概述
kube-controller-manager 跟 kube-apiserver 有一个区别,后者是可以水平扩容的无状态服务,而前者则是需要通过选主选出主节点,并且同时只有一个主节点在运作的服务。因此如果计划通过 Deployment 可以快速扩展 kube-controller-manager 也是需要理解的,即使副本很多,同时也只有一个节点在服务。
部署
为了让 kube-controller-manager 可以在非 controlplane 节点上运行,最简单的方法是把证书以及配置文件全部打入到镜像中,然后容器启动就无需要挂载本地的目录,可以参考下面的 Dockerfile 构建出包含证书和配置文件的 Docker 镜像。
1
2
3
4
5
|
FROM registry.k8s.io/kube-controller-manager:v1.30.4
# 下面的文件是从kubeadm创建集群的控制节点上拷贝来的
ADD pki /etc/kubernetes/pki/
ADD controller-manager.conf /etc/kubernetes/controller-manager.conf
|
通过下面的 Deployment 文件即可部署成功,注意因为我们的容器 IP 是大二层 IP,所以这里的 hostNetwork 选择 false 也可以保证和其他组件的通信,因为镜像里已经包含证书和配置文件了,所以 Deployment 就不需要做额外的挂载了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
|
apiVersion: apps/v1
kind: Deployment
metadata:
name: kube-controller-manager
namespace: kube-system
labels:
component: kube-controller-manager
tier: control-plane
spec:
replicas: 1 # 设置副本数,根据需求调整
selector:
matchLabels:
component: kube-controller-manager
template:
metadata:
labels:
component: kube-controller-manager
tier: control-plane
spec:
containers:
- name: kube-controller-manager
image: vip/kube-controller-manager:v1.30.4-vip-multi-region
imagePullPolicy: IfNotPresent
command:
- kube-controller-manager
- --authentication-kubeconfig=/etc/kubernetes/controller-manager.conf
- --authorization-kubeconfig=/etc/kubernetes/controller-manager.conf
- --bind-address=0.0.0.0
- --client-ca-file=/etc/kubernetes/pki/ca.crt
- --cluster-name=kubernetes
- --cluster-signing-cert-file=/etc/kubernetes/pki/ca.crt
