概述
DeepSpeed Chat 是基于 DeepSpeed 来做训练的,只是前提,如果搞不清楚这两者的关系,你可能无法阅读这篇文章。因此在 DeepSpeed Chat 的训练脚本里,随处可以看到 deepspeed 这个关键词,本文不讨论 DeepSpeed 本身,主要研究的是 DeepSpeed Chat 是怎么跑起来 finetune 的过程的。
从代码的分析来看,DeepSpeed Chat 的代码虽然给出了所谓的「一键启动训练」,但实际也只足够跑其官方给出的例子。如果想要使用自己的语料进行 finetune 还需要做一些代码修改的工作。
至于为什么样 DeepSpeed Chat 的训练框架来做训练呢,有几个好处。
- 清晰的3个step流程
- 每个流程都有eval的脚本
依赖
1
2
3
4
5
6
7
|
datasets>=2.8.0
sentencepiece>=0.1.97
protobuf==3.20.3
accelerate>=0.15.0
torch>=1.12.0
deepspeed>=0.9.0
git+https://github.com/huggingface/transformers
|
工具类
1
2
3
4
5
6
7
8
9
10
11
|
DeepSpeedExamples/applications/DeepSpeed-Chat/training/utils
├── data
├── data_utils.py # 数据的处理工具
└── raw_datasets.py # 不同数据集的不同处理方法
├── ds_utils.py # 主要是deepspeed本身的配置
├── model
├── model_utils.py
└── reward_model.py
├── module
└── lora.py # lora的工具类
└── utils.py # 其他工具
|
读取 tokeninzer 的方法。
1
2
3
4
5
6
7
8
9
10
11
|
def load_hf_tokenizer(model_name_or_path, fast_tokenizer=True):
if os.path.exists(model_name_or_path):
# Locally tokenizer loading has some issue, so we need to force download
model_json = os.path.join(model_name_or_path, "config.json")
if os.path.exists(model_json):
model_json_file = json.load(open(model_json))
model_name = model_json_file["_name_or_path"]
tokenizer = AutoTokenizer.from_pretrained(model_name, fast_tokenizer=True)
else:
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, fast_tokenizer=True)
return tokenizer
|
从 data_utils 知道,如果需要混入自定义的或者其他默认以外的语料,必须要修改这个文件的一些选项,否则只能用默认的数据集。
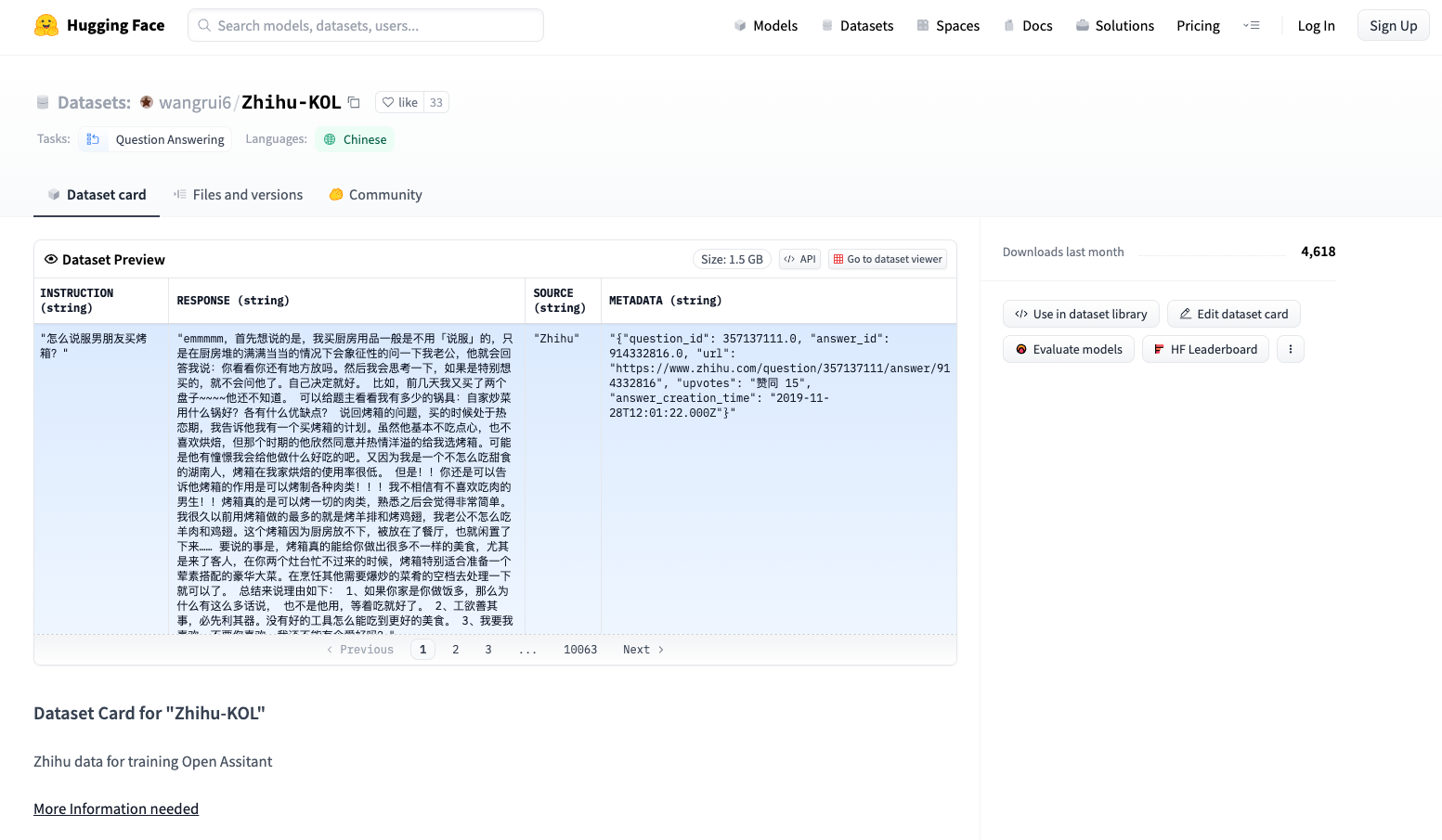
举一个例子,比如 wangrui6/Zhihu-KOL 这份语料的整理,就会落到 Wangrui6ZhihuKOLDataset,这个类去处理。
单机单卡
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
# /root/DeepSpeedExamples/applications/DeepSpeed-Chat
# python train.py --actor-model facebook/opt-1.3b --reward-model facebook/opt-350m --deployment-type single_gpu
---=== Running Step 1 ===---
