Flink和Yarn
概述
大家知道 Yarn 是做资源管理的 Hadoop 的组件,熟悉 Spark on Yarn 的同学应该不会陌生,本文翻译一下官方文档中关于 Flink 和 Yarn 的交互介绍
https://ci.apache.org/projects/flink/flink-docs-release-1.7/ops/deployment/yarn_setup.html
How Flink and YARN Interact
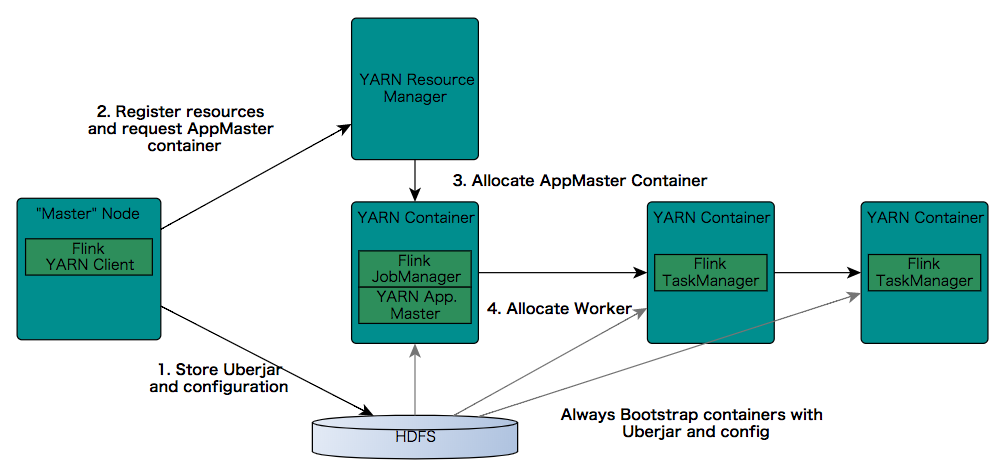
Yarn 的客户端需要访问 Hadoop 配置文件的权限来连接 Yarn 和 HDFS。Hadoop 的配置文件由以下策略来设置。
- YARN_CONF_DIR, HADOOP_CONF_DIR 或 HADOOP_CONF_PATH 这些环境变量可以设置 Hadoop 的配置文件读取的位置。
- 如果上述的配置失效,客户端可用 HADOOP_HOME 环境变量。那么 Hadoop 的配置文件可能在 $HADOOP_HOME/etc/hadoop (Hadoop 2中) 或 $HADOOP_HOME/conf (Hadoop 1中)。
当启动 Flink 连接 Yarn 的时候,客户端首先检查请求的需要的资源(容器 containers 和 memory 内存)是否足够。然后,客户端上传你的 Flink 程序的 jar 文件,以及配置文件到 HDFS 上(图上的 step1)。
下一步(图上的 step2),客户端向 Yarn 申请一个容器 container 来启动 ApplicationMaster (图上的 step3)。然后下一步(图上 step4)就会在 Yarn 的调度下,启动 NodeManager 来运行 step1 上传的(注册好的) Flink 程序,NodeManger 所在的容器会下载相关的 jar 和配置文件。
JobManager 和 ApplicationMaster 在同一个容器 Container 中运行。一旦他们都启动成功,ApplicationMaster 由于知道 JobManager 地址(前面说了在同一个容器上启动),就会传送 Flink 的配置文件到 TaskManagers。此外,ApplicationMaster 所在的容器也启动 Flink 的 web 交互服务。所有的 Yarn 端口都是临时的端口。这使得用户可以并行的运行多个 Flink 在 Yarn 上的程序。
最后,ApplicationMaster 开始启动各个容器中 Flink 的 TaskManager,TaskManager 是真正干活的组件,会从 HDFS 上下载 jar 文件和各种配置文件。这些步骤完成率,Flink 也就准备好开始接受用户提交的作业了。