概述
基于 Spark 的 vllm 推理,简单来说就是结合 Spark 的数据处理能力和 vllm 高性能的推理能力,为业务提供大规模的离线批量推理的能力。事实上,在大模型出来之前,类似的离线批量推理,主要是针对 Tensorflow 或者 Pytorch 的推理框架进行离线的批量推理,因此这个 topic 并不新鲜。
业务问题
而我司之前一直有个比较特殊的离线批量推理的方式,业务通过部署正式的生产级别的推理服务,然后在 Notebook 上直接将推理的请求通过 Python 的一些并发库来实现大规模的离线推理。这里有几个问题:
- Notebook随意访问生产级别的服务
- 生产级别的在线服务要承受无法预估的并发压力
- 生产级别的在线服务并发高的情况产生大量告警
- 生产级别的在线服务的实例数申请下来之后没有合理的缩容机制会造成大量的资源浪费
之前业务方包括其他同事考虑过通过消息队列来接受用户的 HTTP 请求,然后在在线推理服务前通过引入一个消费者来控制业务的批量推理,听起来这个方案是可以的,但还是有几点问题:
- 依然是在生产级别的在线推理服务上走钢丝
- 需要实现从生产者对消费者处理业务请求的逻辑
仔细一看,既需要能够根据离线推理的请求量动态调整推理服务的实例数,又能保证业务的离线推理在一定程度上实现容错和重试的机制,这不就妥妥就是一个 Spark 的并行计算的模型…通过 Spark 集成高性能的推理框架,以离线批量的计算任务的方式,不仅不需要在生产级别的在线推理服务上走钢丝,让业务彻底告别在 Notebook 上进行生产级别的离线批量计算,还能提升整体的 GPU 资源利用率。
个人为什么支持采用 Spark 来处理离线批量推理,有几点,首先业务需要处理的数据大部分来自大数据的存储体系,比如 Hive,HDFS,Spark 在其中发挥的作用就不多说了,一直都是标准,其次,Spark 本身的分布式计算能力,还能根据数据的处理量进行弹性伸缩资源,就因为这两点,Spark 可以在大模型的离线批量中发挥很大的作用,最后就是 Spark on Kubernetes 本身已经不是什么特别新颖的技术架构了,类似的架构本人在2018年就已经开始实践并且大规模使用,因此剩下的问题就是如何做一个 Demo,说服业务接受这样的改造,用户以后只需要编写他们熟悉的 PySpark 程序就可以一边对数据进行 ETL,一边进行大规模的离线批量推理。
技术架构
因为我们的在线推理都是建立在 Kubernetes 的 GPU 集群以上的,2025年了,应该不会还有公司不是这样的架构了吧。基于 Kubernetes 的话,我个人不建议还是用 Yarn 的一套了,虽然 Yarn on Kubernetes 还有在发展,但是我一直觉得从资源管理的角度考虑,Kubernetes 才是最终态,我建议直接上 spark-operator,何况 spark-operator 的方式已经非常成熟了,结合 volcano 或者其他批调度的框架,可以非常轻松构建大规模的 Spark 计算任务。
spark+vllm实战
实战的前提是有一个较新版本且功能正常的 Kubernetes 集群,部署好较新版本的 spark-operator,dcgm-exporter,nvidia-docker…等等,另外还有一个比较困难的就是,得打出一个合适的镜像,既有 cuda,vllm 还要有 Spark,甚至还有有 Spark Rapids 的 Jar 等等。下面我将提供一个 Dockerfile 的示例,读者朋友们可以参考 Dockerfile 打一个镜像出来,之后提供一个测试的 req.py 作为 PySpark 的程序,最后再提供一个 SparkApp 的 yaml,直接在集群 apply 即可!