- --cluster-signing-key-file=/etc/kubernetes/pki/ca.key
- --controllers=*,bootstrapsigner,tokencleaner
- --kubeconfig=/etc/kubernetes/controller-manager.conf
- --leader-elect=true
- --requestheader-client-ca-file=/etc/kubernetes/pki/front-proxy-ca.crt
- --root-ca-file=/etc/kubernetes/pki/ca.crt
- --service-account-private-key-file=/etc/kubernetes/pki/sa.key
- --use-service-account-credentials=true
- --secure-port=10357
- --v=6
resources:
requests:
cpu: 200m
livenessProbe:
failureThreshold: 8
httpGet:
path: /healthz
port: 10357
scheme: HTTPS
initialDelaySeconds: 10
periodSeconds: 10
timeoutSeconds: 15
startupProbe:
failureThreshold: 24
httpGet:
path: /healthz
port: 10357
scheme: HTTPS
initialDelaySeconds: 10
periodSeconds: 10
timeoutSeconds: 15
hostNetwork: false
priorityClassName: system-node-critical
nodeSelector:
kubernetes.io/hostname: 10.189.110.47 # 调度到指定节点
tolerations: # 容忍所有污点
- operator: "Exists"
securityContext:
seccompProfile:
type: RuntimeDefault
|
效果
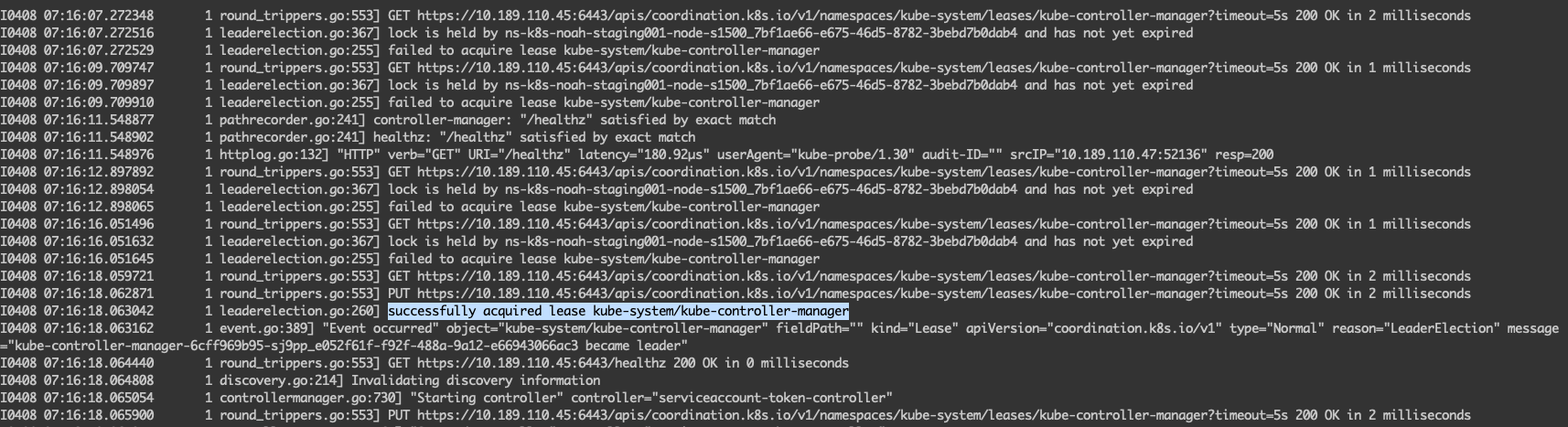
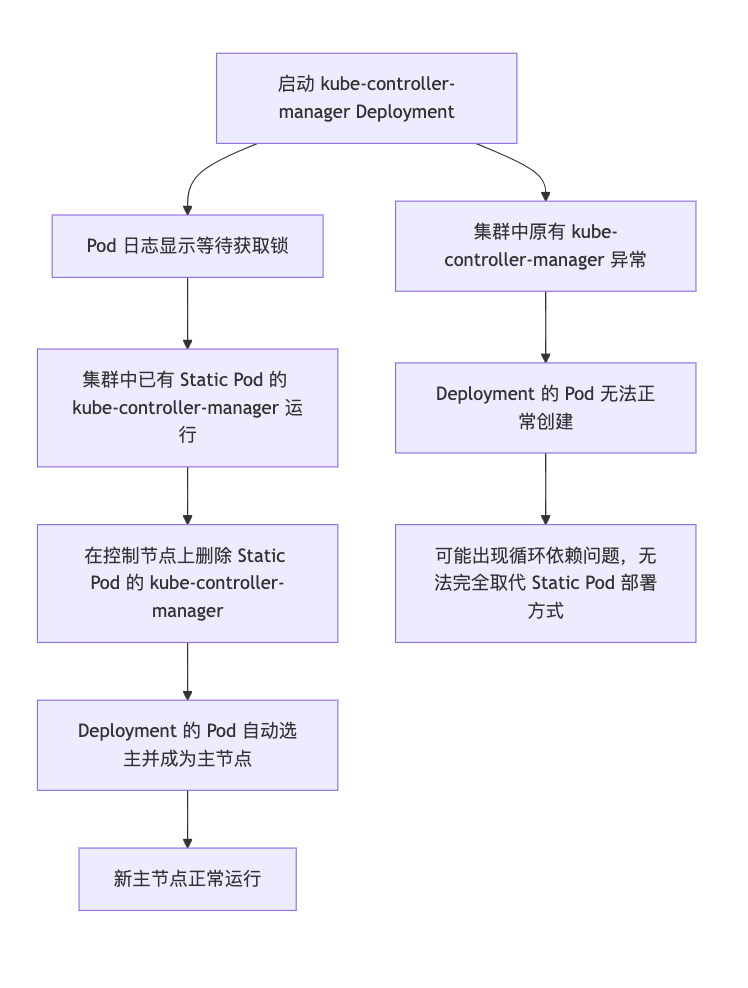
上面的 Deployment 的日志等级调节为 --v=6,因此可以观察到更多的信息,当刚创建好 kube-controller-manager 的 Deployment 的时候,可以看到 Pod 的日历显示,一直在等待获取锁,这也是符合预期的,因为集群里本来就有一个 Static Pod 的 kube-controller-manager 在运行着。

然后我们在控制节点上,将原来的 kube-controller-manager 的 Static Pod 删除掉,新的 Deployment 的 Pod 就会自动选主,成为新的主节点。
预期问题
因为当前是考虑用 Deployment 来部署 kube-controller-manager,如果在创建 Deployment 之前,集群中原有的 kube-controller-manager 出现异常,会导致新的 Deployment 是无法正常创建出来的,因此 Deployment 的方式并不能完全取代 Static Pod 的方式,因为有潜在循环依赖的问题。
警告
本文最后更新于 2025年4月5日,文中内容可能已过时,请谨慎参考。