在k8s部署Spark-History-Server-篇1
目录
概述
要在 K8S 集群中部署一套 Spark History Server,首先要了解,怎么部署一个本地版本。然后就是了解一些基本的 K8S 相关的知识点。最后就是两部分知识结合起来,看看业界流行的方案是如何实现的。
Spark History Server 缩写成 HS
Spark History Server本地试玩
其实 Spark官网关于如何部署 Spark History Server 是有很详细的说明的。这里以 Spark 2.3.0 为例。
总体来说 start-history-server.sh,可以启动 HS 的进程。

默认通过访问 18080 端口,就可以将 job 的历史信息(注意还包括 on-going,也就是正在运行的 job)。
Spark Job 需要打开两个配置。
|
|
为了在本地起一个 HS 的后台进程,我们可以下载 Spark 的发行包。
创建一个目录,来放 event log。
|
|
然后运行一个 SparkPi 程序,只要有配置 Java Home,正常 JDK8 都能跑起来的。
|
|
只要配置了 event log 的位置,日志就能看到以下信息。
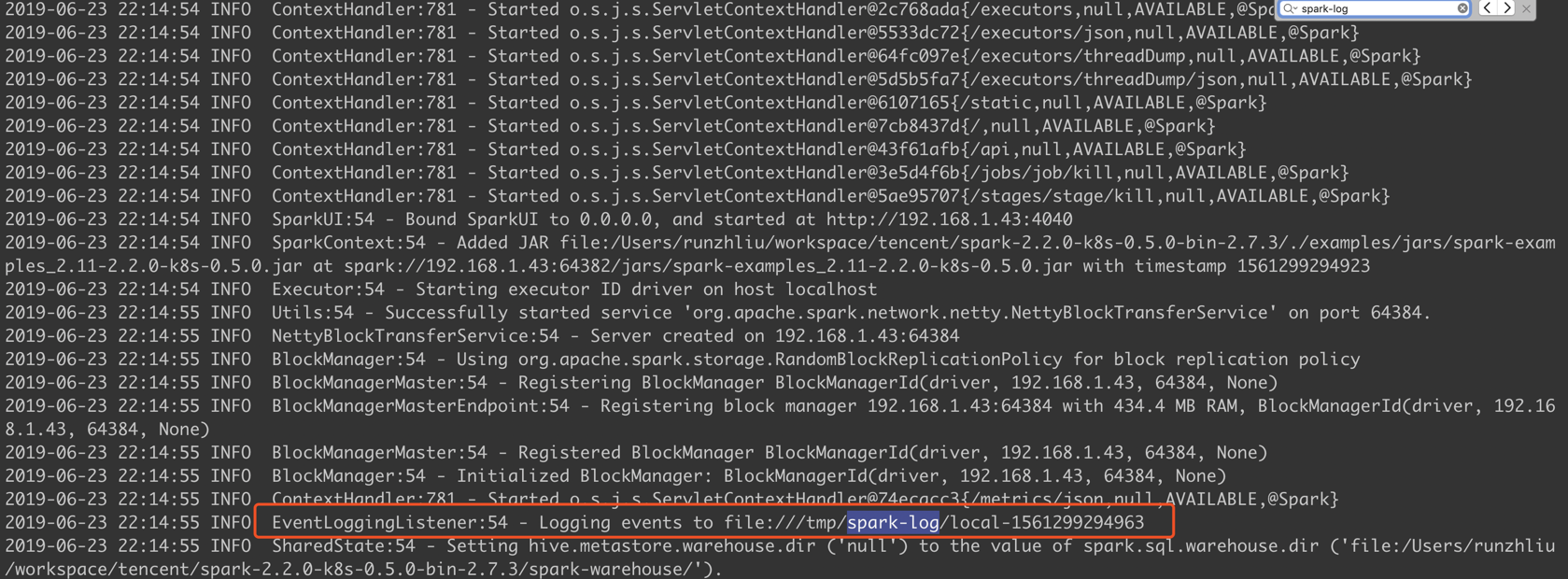
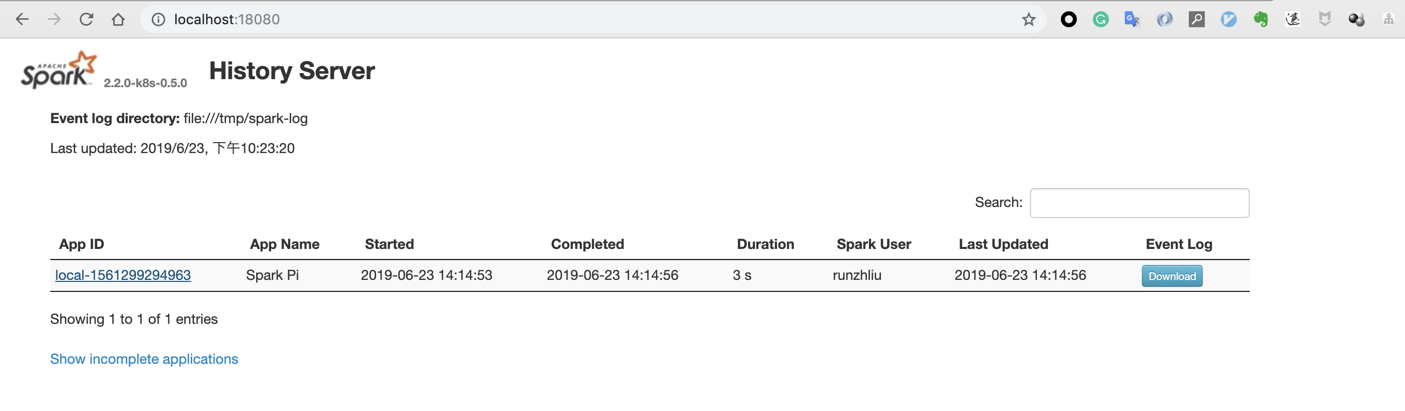
因为启动 HS 的进程需要 event log,现在有了,所以就能启动了。查看 18080 默认端口的页面。
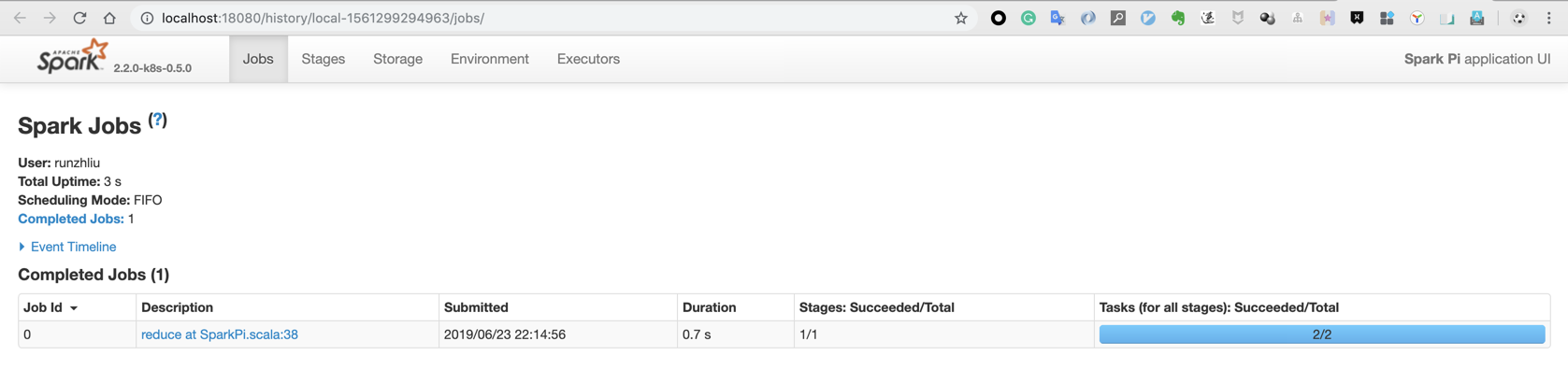
刚刚运行的 SparkPi 程序的 Job 在这里。
Docker化
本地环境总是很蛋疼的。属性 Docker 之后,我想不会有人再在本地跑 Spark,HDFS 之类的测试程序的了。具体说说如何用 Docker 来跑 Spark。
警告
本文最后更新于 2019年10月10日,文中内容可能已过时,请谨慎参考。