Big-Data-and-Machine-Learning-on-Kubernetes
概述
过去十年,Hadoop 生态的各类组件早已成为大数据领域的事实标准,很多公司围绕 Hadoop 生态,构建出自己的大数据处理到机器学习的管道。而 Kubernetes 作为容器编排领域的标准,业界也一直在探索 Big Data 和 Machine Learning on Kubernetes 的新架构,可以说基于云原生的大数据解决方案正离我们越来越近。
背景
从 Google 大数据「三驾马车」,再到各种深度学习框架百花齐放,百家争鸣,大数据和机器/深度学习一直都是业界热度很高的话题。而随着物理机到虚拟机再到容器的共存和过渡,以及大数据在规模上的膨胀,流式计算、实时数仓等需求,过往基于 Hadoop 的全套大数据组件也在如调度的灵活性上显示出一些局限性。正如 《Kubernetes与民主化基础设施 – TenC的探索与实践》一文提及过,Kubernetes 本身提供的扩展机制非常多,Kubernetes 在容器编排和调度的灵活性恰好也给大数据计算、存储以及机器学习领域带来了新的机遇和挑战。
时至今日,Spark,Flink 等主流的批/流计算框架也已经开始基于 on Kubernetes 来扩展其原生的调度能力,这些计算框架可以通过 Java/Python/Go 等 Kubernetes 的 Client 来连接 Kubernetes 集群,逐渐尝试以 Kubernetes 作为工作负荷的调度管理中心。此外,Tensorflow 和腾讯开源的 Plato 也都支持开箱即用容器镜像使用例子,同时也都天然适配 on Kubernetes 的运行架构。可见在不久的将来,会有越来越多的计算相关的框架运行在 Kubernetes 集群。
关于这些计算存储相关的框架与 Kubernetes 的融合,得益于 Kubernetes 优秀的设计和扩展机制,通过 CRD+Controller 的方式,衍生了很多大数据计算和存储领域内的 Operator。其中,CRD 仅仅是资源的定义,在这些计算框架相关的 Operator 中,通过自定义计算任务的资源类型,然后开发相关的 Controller 便可以去监听计算相关的 CRD 对象的增删改查的事件,从而控制计算任务本身的业务逻辑。关于 Kubernetes Operator 的介绍,还可以继续关注专栏下期的的文章《开箱即用,基于 K8S Operator 的最佳实践》。
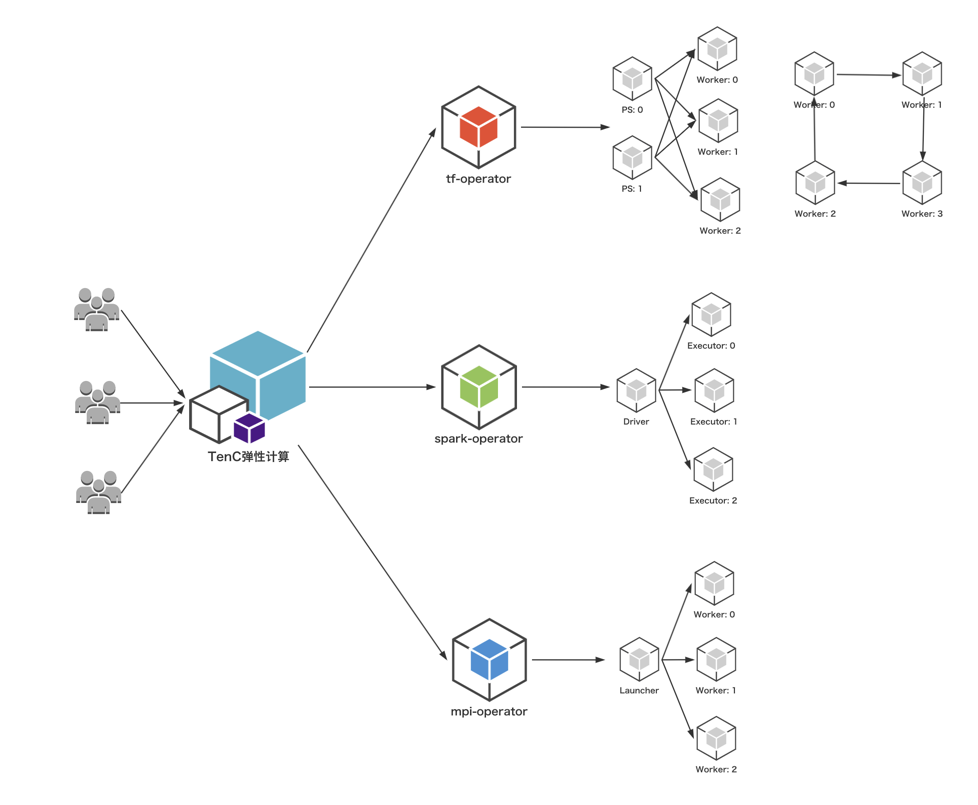
