如何管理和监控Apache-Spark-on-Kubernetes-Part2
概述
本文翻译自 Lightbend 的一篇文章,文章日期还比较新,2019/02/26。文章分为两部分,翻译也将分为两个部分。附上文章链接如下:
在上一篇文章中,介绍了 spark-submit 在 Kubernetes 集群模式中的使用,以及 Kubernetes Operator for Spark 的大致原理。在第二部分,文章会深入到 Spark Operator 的更多的工鞥呢,包括 CLI 的工具以及 Webhook 的特性。最后,本文会总结 spark-submit 和 Spark Operator 的优缺点。
什么是 Mutating Admission Webhook?
在本文完成的时候,Spark 的 Kubernetes 支持还不允许用户自定义 Spark Pods。这也是为什么会需要 Spark Operator 了,因为 Operator 支持自定义 Spark Pod,同时也支持 Mutating Admission Webhook 来克服上述提到的一些问题。Mutating Admission Webhook 是一个 HTTP 的回调,可以支持 Kubernetes 同时创建和修改 PodA 以及 mounting volumes,secrets 或者 ConfigMap 等等。
注意: 你可以定义两类型的 Admission Webhook,Validting Admission Webhook 和 Mutating Admission Webhook。前者可以拒绝请求以强制符合自定义的策略,后者可以允许修改请求符合自定义的一些默认值
MAW 需要 webhook server 满足和 API Servier 进行 TLS 认证。Spark Operator 默认的安装会自动将 webhook 配置好。
Now let’s take a look at uses cases of the webhook. First of all, the webhook supports mounting ConfigMaps in Spark pods, which can come in handy in the following scenarios:
现在看一下 webhook 的例子。首先 webhook 支持给 Spark Pods 挂载 ConfigMap,这样会在下面这些场景下非常方便:
- 通过挂载 spark-defaults.conf 之类的文件来指定 Spark configurations,或者是 spark-env.sh 或者 log4j.properties 文件都可以被挂载成 ConfigMap。然后 Spark 作业的 YAML 文件可以很方便的让 Operator 去使用这些 ConfigMap。
- 将 core-site.xml 和 hdfs-site.xml 文件通过 ConfigMap 挂载,然后在 Spark 作业的 YAML 文件可以很方便的让 Operator 去使用这些 ConfigMap。
webhook 也支持挂载 Volumes,这在 Spark History Server 很有用。为了运行 Spark History Server,需要满足两点,一是可以在 HDFS 或者 S3 之列的存储中读取 event log,第二是 Spark Driver 和 Executor 都可以读写同一位置的存储路径。如果日志是通过卷来存储,webhook 可以帮挂载合适的 Volume。下面是一个 Spark 作业的 YAML 例子,其在 Driver/Executro 都使用了一个叫做 spark-history-server-pvc 的 PersistentVolumeClaim,他们共同指向一个 Driver/Executor 叫做 /mnt 路径。
|
|
参考这篇文章,可以了解更多关于 webhook 的工作原理。
需要注意的是,有一个主要问题是 Operator 需要实现所有的功能,例如最近 Spark Operator 才开始支持 tolerations。
关于 spark-submit,在 Spark 3.0 发布之后,将会支持自定义的 Pod 配置等更丰富功能(存在一定条件的限制)。Operator 也会在未来支持更多的工鞥呢,因此以后也可能不再需要使用 webhook。
理解 Spark Operator 是如何管理 Spark 作业的生命周期
理解 Spark Application 的生命周期是十分重要的,因为这也是 Operator 使用的基础,理解其生命周期有利于在 debug 程序问题的时候更快的找出问题根源。
Spark Operator 可以创建两种 controller,分别是 SparkApplications 和 ScheduledSparkApplication,文章主要会介绍前者,因为后者其实是前者的某种程度上定制化的封装。
首先,可以去 Kubernetes 的官方文档去了解 Controller 的工作模式。
在 Kubernetes 中,一个 Controller 是一个监听共享状态的控制循环,并且可以不断循环地将当前状态转义到目标状态。
Controller 利用两个 SharedInformers,都是 Kubernetes API 的资源对象。SharedInformer 提供一个单独的共享缓存来记录监听对象的变化。
其中一个 Informer 是监听 Pod 的 State 变化,另外一个是监听 CRD 的变化。这两个 Informer 都提供一种回调的机制去回应 Add,Update 和 Delete 的状态。
Controller 与 Informers 共享工作队列。每当有更新,Informer 就会将事件加入到队列,事件的产生是并行的。所有事件都会被处理,SparkApplication 的状态会被 Operator 同步,所以 Informer 的缓存每30秒会重新同步一次。
因此,即使 Operator 挂掉了,而事件在这段时间内丢失,他会将 SparkApplication 列出,并且通过内部的数据结果进行适当的更新。
Due to the use of the shared informer, the updates will not be fully replayed but only the latest event related to the application will be delivered according, as discussed here.
