GPU 的节点,虚假地上报 GPU 资源,方便后面的测试。
1
2
3
4
5
6
7
|
kubectl label node node1 nvidia.com/gpu.deploy.device-plugin=true nvidia.com/gpu.deploy.dcgm-exporter=true --overwrite
kubectl label node node2 nvidia.com/gpu.deploy.device-plugin=true nvidia.com/gpu.deploy.dcgm-exporter=true --overwrite
kubectl label node 10.189.212.124 nvidia.com/gpu.deploy.device-plugin=true nvidia.com/gpu.deploy.dcgm-exporter=true --overwrite
kubectl label node 10.189.212.125 nvidia.com/gpu.deploy.device-plugin=true nvidia.com/gpu.deploy.dcgm-exporter=true --overwrite
helm repo add fake-gpu-operator https://fake-gpu-operator.storage.googleapis.com
# 模拟每个节点有8卡
helm upgrade -i gpu-operator fake-gpu-operator/fake-gpu-operator --namespace gpu-operator --create-namespace --set initialTopology.config.node-autofill.gpu-count=8
|
查看部署的结果和上报的资源,可以看到 node1 和 node2 当前都上报了8卡的 GPU。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
# k get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE
device-plugin-ljwrv 1/1 Running 0 36m 10.244.1.54 node2
device-plugin-vncbc 1/1 Running 0 36m 10.244.2.77 node1
nvidia-dcgm-exporter-2t54q 1/1 Running 0 9h 10.244.2.10 node1
nvidia-dcgm-exporter-v8p5z 1/1 Running 0 9h 10.244.1.6 node2
status-updater-7dd49b7b5c-2ppq4 1/1 Running 0 17h 10.244.1.3 node2
topology-server-6845cbc768-wpbtm 1/1 Running 0 17h 10.244.2.8 node1
# kubectl-view-allocations -g node
Resource Requested Limit Allocatable Free
nvidia.com/gpu (62%) 10.0 (62%) 10.0 16.0 6.0
├─ node1 (100%) 8.0 (100%) 8.0 8.0 0.0
└─ node2 (25%) 2.0 (25%) 2.0 8.0 6.0
|
自定义调度器
参考我个人整理的 yaml 文件 v-1-20-3-scheduler.yaml 可以在 kube-system 的命名空间下部署一个自定义的调度器,名叫 gpu-binpack-scheduler,并且作为测试,部署了一个10个副本,一共需要10卡的 deployment,看看调度的最终情况,这里需要注意的是,测试 deployment 的 schedulerName 必须指定为 gpu-binpack-scheduler。
测试结果
从测试结果看,会先将 node1 填满了,再往 node2 分配,这个结果是符合我们的预期的。
1
2
3
4
5
6
7
8
9
10
11
12
|
# k get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE
sleepy-deployment-d557d79ff-5mtlp 1/1 Running 0 7h16m 10.244.2.73 node1
sleepy-deployment-d557d79ff-5p2k5 1/1 Running 0 7h16m 10.244.2.69 node1
sleepy-deployment-d557d79ff-6rbmj 1/1 Running 0 7h16m 10.244.1.52 node2
sleepy-deployment-d557d79ff-f8js8 1/1 Running 0 7h16m 10.244.2.75 node1
sleepy-deployment-d557d79ff-j2hg4 1/1 Running 0 7h16m 10.244.2.70 node1
sleepy-deployment-d557d79ff-jhx27 1/1 Running 0 7h16m 10.244.2.71 node1
sleepy-deployment-d557d79ff-lxj6v 1/1 Running 0 7h16m 10.244.2.72 node1
sleepy-deployment-d557d79ff-mzklc 1/1 Running 0 7h16m 10.244.2.76 node1
sleepy-deployment-d557d79ff-tpclt 1/1 Running 0 7h16m 10.244.2.74 node1
sleepy-deployment-d557d79ff-zaaa5 1/1 Running 0 7h16m 10.244.1.53 node2
|
参考文章
- 配置多个调度器
- 使用RequestedToCapacityRatioResourceAllocation启用装箱
- release-1.20
- kube-scheduler
- my-scheduler
- kube-scheduler-policy-config
- scheduler-config
- fake-gpu-operator
警告
本文最后更新于 2024年6月1日,文中内容可能已过时,请谨慎参考。