Dockerfile
下面这个 Dockerfile 应该是不难理解的,首先 nvcr.io/nvidia/pytorch:24.01-py3 是 Nvidia 提供的官方 PyTorch 镜像,已经包含了合适的 Python,cuda 以及 GPU 需要用到的合适的库了。然后就是安装 openjdk-8-jre,因为我们跑 Spark 任务的时候,镜像里是要启动 Driver 或者 Executor,然后就是 Spark Rapids 的 Jar,毕竟我们 Spark on GPU 的时候可能会用到相关的 GPU 加速,最后 pip3 install transformers vllm,可以给镜像提供大模型推理的必要库。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
|
FROM nvcr.io/nvidia/pytorch:24.01-py3
ARG spark_uid=185
# https://forums.developer.nvidia.com/t/notice-cuda-linux-repository-key-rotation/212771
RUN apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/3bf863cc.pub
# Install java dependencies
ENV DEBIAN_FRONTEND="noninteractive"
RUN apt-get update && apt-get install -y --no-install-recommends openjdk-8-jdk openjdk-8-jre
ENV JAVA_HOME /usr/lib/jvm/java-1.8.0-openjdk-amd64
ENV PATH $PATH:/usr/lib/jvm/java-1.8.0-openjdk-amd64/jre/bin:/usr/lib/jvm/java-1.8.0-openjdk-amd64/bin
RUN set -ex && \
ln -s /lib /lib64 && \
mkdir -p /opt/spark && \
mkdir -p /opt/spark/jars && \
mkdir -p /opt/spark/examples && \
mkdir -p /opt/spark/work-dir && \
mkdir -p /opt/sparkRapidsPlugin && \
touch /opt/spark/RELEASE && \
rm /bin/sh && \
ln -sv /bin/bash /bin/sh && \
echo "auth required pam_wheel.so use_uid" >> /etc/pam.d/su && \
chgrp root /etc/passwd && chmod ug+rw /etc/passwd
COPY spark/jars /opt/spark/jars
COPY spark/bin /opt/spark/bin
COPY spark/sbin /opt/spark/sbin
COPY spark/kubernetes/dockerfiles/spark/entrypoint.sh /opt/
COPY spark/examples /opt/spark/examples
COPY spark/kubernetes/tests /opt/spark/tests
COPY spark/data /opt/spark/data
COPY rapids-4-spark_2.12-*.jar /opt/sparkRapidsPlugin
COPY getGpusResources.sh /opt/sparkRapidsPlugin
COPY test.py /opt/sparkRapidsPlugin
COPY gpu.py /opt/sparkRapidsPlugin
COPY matrix.py /opt/sparkRapidsPlugin
RUN mkdir /opt/spark/python
COPY spark/python/pyspark /opt/spark/python/pyspark
COPY spark/python/lib /opt/spark/python/lib
ENV SPARK_HOME /opt/spark
WORKDIR /opt/spark/work-dir
RUN chmod g+w /opt/spark/work-dir
ENV TINI_VERSION v0.18.0
ADD https://github.com/krallin/tini/releases/download/${TINI_VERSION}/tini /usr/bin/tini
RUN chmod +rx /usr/bin/tini
ENTRYPOINT [ "/opt/entrypoint.sh" ]
# Specify the User that the actual main process will run as
RUN pip3 install transformers vllm
#USER ${spark_uid}
|
PySpark程序
本文的测试程序是计划在 Spark 的 Executor 里通过 sidecar 部署一个 vllm 推理服务,然后让 Executor 容器把推理请求发送到 Pod 本地的 8000 端口就可以做推理了,这个 req.py 程序可以写到镜像里,或简单地通过 HostPath 挂载上去,毕竟测试的时候可能会有很多调整的地方,另外关于 PySpark 的逻辑就不多说了,非常简单,就是随机生成一些提问的文本,拿来请求大模型的推理服务得到结果,生产环境下,可能是通过各种 ETL 从 Hive 或者 HDFS 上获取数据。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
|
import random
import json
import requests
import socket
import time
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StructField, StringType
# 创建 SparkSession
spark = SparkSession.builder \
.appName("OpenAI-Compatible API Inference with Qwen") \
.getOrCreate()
# 随机生成问题的函数
def generate_random_questions():
prompts = [
"What is the meaning of life?",
"Tell me a story about AI.",
"How does quantum computing work?",
"Explain deep learning in simple terms.",
"What are the benefits of renewable energy?",
"What is the future of artificial intelligence?",
"How does blockchain technology work?",
"Can you explain the concept of entropy?",
"What are the applications of machine learning?",
"How do neural networks learn?",
"What is the role of data in AI development?",
"Can AI replace human creativity?",
"What are the ethical challenges of AI?",
"How do self-driving cars work?",
"What is the importance of cybersecurity?",
"How does reinforcement learning work?",
"What is the Turing test?",
"How does natural language processing work?",
"What are the differences between supervised and unsupervised learning?",
"How can AI help in climate change?",
]
return random.choice(prompts)
# 检查端口是否开放的函数
def check_port_open(host, port, max_wait_minutes=10, interval_seconds=5):
"""
检查指定主机和端口是否开放。
:param host: 主机地址
:param port: 端口号
:param max_wait_minutes: 最大等待时间(分钟)
:param interval_seconds: 每次重试的间隔时间(秒)
"""
max_attempts = int((max_wait_minutes * 60) / interval_seconds)
attempts = 0
while attempts < max_attempts:
try:
print(f"Attempting to connect to {host}:{port} (attempt {attempts + 1}/{max_attempts})...")
