弹性计算平台-Spark使用指南
概述
本文是笔者在前司建设的基于Kubernetes构建的弹性计算平台集成Spark的相关使用文档,我们是国内最早基于Kubernetes运行Spark计算任务的团队之一
Spark 是通用的大数据计算框架,弹性计算平台集成了 Spark,可供用户使用。目前平台默认支持最新版本的 Spark on Kubernetes 的支持,计算资源组根据平台特性进行了一些修改,让 Spark 可以更稳定的运行在 Kubernetes 集群中。
Spark支持的spark3是什么意思?
在使用 Spark 的时候,会发现版本可以选择 spark3,这里的意思是后台是通过 Spark on k8s Operator 来管理用户提交的 Spark 作业的,并且默认是提供是 v3.0.0-preview-rc1,由于 Spark 3.0 对 Spark on Kubernetes 的支持比之前的版本 Spark 2.3.0 ~ 2.4.4 都有较大幅度的提升,所以我们建议用户可以选择已经比较稳定的 v3.0.0-preview-rc1 来执行任务,下面是 Spark 3.0 在 on Kubernetes 上的一些提升。
- 支持非shuffle service的动态资源分配,具体内容可以参考KM文章Spark on Kubernetes的动态资源分配
- Executor Pod退出后支持通过
spark.kubernetes.executor.deleteOnTermination=false来保留 - 支持自定义Pod
作业jar包和资源文件如何上传?