关于大数据计算和存储与 Kubernetes 分别都是非常大的议题,本文无法覆盖到方方面面,而 TenC 弹性计算平台作为一个完全基于 Kubernetes 构建的容器计算平台,从2017年就开始探索关于 Spark 和 Tensorflow on Kubernetes 的实践和具体落地的方案,本文会从我们团队探索和实践的经验,简要的阐述一下 Spark/Tensorflow/MPI on Kubernetes 的架构演变和发展。
Spark on Kubernetes
TenC 弹性计算早在 Spark 2.2 on Kubernetes,也就是 Spark 2.3 之后支持的 Spark on Kubernetes 之前,就已经开始探索 Spark on Kubernetes 的运行模式了。由于 TenC 提供的 Kubernetes 集群一般是多租户共享而非业务独享的,所以平台上启动一个 Spark 应用,以前的实现方法是需要通过在集群内创建单独 submit 功能的 Pod,并且该 Pod 里执行用户传入的各种参数来组成 spark-submit 的命令,这个过程大体上跟 Spark Operator 是不谋而合的,只是当时缺少 CRD+Controller 运行的和开发的扩展模式,因此在 Spark 应用的状态的管理上还不是非常完善,比如说在任务重启以及做定时任务之类的操作,是不如目前的 Spark Operator 那么方便的。
在 Spark 和 Kubernetes 社区的共同努力下,Spark 从 2.3 开始已经官方支持 Kubernetes,至今已经有一段时间,当然限于 Kubernetes 模块的活跃程度,针对 on Kubernetes 的发展和优化,还需要考虑其他模块的兼容性问题,所以迭代显得比较缓慢。目前也有很多 Spark on Yarn 可以支持的特性在 on Kubernetes 的情况是无法使用的,最典型的就是 Dynamic Resource Allocation,目前在 Spark 3.0 preview 版本实现的基本上是一个阉割版的临时实现。下图是 Spark on Kubernetes 官方的基本的架构图。
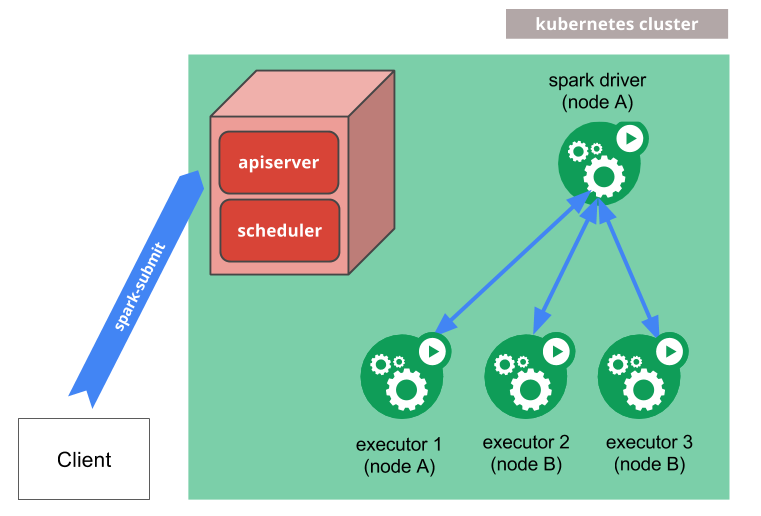
使用上倒是和原来 Standalone 或者 Yarn 或者 Mesos 模式没有太大的区别,一样都是通过 spark-submit 命令来提交 Spark 应用。
|
|
Spark on Kubernetes 由于进度的原因,目前对 on Kubernetes 的一些支持还不太好,或者说还不够好,最典型的就是在 2.x 的版本里,无法直接使用到 Kubernetes 的调度上的优秀特性,如 NodeSelector, Affinity 或者 Taint/Toleration。而 Spark Operator 的出现,正好给解决这些问题提供了思路。