Running:
bash /root/DeepSpeedExamples/applications/DeepSpeed-Chat/training/step1_supervised_finetuning/training_scripts/single_gpu/run_1.3b.sh /root/DeepSpeedExamples/applications/DeepSpeed-Chat/output/actor-models/1.3b
---=== Finished Step 1 in 0:09:44 ===---
---=== Running Step 2 ===---
Running:
bash /root/DeepSpeedExamples/applications/DeepSpeed-Chat/training/step2_reward_model_finetuning/training_scripts/single_gpu/run_350m.sh /root/DeepSpeedExamples/applications/DeepSpeed-Chat/output/reward-models/350m
---=== Finished Step 2 in 0:23:31 ===---
---=== Running Step 3 ===---
Running:
bash /root/DeepSpeedExamples/applications/DeepSpeed-Chat/training/step3_rlhf_finetuning/training_scripts/single_gpu/run_1.3b.sh /root/DeepSpeedExamples/applications/DeepSpeed-Chat/output/actor-models/1.3b /root/DeepSpeedExamples/applications/DeepSpeed-Chat/output/reward-models/350m '' '' /root/DeepSpeedExamples/applications/DeepSpeed-Chat/output/step3-models/1.3b
---=== Finished Step 3 in 1:58:58 ===---
---=== Finished Steps (1, 2, 3) in 1:58:58 ===---
|
查看日志,三个 step 的日志可以分别查看 step1-training.log/step2-training.log/step3-training.log。
总共耗时 1:58:58,比官方(2.2hr)在 8 * A100 的机器上快了一点。

测试 Chat 的效果。
简单的问答测试
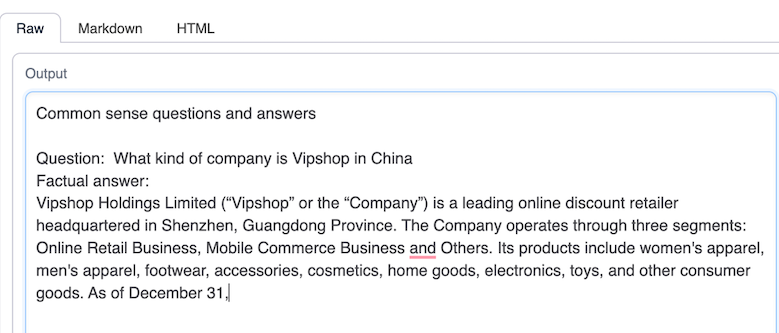
未经微调的opt-1.3
微调后的opt-1.3
中文训练
Hugging Face 有很多中文语料。
参考资料
- DeepSpeedExamples
- 一键式RLHF训练DeepSpeed Chat(二)实践篇
- 第1章: DeepSpeed-Chat模型训练实战
- support training bloom-560m and load dataset from local dir #678
- RuntimeError: The size of tensor a (6144) must match the size of tensor b (8192) at non-singleton dimension 0 #587
- 关于如何调整到torchrun命令
- 增量预训练baichuan-13b-chat遇到的那些坑
- 社区供稿 | 基于 LoRA 的 RLHF: 记一次不太成功但有趣的百川大模型调教经历
- DeepSpeed-Chat全流程训练实战
警告
本文最后更新于 2023年8月21日,文中内容可能已过时,请谨慎参考。