with socket.create_connection((host, port), timeout=5): # 尝试建立连接,5 秒超时
print(f"Successfully connected to {host}:{port}!")
return True
except (socket.timeout, ConnectionRefusedError) as e:
print(f"Connection to {host}:{port} failed: {e}")
attempts += 1
time.sleep(interval_seconds)
print(f"Unable to connect to {host}:{port} after {max_wait_minutes} minutes.")
return False
# 在分区中调用 OpenAI-Compatible API 的函数
def run_inference_with_http(partition):
http_server_host = "127.0.0.1"
http_server_port = 8000
# 检测端口是否开放(仅在 executor 内部执行)
if not hasattr(run_inference_with_http, "_port_checked"):
if not check_port_open(http_server_host, http_server_port):
raise RuntimeError(f"Executor failed to connect to {http_server_host}:{http_server_port}")
run_inference_with_http._port_checked = True # 设置标志,防止重复检测端口
results = []
for _ in partition:
# 随机生成问题
question = generate_random_questions()
# 构造请求数据
payload = {
"model": "Qwen/Qwen2.5-1.5B-Instruct",
"messages": [
{"role": "system", "content": "You are Qwen, created by Alibaba Cloud. You are a helpful assistant."},
{"role": "user", "content": question}
],
"temperature": 0.7,
"top_p": 0.8,
"repetition_penalty": 1.05,
"max_tokens": 512
}
# 调用 HTTP 服务(无重试机制,推理失败直接失败)
try:
response = requests.post(
f"http://{http_server_host}:{http_server_port}/v1/chat/completions",
json=payload,
timeout=15 # 调整超时时间为 15 秒
)
response.raise_for_status() # 检查 HTTP 响应状态
result = response.json()
# 提取生成的回答
answer = result["choices"][0]["message"]["content"]
results.append((question, answer))
except requests.exceptions.RequestException as e:
print(f"Error calling HTTP server: {e}")
raise RuntimeError(f"Failed to call HTTP server: {e}")
# 如果所有推理完成,则直接返回结果,不再关注端口状态
return results
# 主程序入口
if __name__ == "__main__":
# 创建一个包含 10 条记录的 RDD
data = [("placeholder",)] * 10 # 模拟 10 条数据
schema = StructType([
StructField("placeholder", StringType(), True)
])
df = spark.createDataFrame(data, schema)
# 使用 mapPartitions 调用 HTTP 服务
try:
rdd = df.rdd.mapPartitions(run_inference_with_http)
# 转换结果为 DataFrame
result_df = spark.createDataFrame(rdd, schema=["question", "answer"])