关于使用 Spark Operator 和原生的 Spark on Kubernetes 的区别和优缺点比较,之前翻译过和写过几篇文章,大家可以参考一下,本文就不多赘述了,下图是 Spark Operator 的基础架构图。
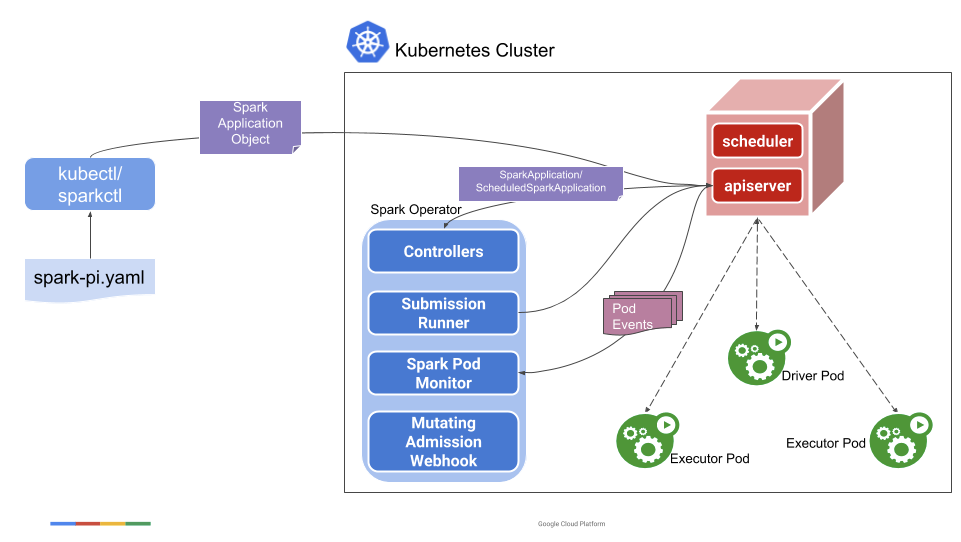
通过 Spark Operator 创建一个 Spark 应用,以及添加一些调度相关的特性,还是比较简单的。
|
|
另外就是由于 Spark Operator 在提供了集成批调度器实现的接口,所以在 TenC 弹性计算平台上使用的 Spark Operator 已经集成了 batch-scheduler 实现的批调度器,可以支持一个计算任务的所有副本作为一个整体来调度,关于 batch-scheduler 的实现细节,可以继续关注专栏后面推送的文章 《One or Batch?K8s批调度器的实现细节》。
Tensorflow on Kubernetes
近两年,有越来越多的公司用 Kubernetes 来运行各种各样的工作负载,最经典的可以说是 Tensorflow 了,毕竟两者是都是 Google 出品。
分布式的机器学习任务一般会涉及参数服务器,以下称为 PS 和工作节点 Worker。如果想要在 Kubernetes 中运行分布式的 Tensorflow 任务,首先要面临的就是跟在虚拟机或者物理机一样的问题,配置一堆异常繁琐的参数,一个 Tensorflow 任务可以有多个 PS 和多个 Worker,而每个 PS 和 Worker 又被要求传入不同的命令行参数。
举例说明,下面例子参考来自 Distributed TensorFlow。
|
|
其中必要的几个参数分别是 PS/Worker 的网络地址,工作负载的类型,还有就是任务的 index 等等,虽然很多工程师会会通过一些模板引擎可以帮忙减轻下负担的,但是工具一旦换了,又要重新适应,这无疑是增加了算法工程师的工作负担的。
此外,Kubernetes 默认的调度器对于机器学习任务的调度并不友好。如果说之前的问题只是在应用与部署阶段比较麻烦,那调度引发的资源利用率低,就格外值得关注。机器学习任务对于计算和网络的要求相对较高,一般而言所有的 Worker 都会使用 GPU 进行训练,而且为了能够得到一个较好的网络支持,尽可能地同一个机器学习任务的 PS 和 Worker 放在同一台机器或者网络较好的相邻机器上会降低训练的时间,所以如果需要搭建一个分布式机器学习的任务,为了达到更好的调度方式,每个工作负载的描述文件,也都会非常复杂,这一点也不比原来的方式轻松。
