画像组件
目录
概述
说起推荐系统,有个很「专业」的词不得不说,不说人家还觉得你不够专业。那就是「千人千面」。众所周知,电商场景下,推荐系统的千人千面是指根据不同的人及其特征,来推荐不同的商品,可见这个刻画用户/商品特征的画像组件在推荐系统里的重要性。本文简单说一下我经历过的几个推荐系统中,是如何构建这个组件。
数据来源
用户画像的数据来源主要包括两个方面:
- 属性数据,这部分数据一般是用户的注册信息,也可以是从其他数据中分析得出的。比如生日、性别、住址、爱好等。这些数据一般都「躺在」业务数据库中
- 行为数据,这部分数据一般都是用户的访问日志记录的行为数据,也是画像的实时性的基本保证。比如常用的一些后端日志数据、前端埋点数据等等,需要统一的采集层进行采集
特性
用户画像具有很明显的动态性和时空局部性。
- 在用户的数据中,属性信息一般不会改变;但是行为数据是随时会发生变化的,比如用户看了一个新的电影、阅读了新的文章等。这时它的数据就是动态变化的,这部分数据应该动态的更新到用户的画像上,保证画像的实时性
- 时间上,用户的一些需求是很快会发生变化的,比如最近下雨,用户想要买一把伞,如果几天后才捕捉到用户的需求,此时天都晴了;另一方面,空间上,用户在不同的领域喜好也不同,可能在新闻领域用户是一个严重的军事迷,但是在网购时,又是一个小清新,因此需要考虑到不同空间用户不同的需求场景,刻画对应的画像
存储和使用
推荐系统可以根据存储和使用方式分为三层:
- HBase用于实时获取画像,提供高并发下的毫秒级返回
- Elasticsearch用于召回层,尽可能在短时间内根据用户画像标签初筛合适的商品作为候选集
- Hive用于算法同学训练模型提供统一的数据源,该存储可以不实时,根据需求每天同步一份即可
以下是一个画像组件的基础架构图。
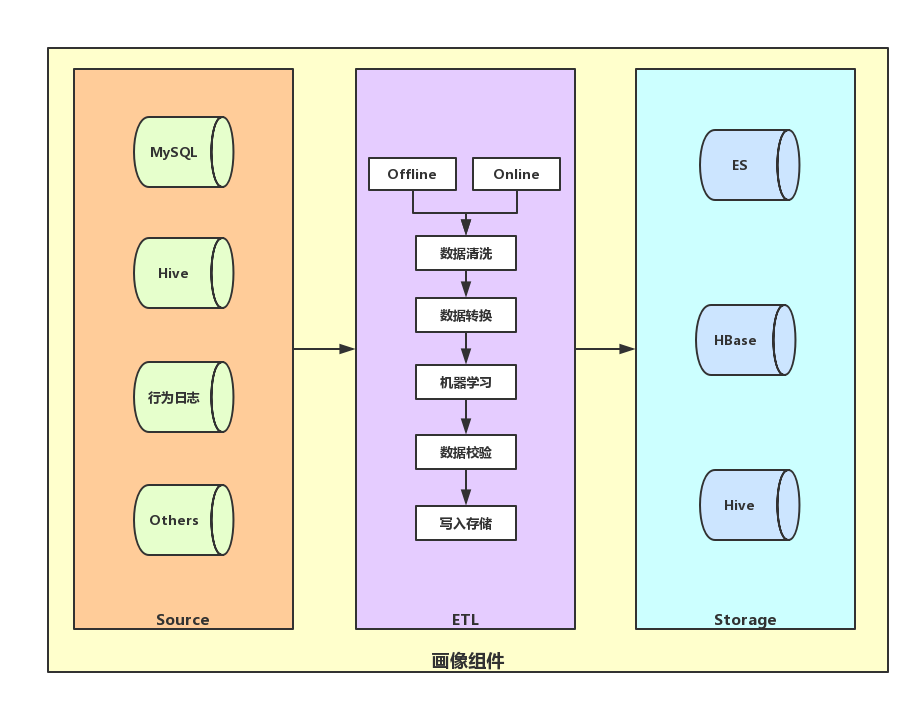
数据源一般包括业务数据库如 MySQL 的表,以及一些存储在 Hive 中的中间数据,还有包括浏览和行为日志等等。在通过统一的采集层进行收集后,利用批流计算框架,例如 Spark/Flink/MapReduce 等等,将数据按照约定的格式进行清洗,转换,甚至包括一些多重的二次数据挖掘的处理,最终在校验完数据后写入相应的存储。而如何存储,则视乎于推荐引擎以及推荐的相关后台系统如果接入。这里举个例子就是,比如在构建一个画像的后台管理系统的时候,后端通过调用存储以上的读写服务,记性特征的加载,可以在后台的 Web 前台进行快速的查询,这种方式既可以为后台用户,比如运营和算法同学,屏蔽数据库查询的操作,保证数据的安全,也可以读取到实时的画像,来进行 Bad Case 的分析。
警告
本文最后更新于 2017年3月3日,文中内容可能已过时,请谨慎参考。