# 展示推理结果
result_df.show(n=10, truncate=False)
except Exception as e:
# 捕获异常并打印错误信息
print(f"Job failed due to error: {e}")
spark.stop() # 优雅停止 SparkSession
raise
|
SparkApp
下面是最终提交 SparkApp 的 Yaml 文件,有几点需要注意:
- 挂载的HostPath是笔者在服务器上已经下载好模型的目录,如果读者也有,可以将目录改掉,否则就需要通过网络去Hugging Face下载了
- Executor中有两个容器,一个sidecar是作为vllm推理服务启动改掉,另外的就是正常的Spark Executor
- Executor因为需要通过vllm部署容器,所以内存不能给太小,还要记得给GPU资源
- sidecar和Executor的容器启动是没有顺序的,Executor需要探测vllm服务的端口再进行推理,当然还有其他方式实现,比如单独启动一个vllm server的Pod或者其他方式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
|
apiVersion: "sparkoperator.k8s.io/v1beta2"
kind: SparkApplication
metadata:
name: spark-vllm-batch
namespace: default
spec:
sparkConf:
"spark.ui.port": "4045"
"spark.executor.memory": "1g"
"spark.rapids.memory.pinnedPool.size": "2g"
"spark.executor.memoryOverhead": "3g"
"spark.sql.files.maxPartitionBytes": "512m"
"spark.sql.shuffle.partitions": "10"
type: Python
pythonVersion: "3"
mode: cluster
image: "registry.cat.dog/runzhliu/spark-gpu:vllm"
imagePullPolicy: Always