由于使用了 SharedInformer,更新操作不会完全重放,但是会把 application 最近的一次事件转发,就像这里的注释讨论的一样。
一个 SparkApplication 有如下的生命周期,下面是示意图。
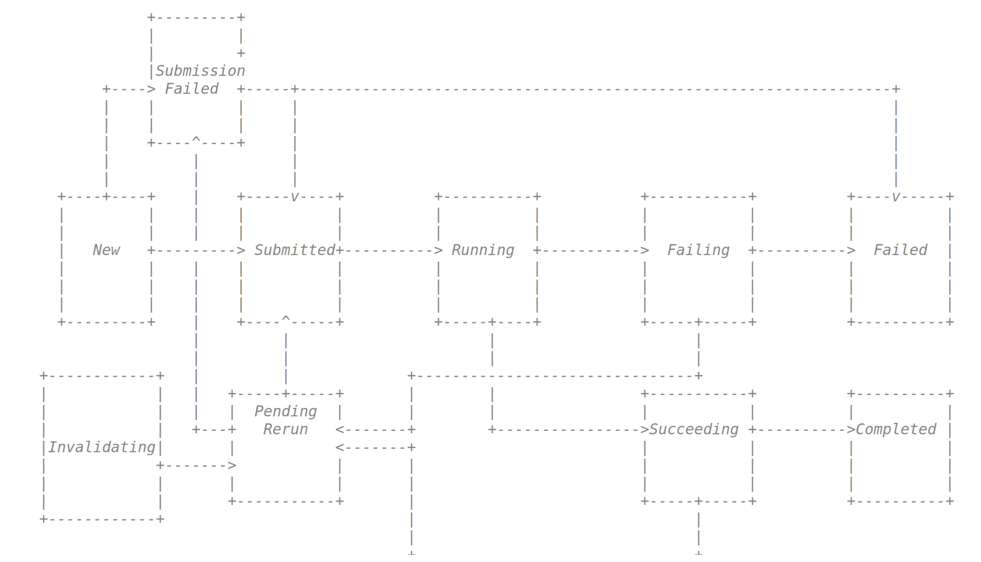
当一个 CRD 被创建之后,一个 Application 对象也被创建了,其当前的状态是 New。这时候整个 Spark 作业还没有开始真正的运行。Informer 会创建一个包含 Application 状态的对象,提交到工作队列中。
当对象进入到工作队列,并且被 Controller 调用,他会尝试通过 Spark 底层的 spark-submit 工作来真正的提交任务,如果提交成功,Application 此时的状态会变成 Submitted,否则就会变成 Submission Failed。
如果任务成功提交,Spark 会通过 Kubernetes API Server 创建 Driver Pod,这个步骤跟原生的 spark-submit 是一样的。
如果 Mutating Admission Webhook 是 enabled 的话,Pod 对象会在被存储到 Kubernetes 的之前被检查。
然后,Pod 会被调度运行,Informer 会通知 Contorller 新的 Pod 的加入。
Spark 作业会根据作业运行情况,更新其状态。
|
|
更多的关于 Pod 的声明周期的解释,可以参考 Kubernetes 的官方文档。注意 completed 状态在 Spark Operator 没有在这里被使用,原因是 Completed 其实是 Succeeded 和 Failed 两种状态的衍生状态,可以参考官方仓库的注释。
当用户更新 Spark 作业的自定义资源对象,其会变成 Invalidating 状态,然后相同的 Spark 作业又会被处理,然后就是到 PendingRerun 状态,就可以相当于是重新提交了。
还有一种情况 application 可以到达 PendingRerun 状态。如果 Spark 作业处于 Succeeding 或者 Failing 状态,如果已经定义了重试的策略,该作业会被置为 PendingRerun 的状态。
这里有几个关于重试策略的配置的官方介绍。
需要注意的是,终结状态只有两种情况,一是 Failed,第二是 Completed。
提示: 用户可以检查
SparkApplication的状态转换过程的,可以同kubectl logs -n . b,又或者通过 Kubernetes 的事件 API,kubectl get events -n,又或者通过kubectl describe sparkapplication -n来检查结果。
Spark Operator 的操作
Spark Operator 提供了一个工具来管理 Spark 作业,其实也是一个类似于 kubectl 的供 CLI 工具,称为 sparkctl。例如,一个简单的查询 Spark 作业的管理,可以查询 job 的状态,listing 提交过的 jobs,又或者是停止 jobs。
例如,列出所有提交过的 jobs。
|
|
获取 spark-pi 作业的状态。
|
|
或者 spark-pi 作业的日志。
|
|
需要注意的是,所有的这些操作,都可以通过使用 kubectl 来获取 CRDs 的状态。但是在一些情况下,需要使用更复杂的选项才能达到和 sparkctl 封装完的效果。
例如使用 kubectl 列出所有提交完的作业。
|
|
获取 spark-pi 作业的详细信息。
|
|
为了通过 kubectl 获取作业的日志,你首先需要找到 SparkApplication 创建的 Driver/Executor Pod 的名字,然后再运行 kubectl logs。