在 Spark 弹性计算平台上,作业 jar 包指用户编写的 Spark 代码。资源文件是指运行 Spark 作业需要的文件。
Driver 和 Executor 启动,需要 Driver 和 Executor 的容器可以获得用户提交的作业 jar 包和其他资源文件。TenC Spark 以往是通过 文件服务器来让用户上传 Spark 程序下载这些文件的,不过在新发布的弹性计算平台,目前只支持用户上传文件到 S3 存储,然后由弹性计算平台将这些文件卷挂载到 Driver/Executor 上,Driver/Executor 会像读取本地文件的方式读取到这些文件,所以 jar 包路径只要写挂载的路径就可以,例如 /data/xx.jar,具体如下图所示。
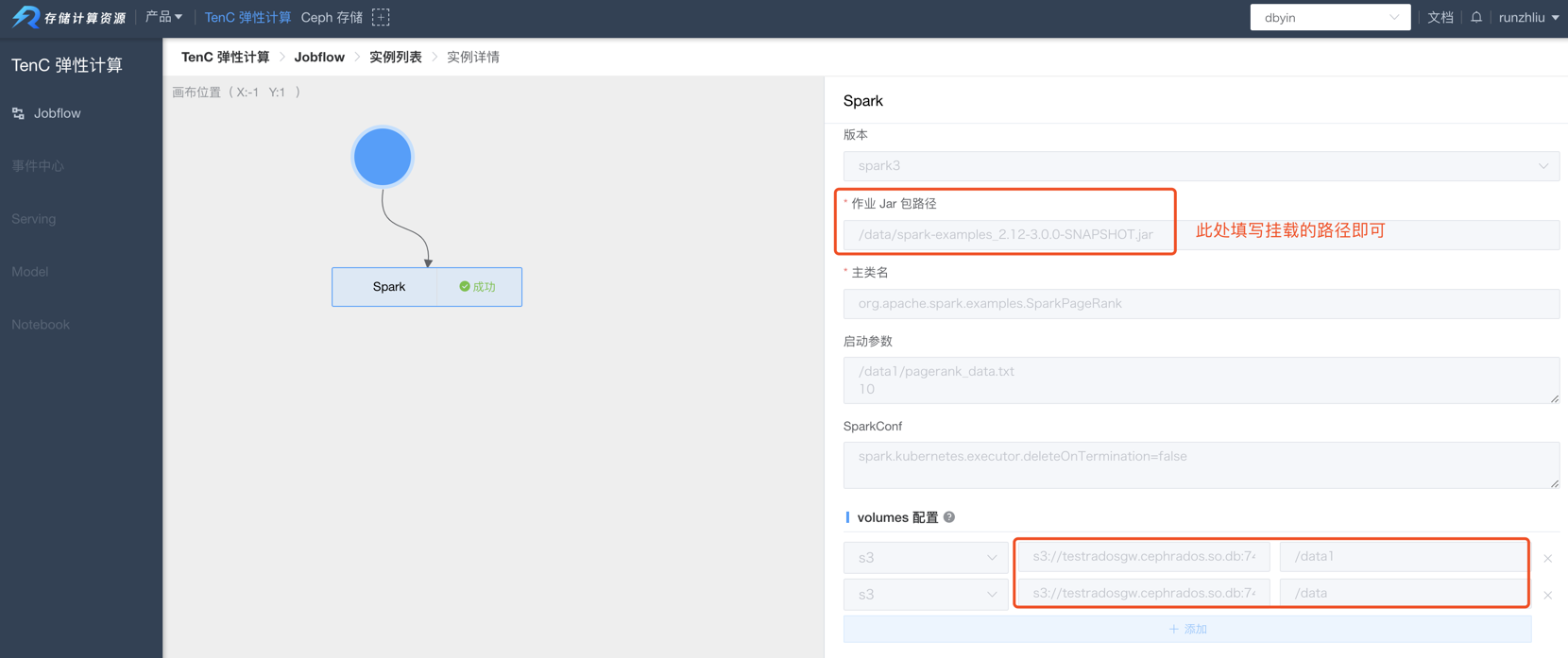
Spark如何通过intiContainer来挂载依赖
用户可以通过 init-container 将作业 jar 包和资源文件挂载到 Driver/Executor Pod,在指定作业 jar 包的时候填写本地文件系统,在读取资源文件的时候直接指定挂载的地址即可,其实现的基本原理如下图所示。
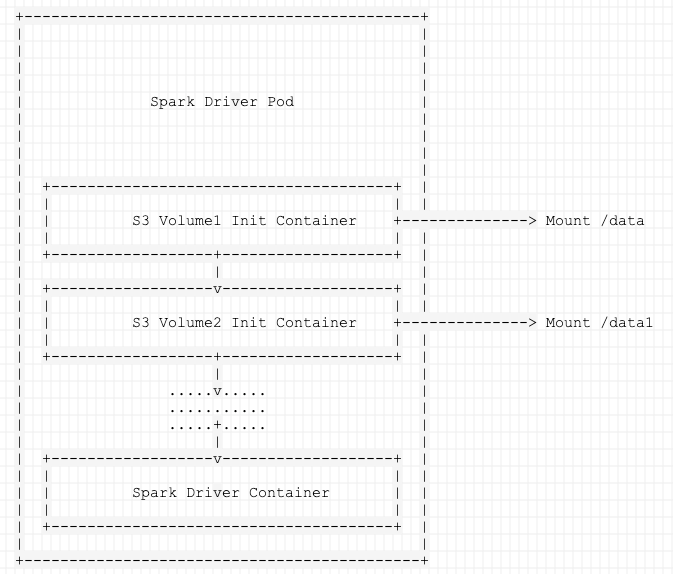
Spark的示例程序哪里可以找到
Spark 的示例程序是管理员预先配置好的,并且经过多次测试,主要是 Spark 官方的多个 Example 程序。用户只有只读和执行权限,为了了解 Spark 程序如何在 TenC 弹性计算运行起来,用户可以随意执行并且观察。
关于 Spark 官方的 Example 程序,可以在官方网址找到。