mainApplicationFile: "local:///root/.cache/huggingface/req.py"
sparkVersion: "3.4.4"
restartPolicy:
type: Never
volumes:
- name: "huggingface-cache-volume"
hostPath:
path: "/mnt/k8s/docker/hf/huggingface" # 宿主机上的目录
type: Directory
- name: "test-volume"
hostPath:
path: "/tmp"
type: Directory
driver:
serviceAccount: spark-operator-spark
cores: 1
coreLimit: "1200m"
memory: "1024m"
labels:
version: "3.4.4"
volumeMounts:
- name: "test-volume"
mountPath: "/tmp"
- name: "huggingface-cache-volume"
mountPath: "/root/.cache/huggingface" # 容器内的路径
executor:
cores: 1
instances: 1
memory: "15000m"
labels:
version: "3.4.4"
volumeMounts:
- name: "test-volume"
mountPath: "/tmp"
- name: "huggingface-cache-volume"
mountPath: "/root/.cache/huggingface" # 容器内的路径
sidecars: # 添加 sidecar 容器配置
- name: vllm-sidecar
image: "registry.cat.dog/runzhliu/spark-gpu:vllm"
imagePullPolicy: Always
command: ["/bin/bash", "-c"]
args: [
"vllm serve Qwen/Qwen2.5-1.5B-Instruct --dtype=half --host 0.0.0.0"
]
resources:
limits:
nvidia.com/gpu: 1 # Sidecar 也使用 GPU 资源
volumeMounts:
- name: "test-volume"