Kubeflow 社区开源的 tf-operator 在 Kubernetes 上定义了一个新的资源类型:TFJob,通过这样一个资源类型,使用 TensorFlow 进行机器学习训练的工程师们不再需要编写繁杂的配置,只需要按照他们对业务的理解,确定 PS 与 Worker 的个数和相关配置,就可以进行一次训练任务。
|
|
每个 PS 以及 Worker,都由两种资源对象组成,分别是 Job 和 Service。其中 Job 负责创建出 PS 或者 Worker 的 Pod,而 Service 负责将其暴露出来。整个分布式 Tensorflow 训练任务的执行过程可以参考下图。
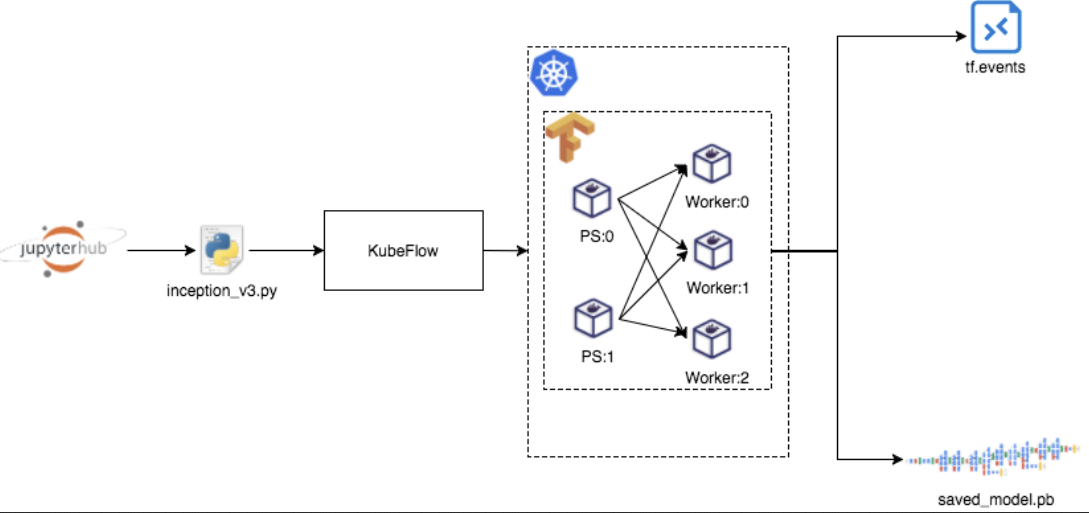
TenC 弹性计算平台最开始支持分布式 Tensorflow 的训练任务,采取的思路跟 Spark 2.2 的时候是类似的,也就是通过一个 submit 任务的 Pod,来把用户描述的训练任务提交给 Kubernetes 集群,只是在任务状态的控制上以及错误恢复等方面的实现不够完整,所以目前 TenC 上的分布式 Tensorflow 计算任务也切换到 tf-operator 上了。
MPI on Kubernetes
MPI(Message Passing Interface) 是一种可以支持点对点和广播的通信协议,具体实现的库有很多,使用比较流行的包括 Open Mpi, Intel MPI 等等,关于这些 MPI 库的介绍和使用,本文就不多赘述了,各位可以看看官方文档。
mpi-operator 是 Kubeflow 社区贡献的另一个关于深度/机器学习的一个 Operator,关于 mpi-operator 的 proposal,可以参考 mpi-operator-proposal。目前社区在 mpi-operator 主要用于 allreduce-style 的分布式训练,因为 mpi-operator 本质上就是给用户管理好多个进程之间的关系,所以天然支持的框架很多,包括 Horovod, TensorFlow, PyTorch, Apache MXNet 等等。而 mpi-operator 的基本架构是通过 Mpijob 的这种自定义资源对象来描述分布式机器学习的训练任务,同时实现了 Mpijob 的 Controller 来控制,其中分为 Launcher 和 Worker 这两种类型的工作负荷。
社区开源的 mpi-operator,开箱即用,但是在 TenC 上的应用,在某些方面,面对一些固定场景和业务的时候会有一定的限制。
- 对于使用GPU资源的
Worker有可能会调度到算力平台的集群,而Launcher会在TenC的集群上,所以跨集群Launcher和Worker的通信问题,需要额外的考虑 - 在我们使用的OpenMPI 4.0里发现在解析