Spark任务出错了如何排除
Spark 任务出错,大概可以分为两个类型,一是提交任务出错,也就是 spark-submit,二是任务运行出错。
对于提交出错,一般会在前端页面中显示,如下图,出错原因是以为 jar 包路径有问题,解决方法就是确认 jar 是否在 S3 目录中。
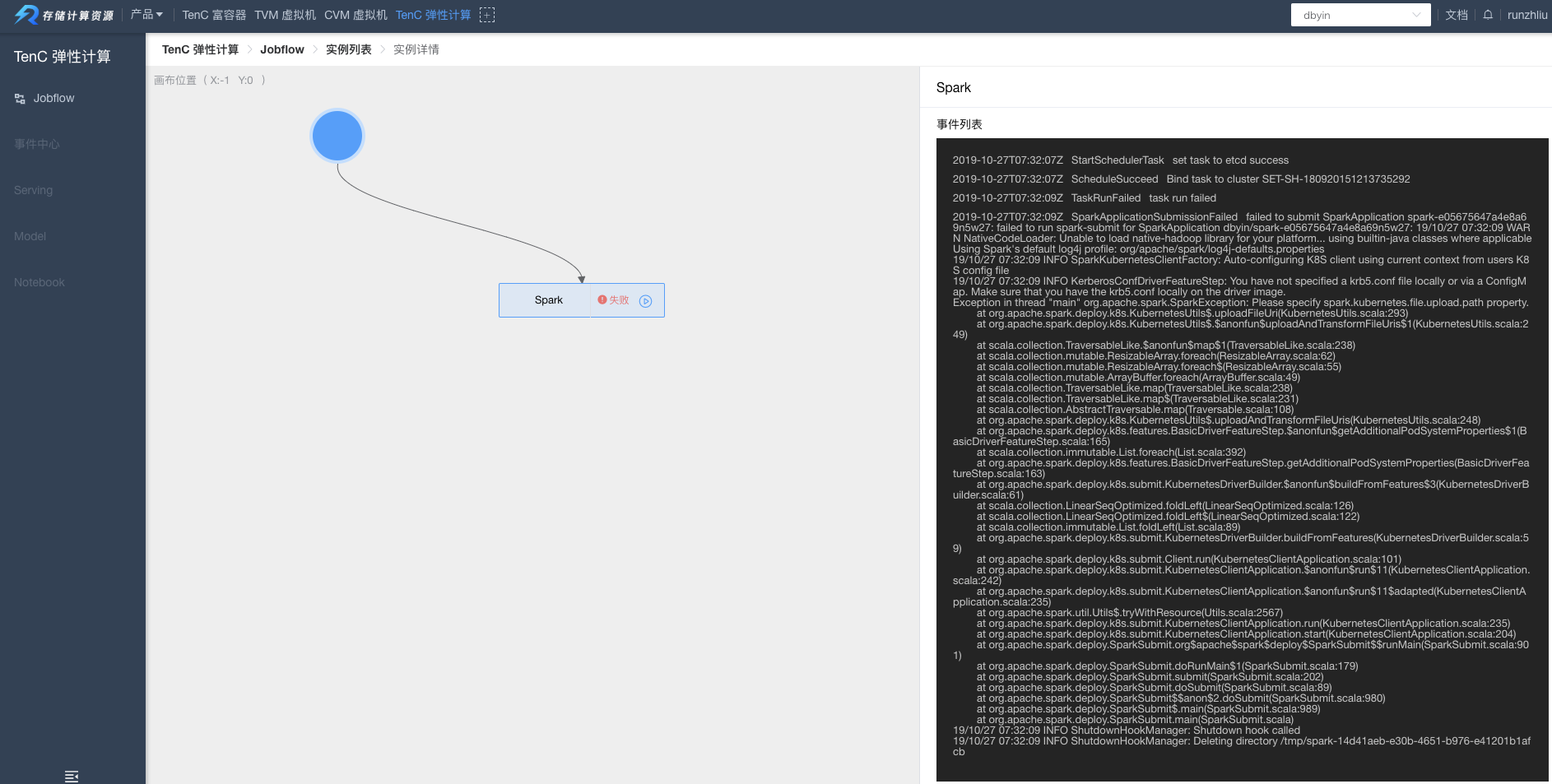
对于第二种情况,任务过程中出错,则可以通过 Pod 列表中,找到出错的 Pod,并且点击日志查看即可(注意筛选合适的 Pod 等条件),操作可参考下面的示例。
弹性计算提供Spark的默认镜像
提供如下镜像,tag 中 TenC 表示是由计算资源组构建的镜像,2.x.x 表示是基于 Apache Spark 社区的 2.x.x 版本。
|
|
如果用户需要自定义镜像并且同时使用 S3 挂载文件,那需要使用到上述镜像中的 jar 包(需要匹配基础镜像的 Spark 版本)。
|
|
用户可以运行自己构建的镜像吗
可以。如果用户需要自行构建 Spark 镜像,需要注意,只支持 Spark 2.3 以上,所以切勿使用 Spark 2.2 的自定义镜像。如果需要使用 Spark 2.2,请按下面例子进行配置,将版本设置成 spark2.2。
如果需要使用其他jar包应该如何配置?
有两种方法可以实现。
- 通过S3上传文件到目录
/data/xx.jar,然后根据Driver/Executor指定spark.driver.extraClassPath=/data/xx.jar - 自定义镜像,将用户的jar包放入
/opt/spark/jars或者其他CLASSPATH目录