此外 sparkapplications(s) 太长了,可以通过缩写 sparkapp 达到同样的目标。
Spark Operator 的使用例子
Let’s take a look at an real example of using the Operator, covering submitting a Spark job to managing it in production.
现在我们看一个具体的实践例子,看看如果通过 Spark Operator 提交和管理你的 Spark 作业。
假设你已经通过 Helm Chart 安装好了 Spark Operator,你可以通过写一个 YAML 文件来自定义你的 job。
|
|
上面的 YAML 文件定义了 spark-pi 这个 Spark 作业,可以看到 Driver/Executor 的资源使用,这里需要注意两个地方,一个是 service account,另一个是挂载的 voluem。
当 Operator 被 Helm Chart 安装到你的 Kubernetes 集群,那里会有一个 option,--set sparkJobNamespace=,如果没有给值,那么 Spark 作业会运行在 default 的 Namespace 下。另外还有 service account,这里可以设定合适的 service account 来管理 Spark 作业的 Pods 和相应的 Services。
YAML 文件中也看到一个config-vol 的 ConfigMap 需要挂载作为配置文件的读取的路径。
|
|
ConfigMap my-cm 需要在同一个 namespace 下存在,然后才可以被 Mounted 到 Driver/Executor Pod。
现在可以提交这个任务了。
|
|
或者
|
|
然后可以通过下面的命令检查 Spark 作业是否已经运行了。
|
|
如果想查看 job 的状态和日志,可以按照上文提供的方法,用下面的命令。
|
|
如何选择 spark-submit 还是 Spark Operator
由于 spark-submit 就是 Apache Spark 的内置原生的提交任务的工具,所以对于用户来说,已经习惯了并且也非常容易使用。
通过 spark-submit 也可以直接将任务提交到 Kubernetes 集群,同样也很容易去集成一些工作流的工具比如说 Apache AirlFlow 等等。尽管这是非常容易使用的,但是 spark-submit 显然缺乏了一种类似于 Spark Operator 那样管理已经提交作业的机制,因此如果是提价到 Kuebernetes 集群,用户不得不通过 kuberctl 来完成这些操作,而这样的操作往往是比较麻烦,而且容易出错的,比如你要删除一个 Spark 作业,那必须保证这个 Spark 作业的 Driver/Executor Pod 和 Service 都能完全删除。
此外,Spark Operator 还能提供直接的 Monitor 的工具来协助管理 Spark 作业的状态,也可以很方便的查看日志等等,这才一个多租户的 Kubernetes 集群的时候是非常方便的。
Spark Operator 还提供挂载 Volumes 和 ConfigMap 这样的操作来自定义 Driver/Executor Pod,当然了, Spark 接下来的发布中也会开始支持这些自定义的操作。
不过需要注意的是 Spark Operator 虽然发展非常迅速,但是仍然处在 beta 阶段,也就是还没有在正式的生产环境中得到验证,这会在一定程度和方面影响到用户的使用体验,例如有限的多租户支持等。最后,Spark Operator 也一定程度上增大了 Spark 任务提交过程中出错 debug 的难度,因为作业提交的过程完全是在 Operator 中发生。