mountPath: "/tmp"
- name: "huggingface-cache-volume"
mountPath: "/root/.cache/huggingface" # 挂载相同目录
|
效果
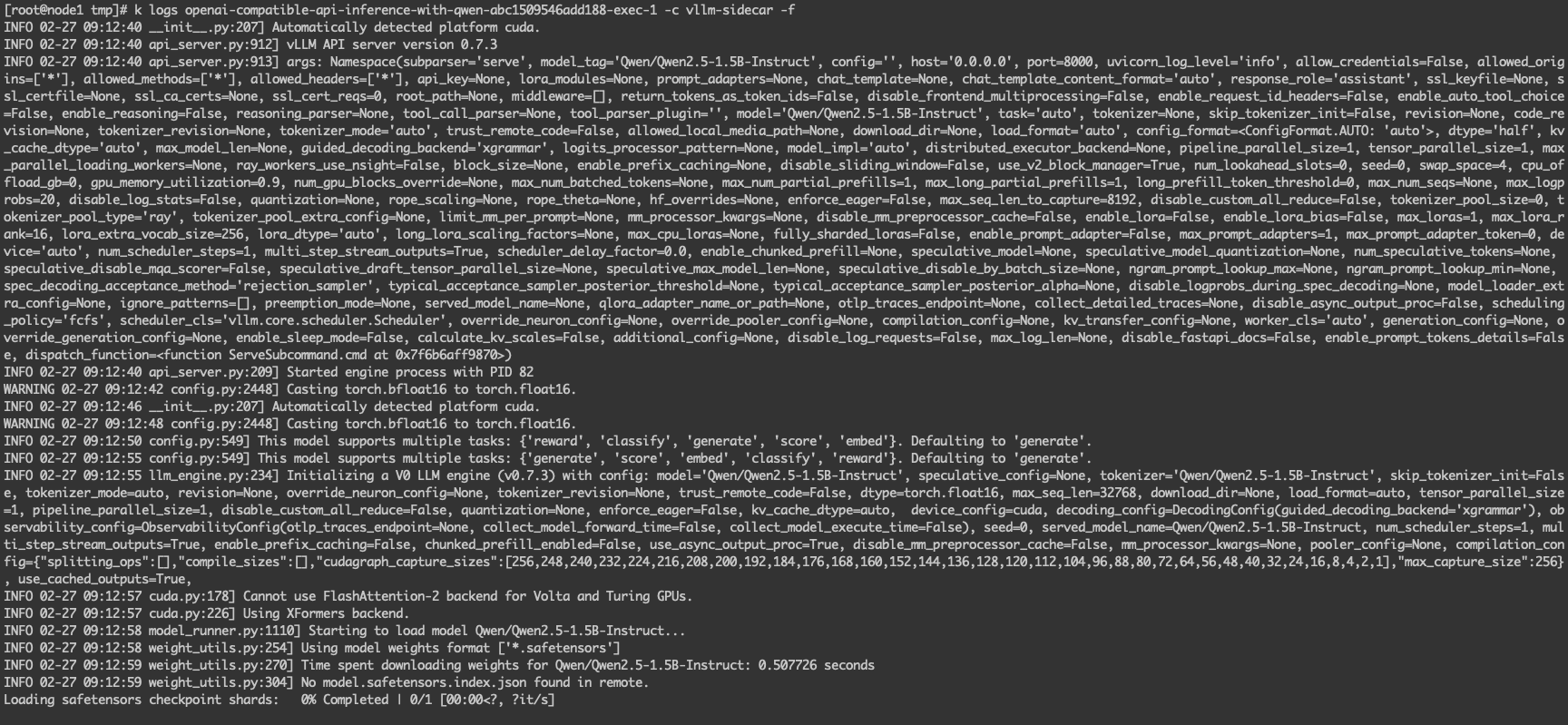
容器已经正常启动了。

查看日志 vllm 的推理服务是否正常启动。
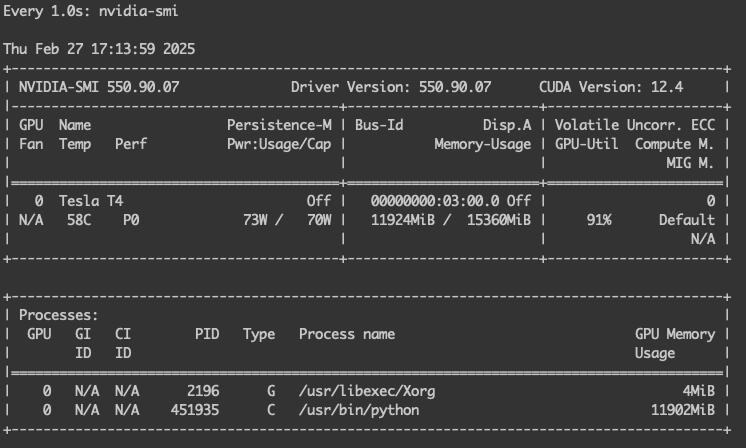
查看 GPU 是否有正常加载模型。
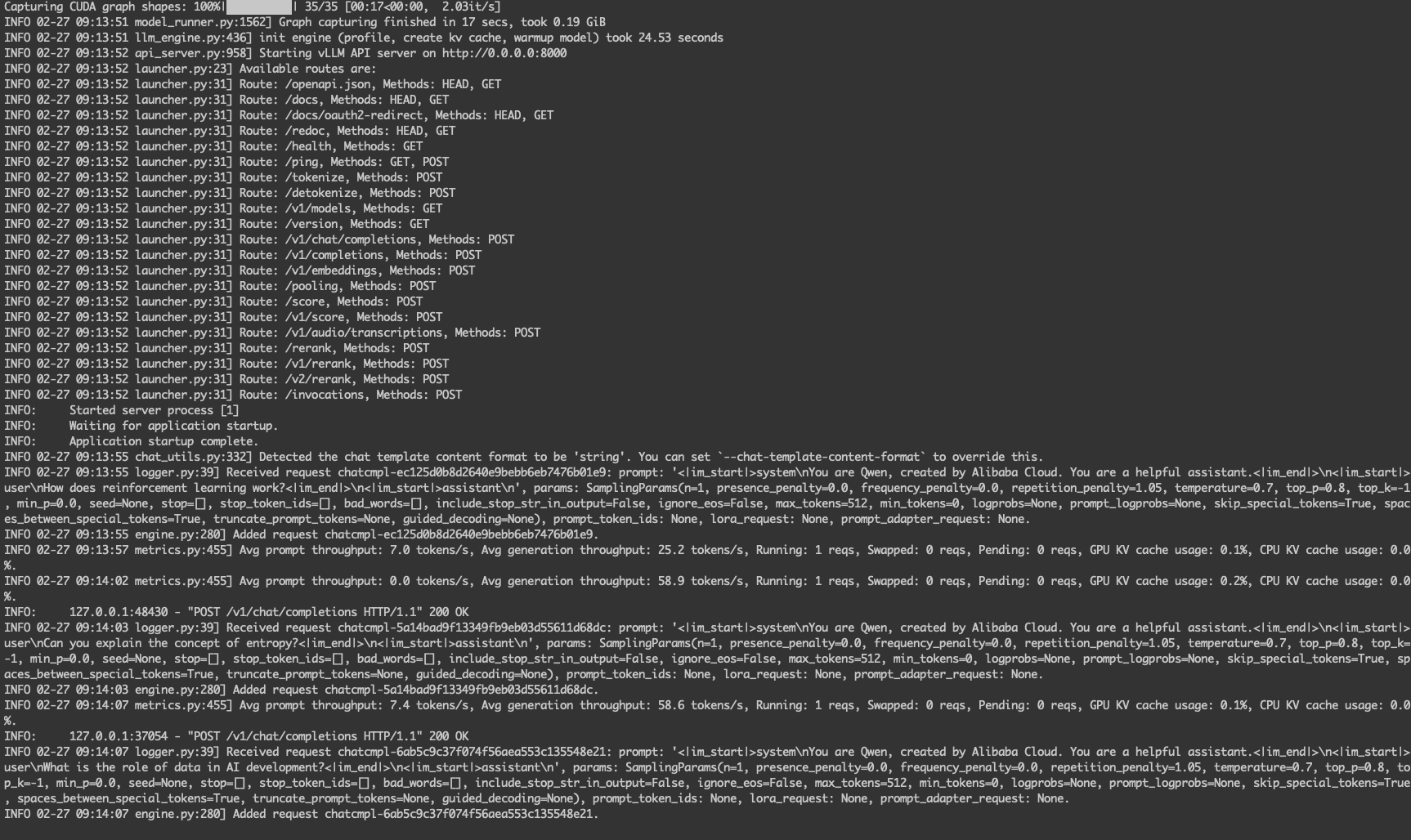
模型加载好之后,就开始接受推理的请求。
离线批量推理结束后,查看 Driver 的日志,日志最后会打印推理的结果
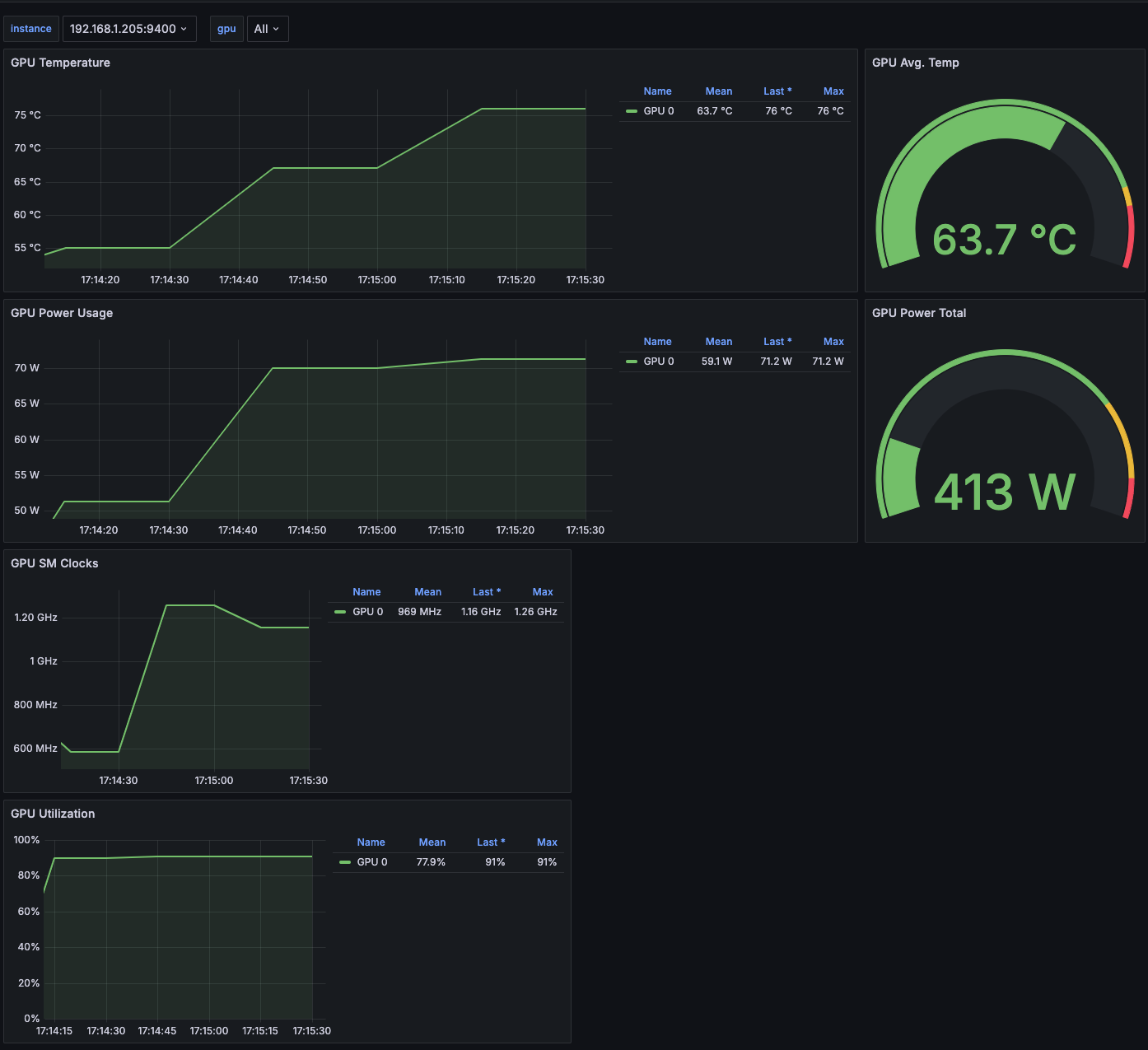
从利用率看,这样的批量推理可以把 GPU 的利用率打的非常高。
一些想法
十年前 Spark 非常火热,Spark 养起了数以万计的大数据工程师,经过十几年的发展了 Spark 越来越成熟了,以至于都作为大数据行业的事实标准了,尽管一直以来都有大量的框架冲击,但是 Spark 在大规模的数据处理场景下,还是一直能够发挥重要的力量。
尽管 Spark 曾经这么火热,但随着 Kubernetes 的发展,大模型 AI 时代的到来,Spark 的热度已经大不如前了,以至于我在写这篇文章的时候,都没看到太多关于用 Spark 来做 vllm 的离线批量推理的相关文章,不知道是大家早就默契地以这样的方式丝滑的实现了批量离线推理的业务架构,还是说 Spark 已经不在大家考虑的组件架构类型上。Anyway,写这篇文章还是觉得 Spark 在这种场景下还是大有作为的,希望可以作为各位在大模型领域上的一种架构的考虑。
参考资料
- 使用GPU在Apache Spark上加速JSON处理
- Deep Learning Inference on Spark
- PySpark LLM Inference: DeepSeek-R1 Reasoning Q/A
- Efficient Distributed LLM serving
- spark-rapids
- Running Spark Applications using Spark Operator
警告
本文最后更新于 2025年2月25日,文中内容可能已过时,请谨慎参考。