hostfile的时候会尝试解析hostfile的域名,这个过程使得Worker启动变很慢 - Metrics收集,目前社区版缺少
Mpijob的基础指标 - 需要支持更多的批调度组件,比如batch-schduler
- v1.8和高版本集群的兼容,这里主要涉及到资源对象
status这类的subresource的更新操作的兼容
对于用户,只要创建一个 Mpijob 的自定义资源对象,在 Template 配置好 Launcher 和 Worker 的相关信息,就相当于描述好一个分布式训练程序的执行过程了。
|
|
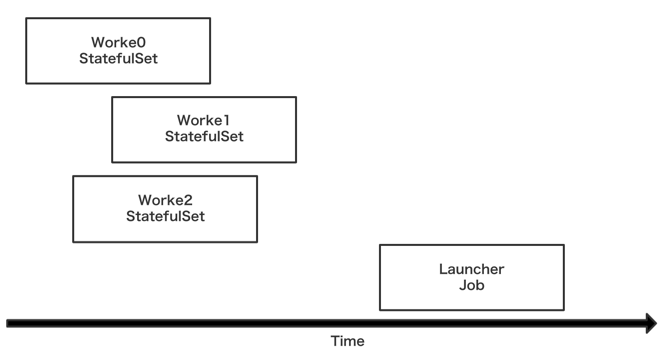
Worker 本质上是 StatefulSet,在分布式训练的过程中,训练任务通常是有状态的,StatefulSet 正是管理这些的 Workload 的对象。通常,Launcher 会是一个比较轻量化的 Job,他主要完成几条命令的发送就可以了,通常是把命令通过 ssh/rsh 来发送接受命令,在 mpi-operator 里使用的是 kubectl 来给 Worker 发送命令,下图是其基础架构图。
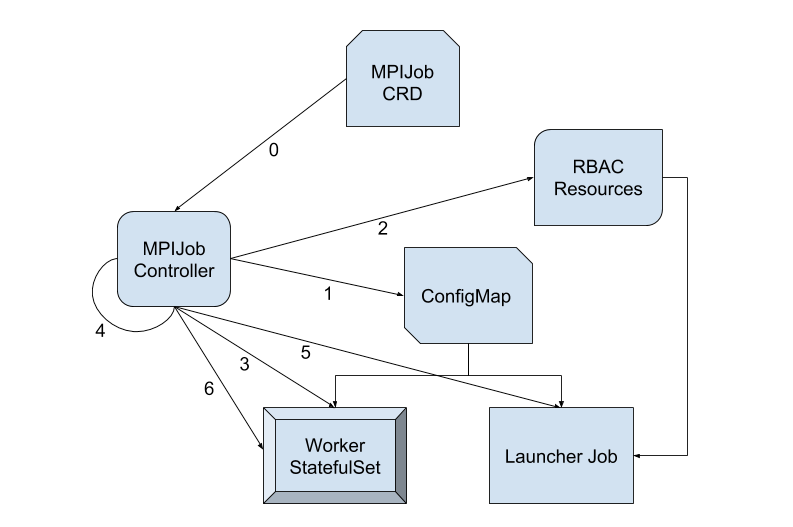
Mpijob 启动的顺序是先启动 Worker 再启动 Launcher。
|
|
其中 kubectl-delivery 的作用主要是将 kubectl 放入到 Launcher 容器内,之后可以通过 kubectl 来给 Worker 发送 mpirun 的命令,下图是其任务执行时候的时序图。
|
|
总结
随着大数据计算和机器学习相关的框架组件和 Kubernetes 的深度融合,这也为 TenC 弹性计算平台 在 Kubernetes 集群上提供计算能力提供了极大的便利。
大数据计算和机器学习 on Kubernetes 已经是大势所趋,各类计算相关的 Operator 通过 Kubernetes 生态周边的工具,如 Helm Charts,或者 Kustomize,使得部署一个多功能的计算集群变得非常轻松,减少了运维的压力,提高了计算集群的稳定性。不管是 Spark 批处理,还是 Tensorflow 这样的机器学习任务,依赖这些 Operator 也都可以让大数据和算法工程师们非常容易的运行他们的计算任务,可以预见,大数据和机器学习 on Kubernetes 的架构是有光明的未来的,期待各方面的继续完善。
参考资料
- The future of big data is Kubernetes
- Big Data & K8s – Why Spark & Hadoop Workloads Should Run Containerized
- Kubernetes与民主化基础设施-TenC的探索与实践